
在这系列关于高级RAG管道的文章中,我们讨论了嵌入模型、索引方法和分块技术等其他组件如何构建高效系统的基础。现在,让我们探讨这个管道中一个非常重要的部分:向量搜索。
数据库的核心能力在于其搜索性能。从网页搜索到物体识别,应用场景数不胜数,因此,搜索的效率、多功能性和准确性至关重要。稍慢或不准确(或有限)的搜索可能是客户是否满意以及是否会再次光临的关键,而商家对此深知。
向量搜索在现代检索系统中至关重要。它支持语义搜索,并确保检索到的数据在语境上与查询匹配。向量搜索的核心思想是将每个项目表示为高维向量,其中每个维度对应于该项目的特征或属性。然后,可以通过计算它们的向量表示之间的距离来衡量两个项目之间的相似度。
# 向量索引简介
索引是向量搜索的关键驱动力。它使得搜索变得快速、高效且有意义。在对表进行搜索之前,必须先对其进行索引。这个过程将数据组织成一种方式,使得搜索能够快速检索到相关的结果。那么,让我们首先关注一下"索引 (opens new window)"。
添加索引时需要注意以下几点:
- 只能在向量列(
Array(Float32))或文本列上创建索引。 - 对于向量列,必须事先指定数组的最大长度。这确保了数据结构的一致性,并有助于索引高效工作。
- 索引主要用于相似度搜索,这意味着在创建索引时需要定义相似度度量。例如,您可能会选择
Cosine相似度,这是比较向量的常见度量之一。
索引是高效向量搜索的基础,因为它们显著减少了找到正确数据所需的时间和计算工作量。选择合适的索引策略并理解这些考虑因素,可以在系统性能上产生重要的影响。
# 示例
在MyScale (opens new window)中添加索引就像我们为任何SQL表添加索引一样。作为示例,我们定义一个表并在那里添加一个向量列。
CREATE TABLE test_float_vector
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ENGINE = MergeTree
ORDER BY id
如您所见,我们已经添加了最大长度约束,因为在添加索引之前,这是必需的。
ALTER TABLE default.test_float_vector
ADD VECTOR INDEX data_index data
TYPE MSTG ('metric_type=Cosine');
使用与传统关系数据库查询相同的SQL,我们可以获取与搜索词("Levin提出的解决农民问题的方案是什么?")最相关的文档。搜索短语需要先转换为嵌入。我们可以使用任何嵌入模型或服务来完成此操作。在获得嵌入(在input_embedding中)后,我们可以获取最相关的文档。

注意:
MyScale还提供了EMBEDTEXT()函数,可以直接使用于Python(或其他)接口和SQL中。
# 索引算法
上述语法并不是唯一的,但向量索引 (opens new window)在幕后工作方式有所不同。通常,它采用聚类技术,并随后使用某些图或树结构来加速遍历。选择合适的索引算法对于搜索效率至关重要,以下是一些常见的索引算法:
局部敏感哈希(LSH):
局部敏感哈希(Locality-Sensitive Hashing, LSH)使用特殊的哈希函数将相似的数据点分到同一个桶中。这个过程确保了相互接近的嵌入或向量更有可能在同一个哈希表中碰撞。它允许在高维空间中进行更快的搜索,非常适合近似最近邻任务。倒排文件(IVF) (opens new window):
倒排文件索引(Inverted File Indexing, IVF)通过将向量分组到多个簇中实现。当提供查询向量时,系统会计算查询向量与所有簇中心的距离。然后在最接近查询的簇中进行搜索。然而,由于该搜索依赖于簇中心(类似于k近邻算法),一个潜在的问题是其他簇中更接近的向量可能会被遗漏。此外,在某些情况下,为了获得更好的结果,可能需要同时搜索多个簇。
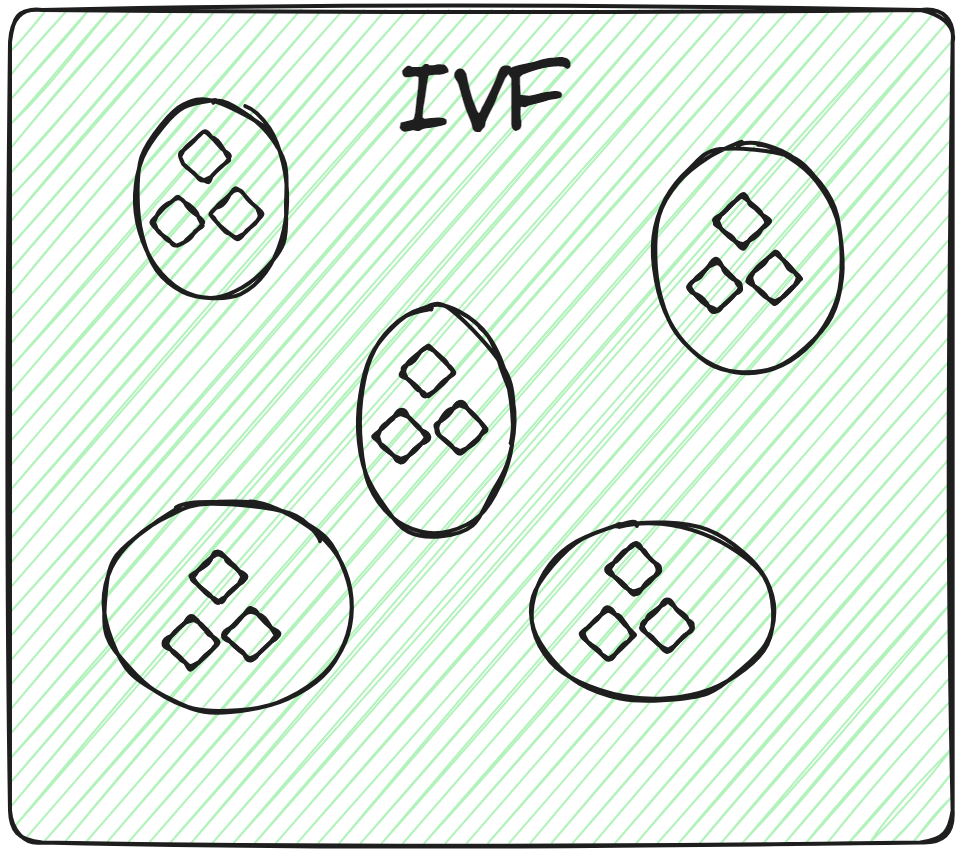
IVF还有几种变体,例如IVF-Flat (opens new window)和IVF-PQ (opens new window),它们在性能和存储方面提供了不同的权衡。
注意:
在向量数据库快速增长到数百万个向量的背景下,选择合适的索引算法变得尤为重要,因此每一秒的节省都非常宝贵。
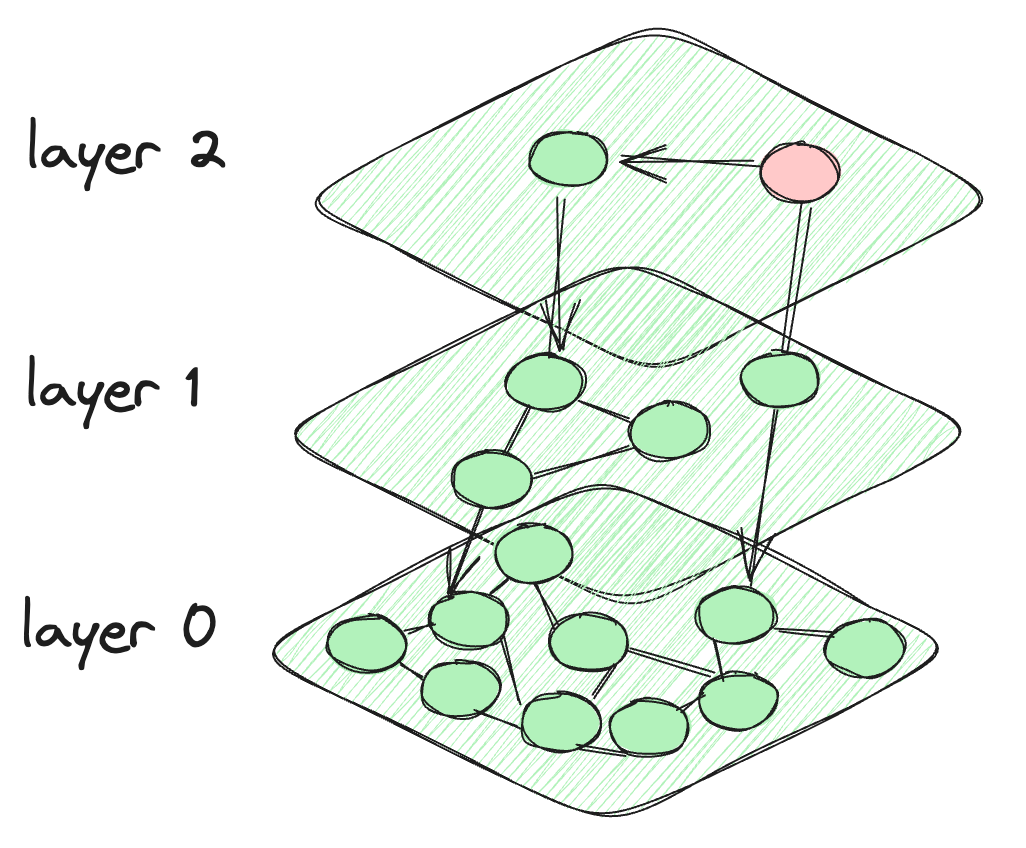
- 层次可导航小世界(HNSW) (opens new window):
HNSW通过构建图层的方式工作,每一层的节点数逐渐减少(即最顶层的节点最少)。这种分层方式意味着不需要搜索太多的节点,因此速度非常快。但在添加新向量时,重新生成图的过程可能非常耗时。
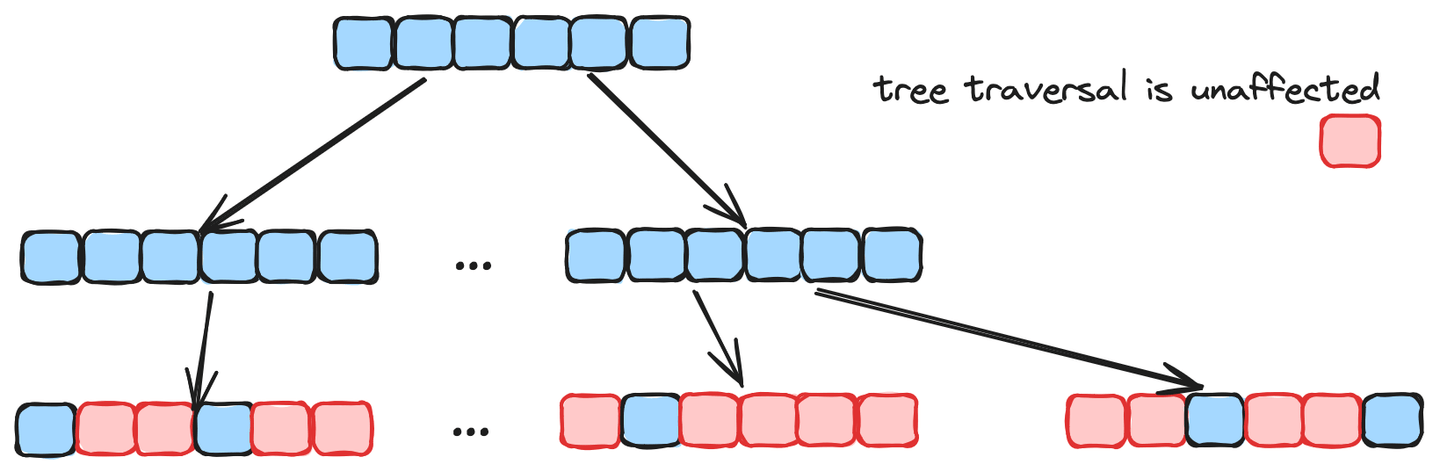
- 多尺度树图(MSTG) (opens new window):
HNSW和IVF都非常优秀,但在扩展到更大数据集时会出现性能问题。图搜索在初始收敛时表现出色,但在过滤搜索时较弱,而树搜索在过滤搜索时表现良好但较慢。MSTG结合了层次图和树的优点,从而实现了两者的结合。
总结如下表,供未来快速参考:
| 编号 | 算法 | 优势 | 改进空间 | 适用场景 |
|---|---|---|---|---|
| 1 | LSH | 适合高维数据;支持并行化 | 内存占用高;速度较慢 | 高维稀疏数据 |
| 2 | IVF | 适合小型和中等数据集 | 相邻簇可能导致遗漏 | 可区分簇的数据集 |
| 3 | HNSW | 快速 | 添加新条目时资源密集;可扩展性有限 | 通用场景 |
| 4 | MSTG | 快速;可扩展;高精度 | 尚新且不够成熟 | 通用场景 |
# 基础向量搜索
向量搜索是一种高级的数据检索技术,重点是匹配搜索查询和数据条目之间的上下文含义,而不仅仅是简单的文本匹配。要实现这一技术,首先需要将搜索查询和数据集中某一特定列转换为数值表示形式,即向量嵌入。
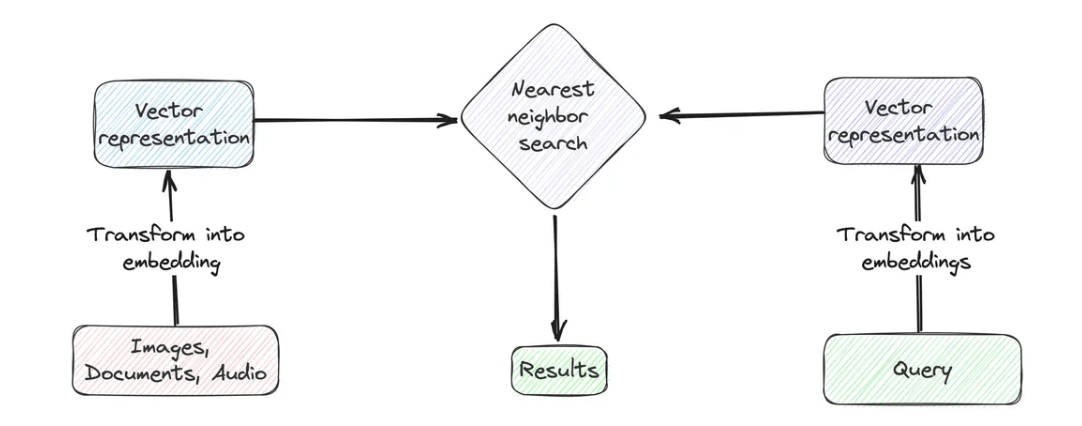
接下来,计算查询向量与数据库中向量嵌入之间的距离(如余弦相似度或欧几里得距离)。然后,根据这些计算的距离确定最接近或最相似的条目。最后,返回与查询向量距离最小的前k个结果。
注意:
语义搜索在向量搜索的基础定义上进一步发展,根据文本的含义而非确切的术语返回更相关的结果。不过,在实际应用中,向量搜索和语义搜索常常互换使用。
# 全文搜索
传统SQL搜索甚至正则表达式在处理确切术语或特定模式的比较时局限性较大。以下示例说明了这一点。我们使用SQL语法查找与“Thanksgiving for vegans”相关的文档。
| AND条件 | OR条件 |
|---|---|
SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
AND body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
| SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
OR body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
|
使用AND条件显然不会产生任何结果,而使用OR操作符则扩大了范围,返回包含“Thanksgiving”或“vegans”的文档。尽管这种方法能检索结果,但并非所有文档都与两个术语高度相关。

# 传统SQL搜索的局限性
传统SQL搜索非常僵化,无法处理语义相似性或措辞变化。例如,SQL将“doctor applying anesthesia”和“doctor apply anesthesia”视为完全不同的短语,因此经常忽略相似的匹配。
# 全文搜索的改进
在前一种情况下,我们基于确切的短语进行搜索,而在后一种情况下,搜索是通过关键字完成的。全文搜索支持这两种方法,允许根据用户偏好进行灵活选择。与传统SQL搜索的僵化不同,全文搜索能够容忍一定程度的文本变化。
# 工作原理
全文搜索的索引构建分为以下几个步骤:
- 分词(Tokenization):分词用于将文本分解为更小的部分。在单词分词中,文本被分解为单词;在句子或字符分词中,文本分别在句子和字符级别被分割。
- 词干提取/词形还原(Lemmatization/Stemming):词干提取和词形还原将单词分解为其“原始”形式。例如,“playing”将被简化为“play”,“children”将被简化为“child”,依此类推。
- 停用词移除(Stopwords Removal):像冠词或介词这样的单词包含的信息较少,可以通过此选项省略。默认的“英文”停用词过滤器不仅专注于移除冠词和介词,还会移除一些其他单词,如“when”、“ourselves”、“my”、“doesn’t”、“not”等。
- 索引构建:一旦文本完成预处理,就会存储在倒排索引中。
完成索引后,即可应用搜索功能。
# 评分与排序:BM25
BM25(最佳匹配25)是一种非常常用的算法。它的工作方式类似于向量搜索为相似性排序嵌入向量(或一般向量)。BM25是TF-IDF的一种改进形式,基于三个因素:词频(term frequency)、逆文档频率(奖励罕见术语)以及文档长度归一化。
# 示例
可以通过指定类型为fts简单地添加全文搜索索引,同时还可选择是否启用词形还原或词干提取以及停用词过滤器。
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx body
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
如您所见,它会根据查询的相似性对文档/文本样本进行排名。
SELECT
id,
title,
body,
TextSearch(body, 'thanksgiving for vegans') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;

# 多模态搜索
混合搜索为我们提供了全文搜索和向量搜索的结合,而多模态搜索更进一步,使得跨不同类型的数据(如图像、视频、音频和文本)进行搜索成为可能。
这一概念基于对比学习 (opens new window),多模态搜索的工作机制如下:
- 一个统一的模型(如CLIP(对比语言-图像预训练) (opens new window))处理各种数据类型(如图像或文本),并将它们转换为嵌入向量。
- 这些嵌入被映射到一个共享的向量空间,使得不同数据类型之间可以进行比较。
- 无论数据的原始形式如何,与查询嵌入最接近的嵌入将被返回。
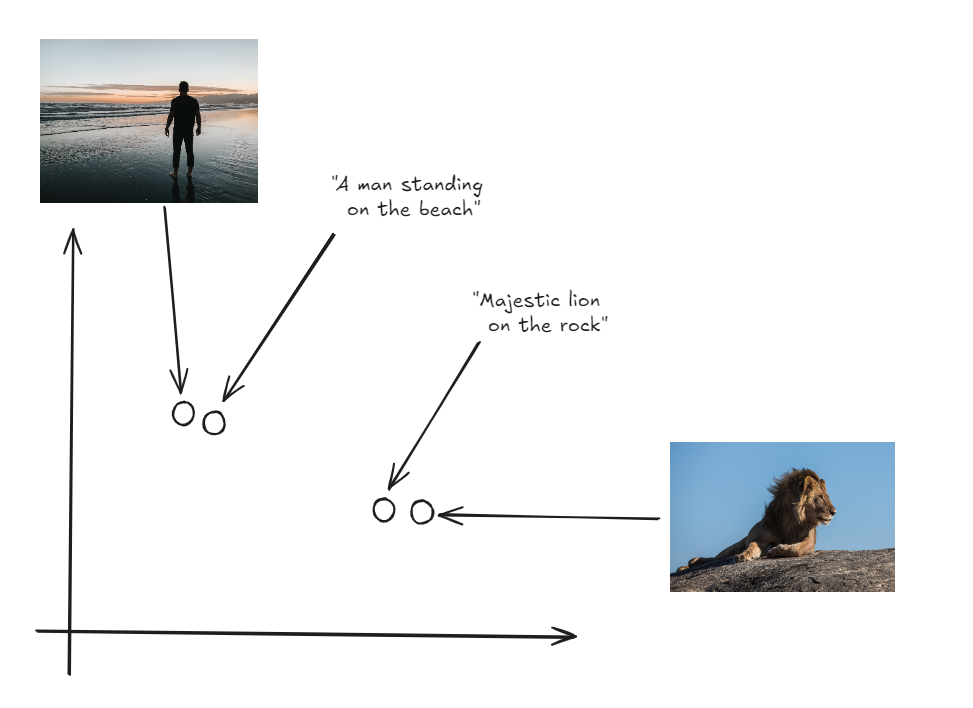
这种方法使我们能够基于单一查询检索多样化且相关的结果——无论是图像、文本、音频还是视频。例如,您可以通过提供文本描述搜索图像 (opens new window),或者通过一个音频片段找到视频。
通过将所有数据类型对齐到一个向量空间,多模态搜索无需整合来自不同模型的单独结果。这也展示了向量数据库的强大和灵活性,使得从多种类型的来源中无缝检索数据成为可能。
# 结论
向量数据库彻底改变了数据存储方式,不仅提高了速度,还在人工智能和大数据分析等不同领域提供了巨大的实用性。这项技术的核心在于其搜索能力。
MyScale 提供了三种类型的搜索:向量搜索 (opens new window)、全文搜索 (opens new window)和混合搜索 (opens new window)。通过覆盖索引算法并提供这些多样化的搜索功能,MyScale 使用户能够解决跨不同行业和用例的广泛数据检索挑战。我们希望本文中提供的示例能帮助您更好地理解这些搜索功能,并有效利用它们。



