
ChatGPT (opens new window)和其他大型语言模型(LLMs) (opens new window)在理解和生成类似人类的文本方面取得了重大进展。然而,它们在保持准确性和相关性方面经常遇到困难,特别是在快速变化或专业领域。这是因为它们依赖于大型但固定的数据集,这些数据集很快就会过时。这就是向量数据库 (opens new window)的用武之地,它提供了一种使这些模型保持更新和具有上下文意识的方法。
向量数据库通过为包括ChatGPT在内的LLMs提供访问相关和最新信息的方式来解决这一挑战。通过集成向量数据库,这些模型可以检索和利用特定的、面向领域的数据,从而提高响应的准确性和上下文意识。
本文探讨了如何利用向量数据库来增强ChatGPT的性能。我们将探讨向量数据库强大的检索能力如何使ChatGPT能够更有效地处理专业任务和详细问题,使其成为用户更可靠和多功能的工具。
# 理解向量数据库
在讨论其集成之前,了解向量数据库是什么以及它们如何改变人工智能是至关重要的。
# 什么是向量数据库
向量数据库是一种特殊类型的数据库,用于处理名为向量 (opens new window)的复杂数据点,。向量类似于表示数据的数字列表,使得比较和查找相似性变得容易。向量数据库不像传统数据库那样将信息组织成行和列,而是将数据存储为这些数字列表。这使得它们非常擅长处理涉及查找模式和相似性的任务,例如推荐产品或识别相似的图像。
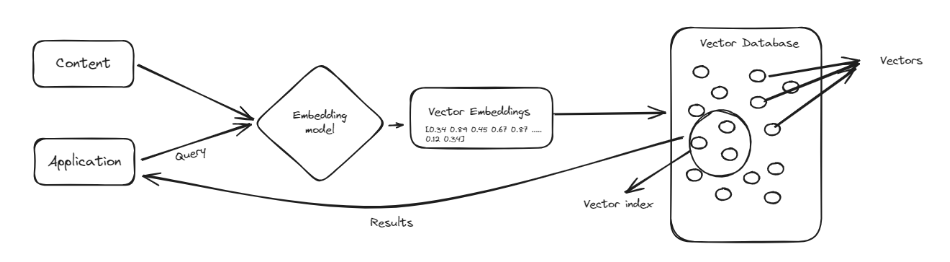
向量数据库的主要优势之一是它们能够快速搜索大量数据以找到相关信息。它们在机器学习和人工智能等领域特别有用,这些领域中理解数据点之间的关系至关重要。通过使用向量数据库,我们可以增强像ChatGPT这样的工具,使其在处理和检索信息方面更加智能和高效,从而实现更好和更准确的响应。
# 向量数据库与传统数据库的区别
在管理结构化记录和确保存储数据的完整性方面,传统关系数据库无与伦比;然而,与它们相比:
- 向量数据库在处理多维数据点方面更灵活。
- 向量数据库能够更快地处理大量信息。
- 基于相似性的检索方法在向量数据库上效果更好,因为它们在处理模式识别或相似性匹配期间的操作效率高,这对于AI应用非常重要。
# 向量数据库对ChatGPT的重要性
像ChatGPT这样的LLMs在自然语言处理和生成方面取得了显著进展。然而,这些模型也面临一些限制,可以通过集成向量数据库来解决这些限制。
- 知识幻觉:向量数据库将作为可靠的知识库,减少虚假信息。
- 没有长期记忆存储能力:通过高效存储相关数据,可以将其视为模型的另一个记忆。
- 上下文理解问题:向量表示允许对上下文和概念之间的关系进行细致的理解。
# 将ChatGPT与MyScale集成为AI人力资源助手
在本教程中,我们将逐步介绍如何将ChatGPT与MyScale (opens new window)(一个强大的向量数据库)集成,以创建一个能够全天候回答员工查询的AI人力资源助手。这个实际的示例将演示向量数据库如何通过提供最新的、领域特定的信息来增强ChatGPT。
# 第1步:设置环境
首先,我们需要通过安装必要的库来设置我们的环境。这些库包括langchain用于管理语言模型和文本处理,sentence-transformers用于创建嵌入向量,以及openai用于ChatGPT模型。
pip install langchain sentence-transformers openai
# 第2步:配置环境变量
我们需要配置环境变量以连接到MyScale和OpenAI API。这些变量包括MyScale的主机、端口、用户名和密码,以及OpenAI的API密钥。
import os
# 设置向量数据库连接
os.environ["MYSCALE_HOST"] = "your_host_name_here"
os.environ["MYSCALE_PORT"] = "port_number"
os.environ["MYSCALE_USERNAME"] = "your_user_name_here"
os.environ["MYSCALE_PASSWORD"] = "your_password_here"
# 设置OpenAI的API密钥
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
注意:如果您没有MyScaleDB (opens new window)账户,请访问MyScale网站注册 (opens new window)一个免费账户,并按照快速入门指南 (opens new window)进行操作。要使用OpenAI API,请在OpenAI网站 (opens new window)上创建一个账户并获取API密钥。
# 第3步:加载数据
我们加载员工手册PDF并将其拆分为可处理的页面。这涉及使用文档加载器。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
# 如果需要,跳过前几页
pages = pages[4:]
使用PyPDFLoader类可以高效地加载PDF文档,无缝处理文档加载过程。load_and_split()方法读取文档并将其拆分为单独的页面,使文本更易于处理。我们使用pages = pages[4:]来删除前四页,以排除不相关的信息,如封面或目录。
# 第4步:清理数据
现在,让我们清理从PDF中提取的文本,以删除不需要的字符、空格和格式。
import re
def clean_text(text):
# 删除所有换行符,并将多个换行符替换为一个空格
text = re.sub(r'\s*\n\s*', ' ', text)
# 删除所有多余的空格,并将它们替换为一个空格
text = re.sub(r'\s+', ' ', text)
# 删除所有行开头的数字(如'1 '、'2 '等)
text = re.sub(r'^\d+\s*', '', text)
# 删除任何剩余的不需要的空格或特殊字符
text = re.sub(r'[^A-Za-z0-9\s,.-]', '', text)
# 去除前导和尾随空格
text = text.strip()
return text
text = "\n".join([doc.page_content for doc in pages])
cleaned_text = clean_text(text)
clean_text函数处理和清理文本。它删除换行符、多余的空格、行开头的数字和任何剩余的不需要的字符,从而得到干净和标准化的文本。
# 第5步:拆分数据
下一步是将文本拆分成较小的、可处理的块,以便用于我们的AI应用程序。
from langchain.text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块的最大大小
chunk_overlap=300, # 块之间的重叠
length_function=len, # 计算长度的函数
is_separator_regex=False,
)
docs = text_splitter.create_documents([cleaned_text])
RecursiveCharacterTextSplitter类将文本按指定大小拆分为块,并具有重叠以确保连续性。这样可以将文本分解为易于处理的片段,同时不丢失上下文。
# 第6步:定义嵌入模型
我们使用OpenAIEmbeddings嵌入模型将文本块转换为向量表示。
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
OpenAIEmbeddings类初始化一个预训练的Transformer模型,用于为文本块创建嵌入(向量表示),捕捉文本的语义含义。
# 第7步:将数据添加到MyScale向量存储
现在,让我们将向量化的文本块添加到MyScale向量存储 (opens new window)中,以实现高效的检索。
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
MyScale.from_documents(docs, embeddings)方法将文本块的向量表示存储在MyScale向量数据库中,实现高效的相似性搜索。
# 第8步:执行相似性搜索
让我们对存储的向量执行相似性搜索,以测试我们的向量存储的工作情况。
output = docsearch.similarity_search("员工的汽油津贴是多少?", 3)
similarity_search方法在向量数据库中搜索与查询相似的向量,检索前六个匹配项。进行查询后,您将获得类似以下结果:
[Document(page_content='员工可以选择通过自愿公积金VPF对公积金进行额外的贡献。雇主的贡献是员工基本工资的12。2福利金根据1972年的退休金支付法,将按照Adino Telecom Ltd.的所有合格员工的每年连续服务的完成年数(超过5年)的15天工资的比率支付。工资的比率将是最后一次工资的比率。2医疗保险Alleligibleemployees将在Star Healthc laim Medical政策的保护下,为自己、配偶和子女提供最高1 lakh的保险。4ESIC所有合格员工都在1948年的ESI法的规定下受到保护。每月工资低于每月10,000卢比的员工可在ESI计划下获得保险。员工的贡献比率为工资的1.75雇主的贡献比率为工资的4.75。', metadata={'_dummy': 0}),
Document(page_content='ALLOTTED PER MONTHin Rs M5 M4 1500 M3 M2 1250 M1 M0 800 O1 O2 420 A1, A2 A3 300 Please note that no special approval will be given except to Business Managers who are required to make international calls. Please note that the above values are subject to change 437.3Conveyance Reimbursement Up to DM level Maximum of Rs. 1875 pm to be claimed at actuals Manager Level Maximum of Rs. 2,200 pm to be claimed at actuals Sr. Manager DGM level Maximum of Rs. 2,575 pm to be claimed at actual GM having car maximum Rs. 6 000 per month to be claimed at actua l. Car maintenance maximum Rs. 2,000 per month and Rs. 8000 per annum. The conveyance expenses will have to be kept at the above levels and no reimbursement will be allowed beyond the amount mentioned. In case of paid survey the conveyance will be at Rs. 5 ,000 pm. Please note that the above values are subject to change 447.4Internet Charges Rs. 300 pm for internet charges will be applicable only for Grade M5. 7.5Training policy', metadata={'_dummy': 0}),
Document(page_content='将在每年的Diwali期间发放。4.绩效激励员工有权根据他们全年的绩效获得绩效激励。激励金每年发放一次。5.医疗符合条件的员工将在Star Health保险政策计划的保护下。6.所有属于所得税范围的员工应在每个财年的9月之前提交他们的投资计划。7.所有的投资计划凭证需要在1月底之前提交。499.福利509.1公积金根据1952年的公积金法,所有员工都在规定范围内。员工的基本工资的12。员工可以选择通过自愿公积金VPF对公积金进行额外的贡献。雇主的贡献是员工基本工资的12。2退休金根据1972年的退休金支付法,将按照Adino Telecom的所有合格员工的每年连续服务的完成年数(超过5年)的15天工资的比率支付。工资的比率将是最后一次工资的比率。', metadata={'_dummy': 0})]
# 第9步:设置检索器
现在,让我们将这个向量存储从文档搜索引擎转变为检索器。它将被LLM链使用来获取相关信息。
retriever = docsearch.as_retriever()
as_retriever方法将向量存储转换为检索器对象,根据查询获取相关文档。
# 第10步:定义LLM和链
最后一步是定义LLM(ChatGPT)并设置一个基于检索的QA链。
from langchain_openai import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=False,
)
OpenAI类初始化ChatGPT模型,而RetrievalQA.from_chain_type设置了一个QA链,该链使用检索器获取相关文档,并使用语言模型生成答案。
# 第11步:查询链
我们查询QA链以从AI人力资源助手获取答案。
# 查询链
response1 = qa.run("津贴补贴是多少?")
print(response1)
qa.run(query)方法向QA链发送查询,该链检索相关文档并使用ChatGPT生成答案。然后打印查询的响应。
进行查询后,您将获得类似以下的响应:
"津贴补贴的金额因员工的等级和级别而异,从DM级别员工的每月1875卢比到GM级别员工的每月最高6000卢比。这些金额可能会有所变动。"
让我们再进行另一个查询:
response2 = qa.run("办公时间是多少?")
print(response2)
这个查询将返回类似以下的结果:
"办公时间是从上午9点到下午5点45分或上午9点30分到下午6点15分,某些员工可能有不同的时间表或班次。"
这就是通过将其与向量数据库集成来增强ChatGPT性能的方法。通过这样做,我们确保模型可以访问最新的、领域特定的信息,从而实现更准确和相关的响应。

# 为什么选择MyScale作为向量数据库
MyScale作为向量数据库的一个亮点在于其与SQL的完全兼容性 (opens new window),这简化了复杂的数据操作和语义搜索。开发人员可以使用熟悉的SQL查询来处理向量,无需学习新的工具。MyScale的高级向量索引算法和OLAP架构确保高性能和可扩展性,使其适用于高效管理大规模AI应用程序的数据。
MyScale的安全性和易于集成是其额外的优势。它运行在安全的AWS基础设施上,提供加密和访问控制等功能来保护数据。MyScale还支持广泛的监控工具 (opens new window),实时提供LLM应用程序性能和安全性的洞察。作为一个开源平台,MyScale鼓励创新和定制,使其成为各种AI项目的多功能选择。
# 结论
将ChatGPT等LLMs与向量数据库相结合,使开发人员能够在不重新训练模型的情况下构建强大的应用程序。这种设置使ChatGPT能够访问实时的、特定领域的信息,使其响应更准确和相关。
向量数据库在提高LLMs的响应质量和性能方面起着关键作用。它们确保模型可以访问最新和最相关的数据。MyScale在这方面表现出色,提供高效和可扩展的解决方案,使集成变得简单而有效。MyScale在速度和性能方面也超越了专门的向量数据库 (opens new window)。此外,新用户可以在其开发环境中获得500万个免费向量存储,使他们可以测试MyScale的功能并亲身体验其好处。
如果您想与我们进一步讨论,欢迎加入MyScale的Discord (opens new window)共享您的想法和反馈。



