
向量数据库正在兴起,其应用无处不在。它们具有超高的速度(想象一下在几分之一秒内搜索数十亿条记录),并且需要更少的资源(不需要任何GPU)。尽管如此,它们的性能出色,足以在公共卫生、金融和生物识别等领域使用。
现有许多向量数据库,其中MyScale是其中一个特殊的向量数据库,它是一种基于SQL的向量数据库。无论您是已经是向量数据库用户还是对它们还不熟悉,选择其中之一可能会很棘手;它取决于许多因素,如定价、可扩展性、某些特定功能的可用性、一些基准测试等等。为了帮助用户做出全面的选择,我们推出了这个系列的文章,比较不同的向量数据库 (opens new window)。在这个续集中,我们将比较MyScale和Weaviate。
# MyScale简介
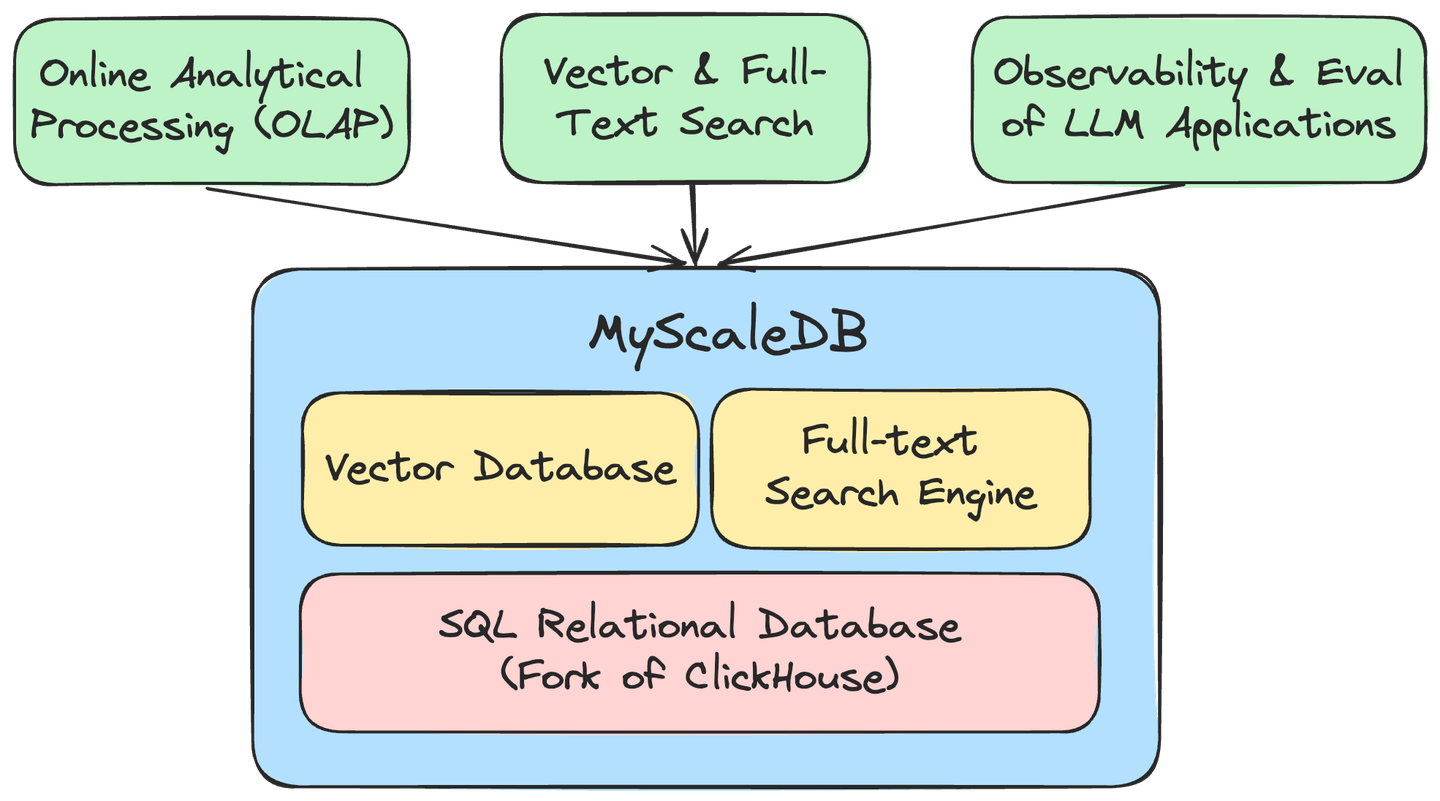
MyScale (opens new window)是一个开源的基于云的数据库,专为AI驱动的解决方案而设计。它基于ClickHouse和Tantivy构建,将SQL、向量数据库和全文搜索功能结合到一个平台上。MyScale支持完整的SQL,包括复杂查询,使其在大规模数据管理方面既可靠又可扩展。
针对AI应用进行了优化,MyScale可以高效处理结构化和向量化数据,实现强大的分析处理。它从ClickHouse继承了OLAP架构,确保在毫秒级内对数十亿个向量进行搜索。此外,MyScale非常易于访问,只需要使用SQL进行交互,简化了与现有系统的集成。
# Weaviate是什么
Weaviate是一个用Go编写的开源 (opens new window)向量数据库,旨在管理对象和向量。它针对机器学习和AI应用进行了高度优化,特别适用于需要快速向量搜索的应用。Weaviate提供免费和按需付费的服务,适用于各种项目。
该数据库在速度方面表现出色,可以在毫秒级内对数百万个数据点进行最近邻搜索。这种速度使其成为语义搜索、推荐系统和分类等任务的不错选择。Weaviate还可以轻松集成流行的机器学习模型,支持各种媒体类型,包括文本和图像,并提供可扩展性和云原生功能。
现在,我们将从不同方面开始比较这两个数据库,从托管开始。
# 托管
在托管像Weaviate或MyScale这样的向量数据库时,需要仔细考虑部署环境,即使在实验阶段也是如此。这些数据库可以在本地机器上自行托管,但通常更倾向于使用云原生托管,以实现可扩展性和易用性。云平台如AWS、Google Cloud或Kubernetes提供了基于工作负载的灵活扩展选项。
# Docker/本地部署
MyScale和Weaviate都是开源的,因此可以使用Docker在本地运行它们。这对于小型应用程序、某些基于隐私的应用程序或仅用于试验目的非常有帮助。您可以在本地运行MyScale:
docker run --name MyScale --net=host myscale/MyScale:1.6
对于Weaviate,您可以使用Docker compose:
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.27.0
# 云托管
尽管有这些基于Docker的解决方案,但用户更倾向于云托管服务的原因有很多:
- 更好的资源
- 优化的算法
- 可扩展性
Weaviate和MyScale都提供免费和付费的云解决方案,付费服务有两个选项:
- 容量优化(默认,更便宜)
- 性能优化(性能更好,更昂贵)
# 核心功能
现在让我们来比较这两个数据库的核心功能,每个都有其自身的优点。
# 查询语言和API支持
- 它们都支持不同语言的客户端,如Python、Node.JS、Go等。
- 它们都提供对GraphQL和REST API的支持。
Weaviate: 其最新版本还提供了对gRPC API的支持。此外,值得注意的是,Weaviate的新版Python和TypeScript客户端尚不稳定。
MyScale: MyScale的真正强大之处在于对SQL的支持。您可以使用传统的SQL与数据库进行交互和管理。
# 元数据支持
MyScale和Weaviate都支持元数据。MyScale通过其MSTG算法优化了过滤向量搜索,同时利用了ClickHouse的高级索引和并行处理能力。此外,在主要向量搜索之前,还采用了预过滤策略,以缩小数据集,提高性能和准确性。
TL;DR:
两者都支持元数据,而MyScale的元数据过滤由于ClickHouse的可扩展性,在处理较大数据集时性能不会下降。
# 支持的数据类型
MyScale和Weaviate都支持向量。它们还支持高级类型,如geoCoordinates。
Weaviate: 具有cross-reference类型,允许我们将不同的对象链接到另一个对象。
MyScale: 支持所有SQL数据类型。
例如,这是一个具有向量类型的表,用于存储文本嵌入,结合了基本数据类型(用于id和sentences)。
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
MyScale具有完整的SQL支持,因此我们可以编写相当复杂的查询,例如:
SELECT
myscale_movie.id,
myscale_movie.title,
myscale_rating.rating,
distance(
myscale_movie.embedding,
[0.00578, 0, ..., 0, 0.00984]
) AS dist
FROM
myscale_movie
INNER JOIN myscale_rating
ON myscale_rating.movieId = myscale_movie.id
WHERE
myscale_rating.rating > 4
ORDER BY
dist DESC
LIMIT 10;
TL;DR:
MyScale和Weaviate都支持向量和相应的数据类型。MyScale具有完整的SQL数据类型和SQL功能的明显优势。
# 可扩展性
虽然我们将在本博客的后半部分查看定价细节,但值得注意的是(在标准定价下),MyScale提供高达3.2亿个向量 (opens new window),而Weaviate的可扩展性有限,因为它不提供超过5000万个向量的解决方案 (opens new window)。这显示了Weaviate的一个严重限制,因为在数据库中拥有数百万个向量并不罕见。
# 索引
作为开源软件,两者都支持许多索引算法,如HNSW、FLAT和Dynamic。
Weaviate: 其索引功能最近才处于实验阶段。
MyScale: 不仅在Weaviate上,而且在所有流行的向量数据库上都支持多尺度树图(MSTG) (opens new window),这是一种将分层树聚类和基于图的搜索相结合的算法。它通过提供更快的搜索和减少资源消耗,优于现代算法。
# 过滤向量搜索和全文搜索
MyScale通过其MSTG算法优化了过滤向量搜索 (opens new window)。这种方法与ClickHouse的高级索引和并行处理能力相结合,使MyScale能够高效处理大型数据集。MyScale采用的预过滤策略在主要向量搜索之前缩小数据集,确保只处理最相关的数据,从而提高性能和准确性。
Weaviate也支持向量搜索,但其全文搜索的状态尚不清楚。另一方面,MyScale既支持全文搜索,又支持混合搜索 (opens new window)。
顺便说一句,MyScale (opens new window)和Weaviate都支持多向量搜索。
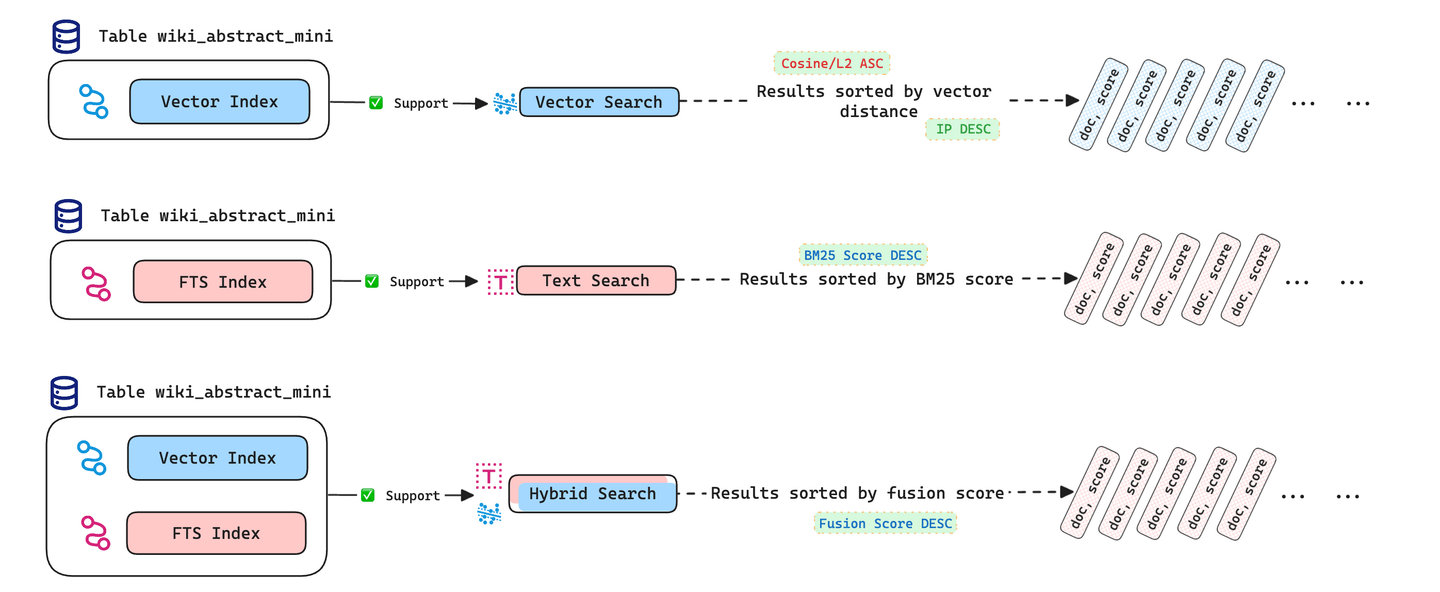
您可以在MyScale中使用HybridSearch()函数,它将全文搜索和向量搜索的结果结合起来,以提供更好的结果。上面的图像很好地解释了给定表wiki_abstract_mini的情况。
# 地理搜索
地理搜索对于不仅仅是地图和GIS应用程序,而且对于许多其他应用程序都非常重要。即使是像FoodPanda或一些杂货店这样的简单应用程序也可能需要它。然而,Weaviate不提供此功能。MyScale具有许多地理空间函数 (opens new window)来支持地理搜索。例如,greatCircleDistance()函数可以找到地球上两点之间的距离(将其视为流形):
SELECT greatCircleDistance(31.5, 74.33, 25.30, 51.54)
--Output: 2,553,475.8
在这里,我们使用这个函数来找到两个城市(拉合尔和多哈)之间的距离,使用了大圆公式 (opens new window)。返回的距离以米为单位,我们可以验证一下,它是正确的 (opens new window)。这里,几公里的差异是由于选择了城市的中心。
Weaviate也支持地理数据,虽然它尚未提供地理空间搜索功能,但它允许我们根据地理坐标进行过滤,以在特定区域内进行搜索。例如,此代码获取所需位置的坐标,并在500米的圆圈内进行搜索。
import weaviate
from weaviate.classes.query import Filter, GeoCoordinate
import os
client = weaviate.connect_to_local()
response = publications.query.fetch_objects(
filters=(
Filter
.by_property("headquartersGeoLocation")
.within_geo_range(
coordinate=GeoCoordinate(
latitude=30.5,
longitude=78.3
),
distance=500 # In meters
)
),
)
# LLM API集成
- MyScale和Weaviate都支持许多LLM API,如OpenAI、LLamaIndex、LangChain等。
- 它们都支持Cohere模型和DSPy进行自动提示。
以下是一个使用OpenAI嵌入将LangChain与MyScale集成的代码示例。
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import MyScale
loader = TextLoader("../../../../how_to/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
docsearch = MyScale.from_documents(docs, embeddings)
此代码接受一个文本文件,加载文档并使用OpenAI模型获取其嵌入。然后,它将数据上传到MyScale集群。如果索引不存在,它将创建索引;如果索引已存在,它将重用索引。
# LLM应用性能的可观察性
MyScale Telemetry (opens new window)是一种专门设计用于增强大型语言模型(LLM)的可观察性的工具,它通过捕获和存储来自应用程序的跟踪数据来实现这一目标,特别是那些使用LangChain构建的应用程序。这些跟踪数据存储在MyScaleDB(或ClickHouse)中,可以用于调试和性能优化。
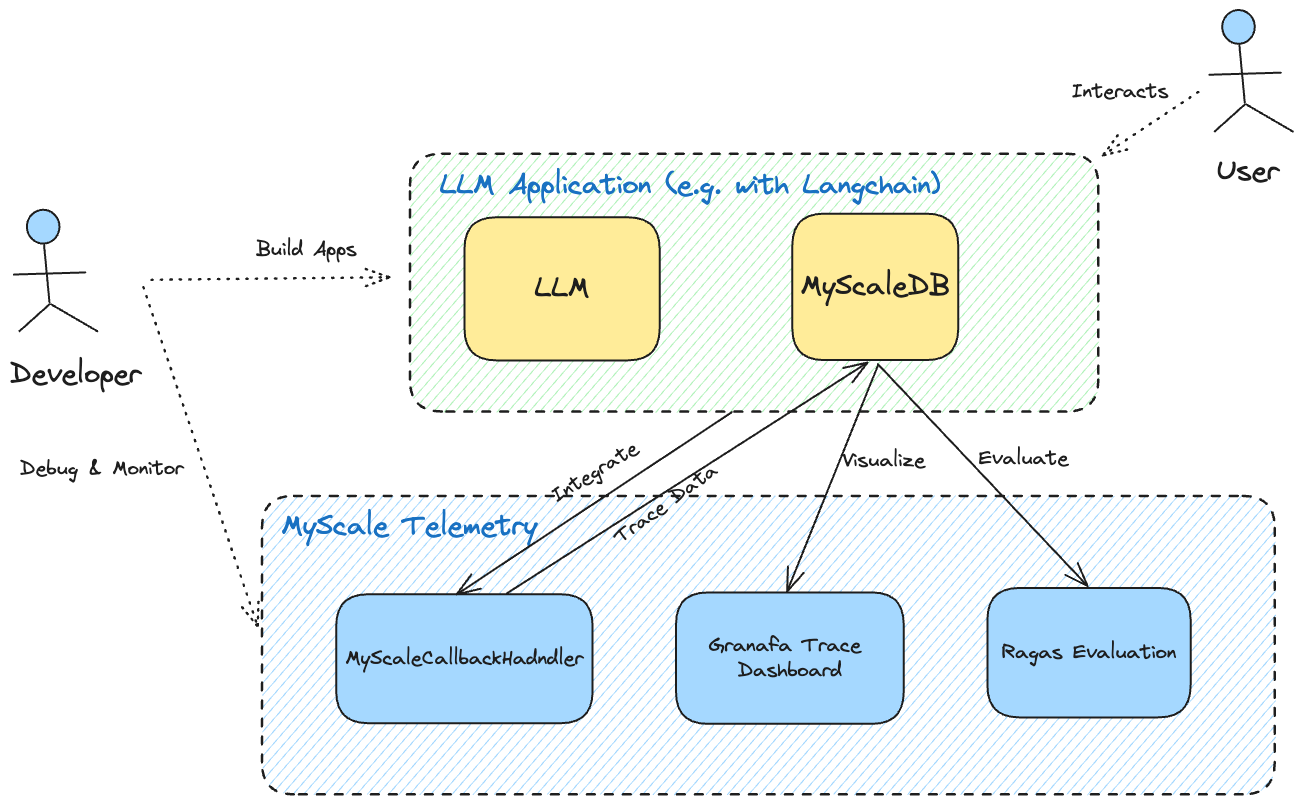
开发人员可以通过可视化仪表板(如Grafana Trace Dashboard)监视其LLM的行为,简化了实时诊断问题和评估应用程序性能的过程。这个工具使得以最小的性能开销深入了解LLM的运行时行为变得更加容易。
# 定价
最后,每个解决方案都受到两个最终参数的限制:价格和效率。对于效率,我们将很快对它们进行基准测试。首先,让我们经济地比较它们。
Weaviate和MyScale都提供免费和付费版本。我们在这里对两者进行简要(并且简明扼要)的比较。
# 免费版本
Weaviate的免费版本仅限于14天的沙盒。14天后,用户必须选择购买服务或放弃进一步使用。另一方面,MyScale提供免费存储空间,最多可存储500万个768维向量,并且没有时间限制(只要集群不处于7天的非活动状态)。
# 付费版本
免费版本对于实验是不错的,但最终您必须在专用服务器上部署解决方案,这需要资金。
MyScale有两个付费版本:
- 容量优化Pod
- 性能优化Pod
在容量优化Pod中,每个Pod可以获得1000万个向量,而性能优化设置提供更低的延迟(每个Pod 500万个向量)。
Weaviate提供3个选项:
- 无服务器云
- 企业云
- 自带云。
在下表中,我们将MyScale的两个版本(容量和性能优化)与Weaviate的无服务器云(最便宜的版本)进行了比较。其他两个版本的定价在其网站上没有公开,因此没有列出。Weaviate的一个严重限制是,它不支持超过5000万个向量。
| 容量 | Weaviate默认版(美元/小时) | Weaviate高性能版 | MyScale容量优化版(美元/小时) | Pods | MyScale性能优化版(美元/小时) | Pods |
|---|---|---|---|---|---|---|
| 1000万 | 1.021 | 2.95 | 0.09 | 1 | 0.33 | 2 |
| 2000万 | 2.042 | 5.9 | 0.19 | 2 | 0.67 | 4 |
| 4000万 | 4.084 | 11.8 | 0.38 | 4 | 1.33 | 8 |
| 8000万 | - | - | 0.76 | 8 | 2.67 | 16 |
| 1.6亿 | - | - | 1.51 | 16 | 5.33 | 32 |
| 3.2亿 | - | - | 3.02 | 32 | 10.66 | 64 |
正如我们所看到的,MyScale比默认或高性能的Weaviate要便宜得多。即使性能优化版的价格也比默认的Weaviate集群便宜3倍左右。
TL;DR:
就性价比而言,MyScale无与伦比。例如,MyScale托管的8000万个向量的成本比Weaviate托管的1000万个向量要低。此外,它还具有更好的可扩展性的优势。
# 基准测试
通过一些基本属性对两者进行基准测试是公平的比较。为了进行公正的比较,我们将使用Weaviate的最新版本对MyScale(使用MSTG)进行基准测试:
- Weaviate的旧版本
- Weaviate的新版本(v1.23.3)
# 吞吐量
每秒查询数是对向量数据库的一个很好的基本度量。我们可以清楚地看到MyScale(较深的酸橙绿色)在性能上超过了经典的Weaviate。Weaviate v1.23(深灰色)仅在8个或更多线程时才能超过MyScale。就平均精度而言,MyScale仍然明显优于Weaviate。
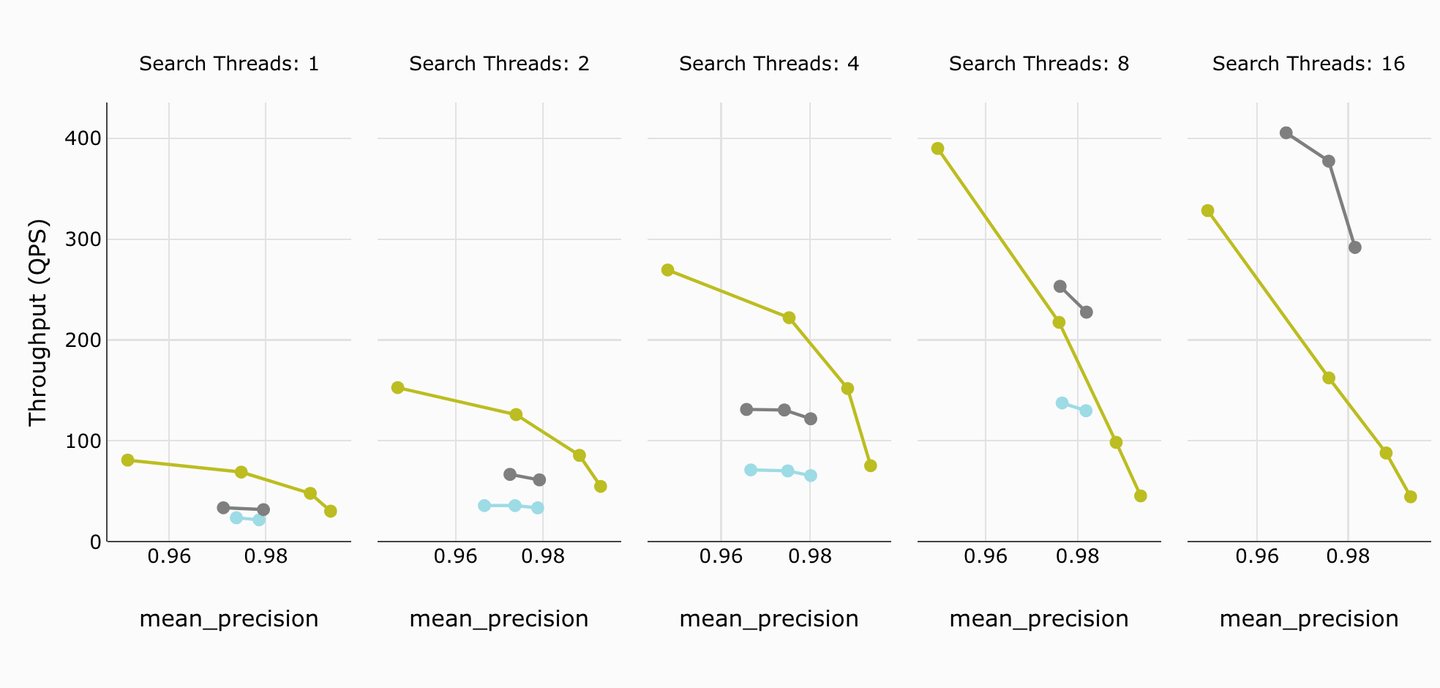
TL;DR:
MyScale在4个线程之前都优于Weaviate的旧版和新版。对于更多线程,Weaviate的最新版本性能优于MyScale,尽管MyScale的精度更高。
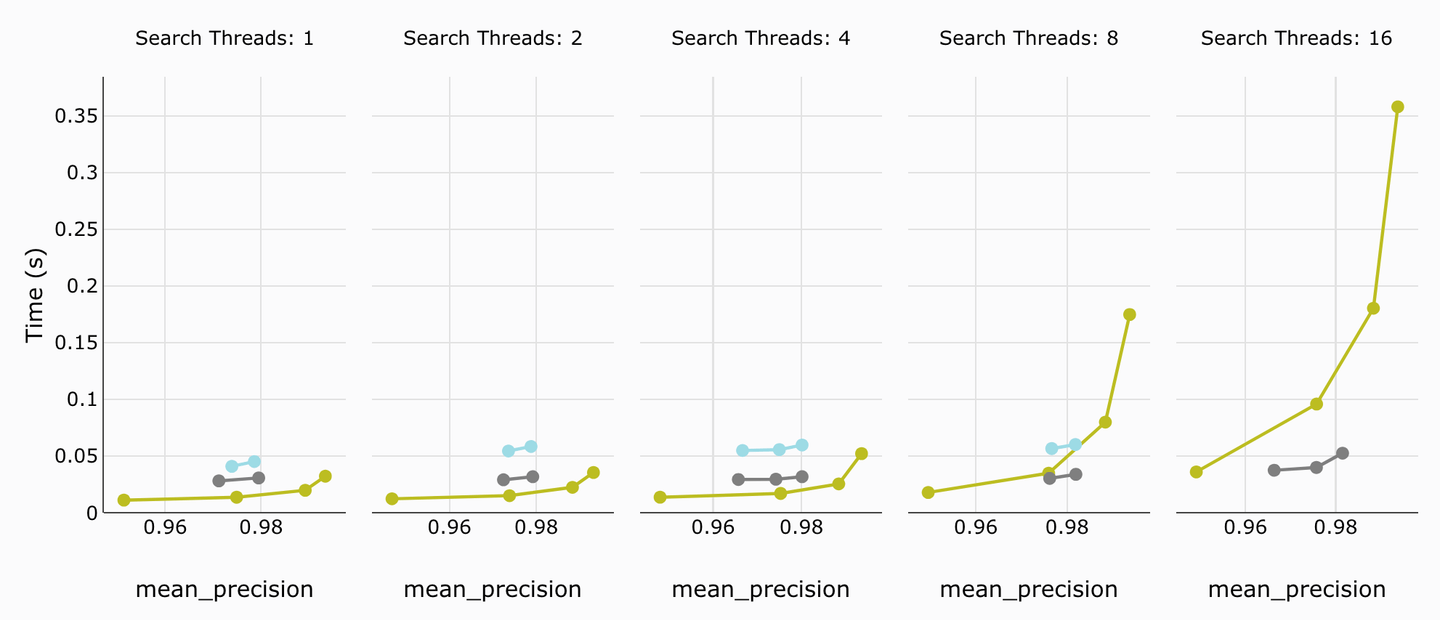
# 平均查询延迟
平均查询延迟可以定义为数据库平均返回查询结果所需的时间(时间越短越好)。MyScale在这方面明显优于Weaviate节点。只有在16个线程时,Weaviate才能超过MyScale。
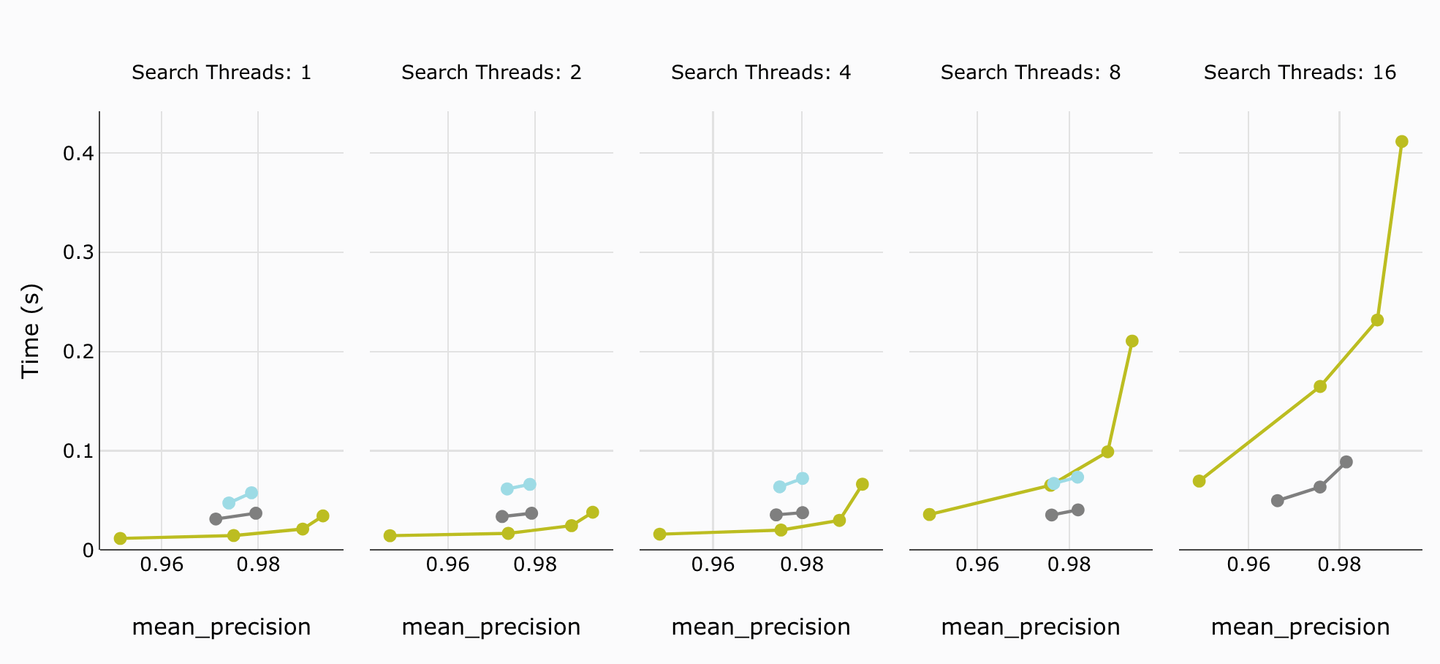
# P95延迟
在P95延迟方面,我们也有类似的结果。一旦线程超过8个,Weaviate的最新版本在延迟方面优于MyScale,而对于旧版本,MyScale在性能上明显优于Weaviate。
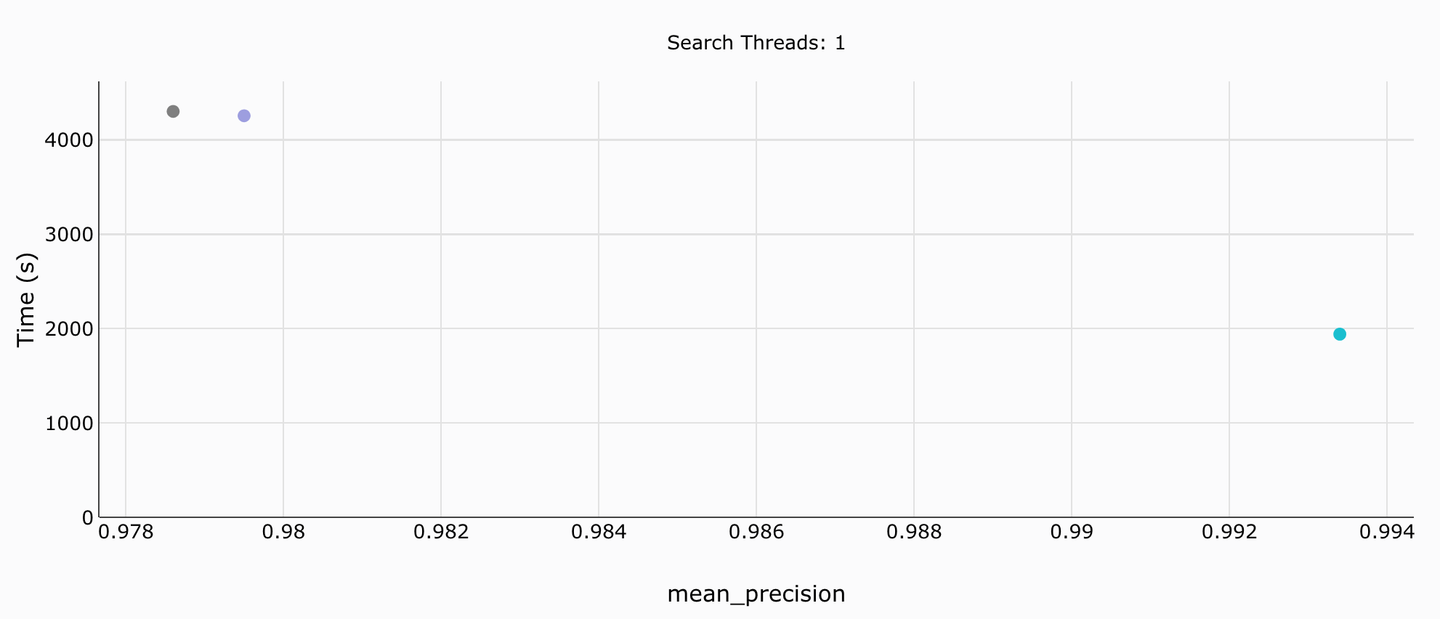
# 数据导入时间
此基准测试仅限于单个线程,因此我们在这里只显示一个图。MyScale(此处为海绿色)在上传和构建方面明显优于Weaviate。它们的平均精度之间的差距也非常明显(每个接近100%的小数都很重要)。
# 月度成本
即使是Weaviate的旧版本的月度成本也远高于MyScale的(在每个图中都位于最底部)。只有在8个或16个线程时,它们才会接近。
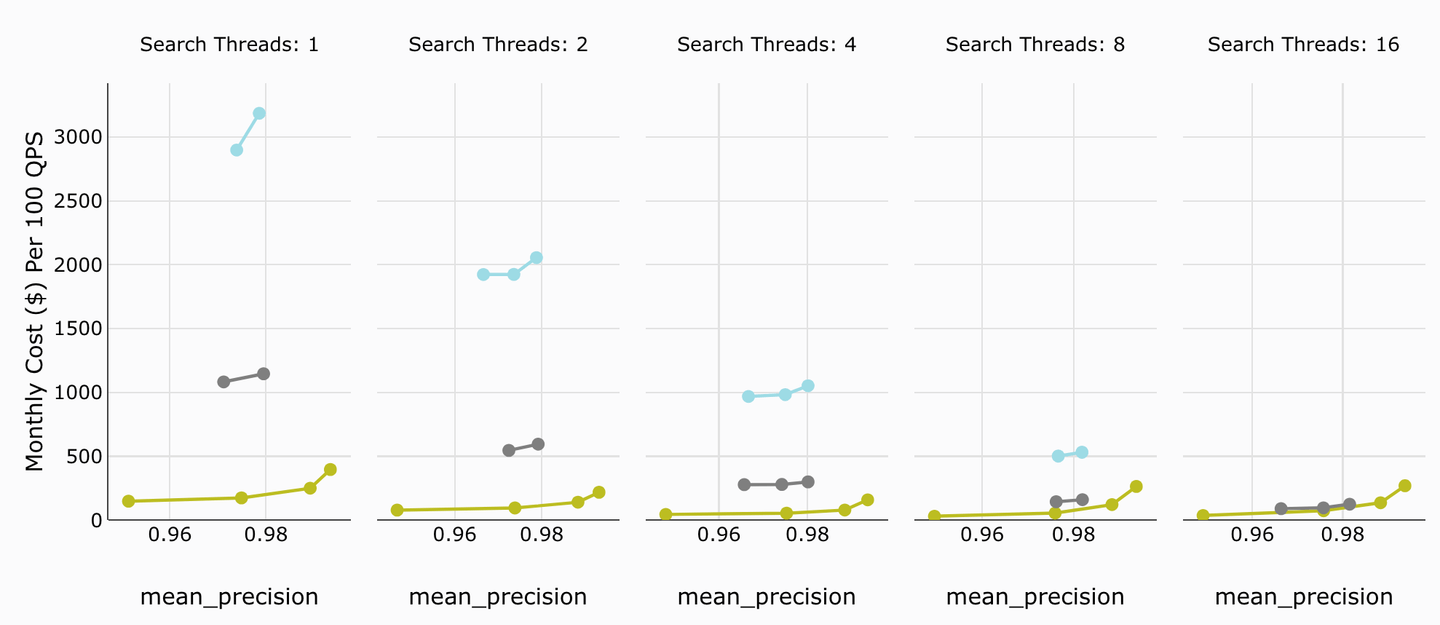
TL;DR:
MyScale通过提供每秒查询数的最低月度成本为您提供了最佳性价比。

# 结论
在迅速扩展的向量数据库领域,MyScale和Weaviate都提供了强大的解决方案,各自具有独特的优势。在两者之间做出选择需要仔细考虑项目特定的要求。MyScale在可扩展性、成本效益和延迟方面表现出色,使其成为需要管理大规模结构化和向量数据并从完整的SQL支持中受益的大规模应用的理想选择。MyScale能够高效处理复杂查询并与传统数据类型无缝集成,使其在许多企业环境中具有优势。
另一方面,Weaviate专为以AI为先的应用程序而构建,通过支持各种机器学习模型和嵌入向量,提供了灵活性。其强大的API、模块化架构和实时更新使其非常适合需要与非结构化数据进行动态交互的项目。虽然两个数据库都支持多种编程语言,但MyScale的完整SQL兼容性使其成为需要先进数据分析和快速向量搜索的项目的更全面的解决方案。



