
向量数据库在数十亿条记录中存储的相似对象上提供了快速检索。但是,您可能还对搜索与特定条件匹配的相关对象感兴趣,这称为过滤向量搜索。借助 MyScale (opens new window) 的帮助,您可以将过滤向量搜索提升到一个新的水平。
大多数向量索引或向量存储作为专用索引服务工作。它们支持 MongoDB 查询和投影运算符 (opens new window)的部分过滤向量搜索实现,您可以输入条件的字典。
不同的实现支持的数据类型和比较器不同,但大多数接口仅支持字符串、整数的相等和基本值比较。与数据库不同,这些向量索引并不设计用于处理复杂的数据类型和条件。因此,您需要一个外部数据库解决方案来存储这些数据,但不能使用这些数据执行过滤向量搜索。这个解决方案虽然可行,但很复杂且有限制。
实际上,应该有一个更好的解决方案。向量搜索可以与数据库集成,使其比现在更强大。MyScale 可以同时处理带有复杂条件和数据类型的过滤向量搜索,使用标准的 WHERE 子句。
# 前过滤和后过滤
过滤向量搜索实现可以分为两种类型:
- 前过滤向量搜索
- 后过滤向量搜索
例如:
假设您有一个包含用户 Jack、Jan 和 John 的聊天记录的表,并且您想使用过滤向量搜索查询来检索与给定查询向量相似的 Jack 的聊天记录。
NOTE
每条记录都有一个用户标记和特征向量,为简单起见,我们将向量转换为数字。
下图描述了 NoSQL 和 SQL 查询检索 Jack 的聊天记录:
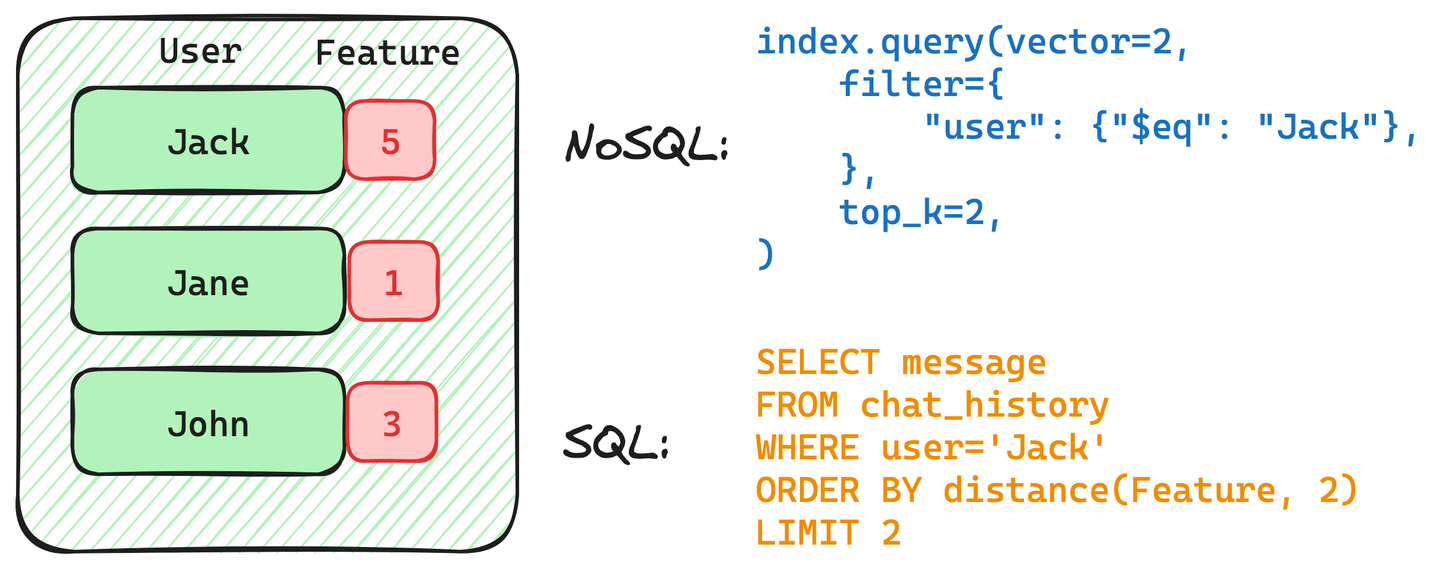
这两个查询都包含对用户 Jack 的过滤器。但是,这个过滤器的结构可能因实现而异。
1. 前过滤向量搜索: 对于前过滤向量搜索,引擎将首先扫描数据,并仅保留与给定过滤条件匹配的记录。完成此扫描后,引擎将在前过滤的候选记录上执行向量搜索。
2. 后过滤向量搜索: 另一方面,后过滤向量搜索将首先执行向量搜索,然后根据给定的过滤条件对这些结果进行过滤。
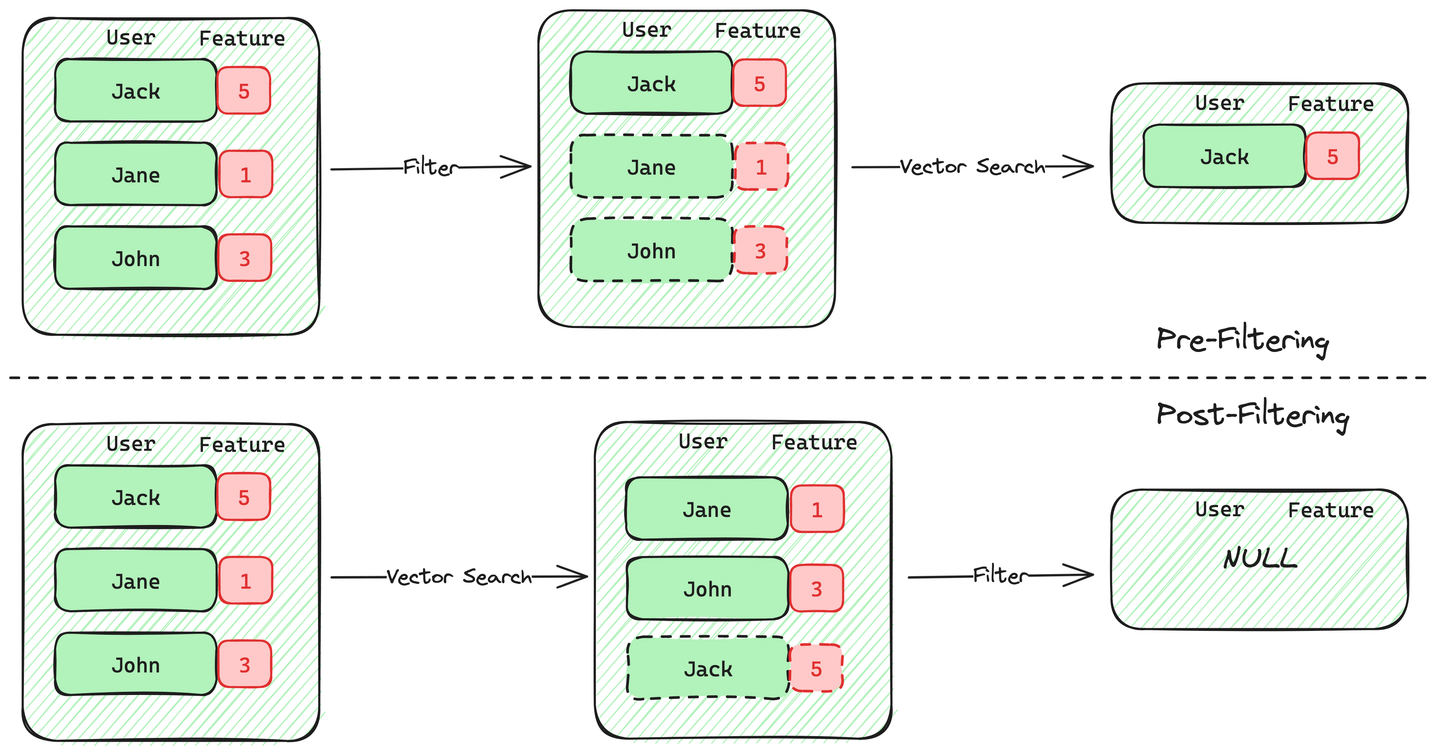
在这两种方法之间,前过滤优于后过滤,准确性符合我们对过滤向量搜索的期望。大多数向量数据库支持带有向量搜索的前过滤。然而,这种前过滤并非免费,增加了计算量并拖慢了过滤向量搜索的性能。大多数实现都受到性能或过滤器限制的影响,例如数据存储和支持的比较器限制。
MyScale 使用从ClickHouse MergeTree 引擎 (opens new window)改编的基于列的存储引擎 (opens new window),在常规过滤器上超快,显著提高了第一阶段过滤,并使过滤向量搜索比其他实现更快。此外,您可以使用简单的 SQLWHERE子句在表中的任何列上定义过滤器。
# MyScale 中 WHERE 子句的用途
由于 MyScale 是在 ClickHouse (opens new window) 之上开发的,它提供与 ClickHouse 完全相同的功能。
例如:
| 方法 | 其他 | MyScale |
|---|---|---|
| eq / neq | ✅ | ✅ |
| ge / gt / lt / le | ✅ | ✅ |
| include / exclude | ✅ | ✅ |
带有字符串模式匹配 LIKE | ❌ | ✅ |
| 时间戳/地理数据/JSON | ❌ | ✅ |
| 带有函数 | ❌ | ✅ |
| 带有arrayFunction (opens new window) | ❌ | ✅ |
| 带有子查询 | ❌ | ✅ |
让我们看一些突出 MyScale 的 WHERE 子句能够做什么的示例。
NOTE
您可以在我们的 Colab 或 GitHub 空间中找到这些示例的代码。
![]()
![]()
NOTE
有关数据类型和函数的更多信息,请参阅 ClickHouse 的官方文档 (opens new window)。
# 常见值比较:=,!=,>,<,>=,<=
大多数向量索引解决方案支持对字符串或数字进行这些操作。在 MyScale 中,您可以使用以下方式编写值比较:
WHERE column = value
其中,column 可以是表中的任何列名,operation 可以是=,!=,>,<,>=,<=中的任何一个。
NOTE
列类型和值必须相同。
如果您有多个条件要添加到 WHERE 子句中,请使用逻辑运算符如 AND 将它们连接起来:
WHERE column_1 = value_1 AND column_2 >= value_2
# 常见集合运算符:包含,排除
MyScale 还支持集合操作,如 IN 和 NOT IN:
WHERE column IN (value_1, value_2, ...)
当您想选择一组行时,这很有用。类似地,您可以使用逻辑运算符将这些集合运算符与其他条件连接起来。
# 数组运算符
您可以使用 has 函数检查元素是否在数组中:
WHERE has(column, value_1)
# 字符串模式匹配
您可以使用关键字 LIKE 在 MyScale 中进行字符串模式匹配:
WHERE column_1 LIKE '%value%'
此条件匹配在 column_1 中包含 value 的值。这种字符串模式匹配运算符是 MySQL 提供的众多运算符之一。其他运算符包括:NOT LIKE,使用正则表达式的 match 和 ngramSearch。
NOTE
有关 LIKE 运算符的更多信息,请参阅 ClickHouse 的官方文档 (opens new window)。
# 日期时间比较
MyScale 还包括一个日期时间比较函数:
WHERE dateDiff('hour', column_datetime, toDateTime('2018-01-02 23:00:00')) >= 25;
这个 WHERE 子句指的是任何 column_datetime 晚于给定日期时间超过 25 小时的行。此函数还支持秒、分钟、天和月。
NOTE
有关更多信息,请参阅这里 (opens new window)。
# 地理数据比较
MyScale 可以处理 H3 Index (opens new window) 和 S2 Geometry (opens new window),这是用于路径规划和几何分析的强大工具。
例如,使用 H3 Index,您可以使用六边形的面积来过滤给定区域内的地理数据:
WHERE h3CellAreaM2(column_h3) > 1000
您还可以添加到特定 H3 Index 的距离:
WHERE h3Distance(column_h3, value_h3) > 10
# JSON 列中的任意对象
MyScale 允许您将 JSON 作为对象存储,并根据其属性进行过滤。
您可以使用 JSON 数据类型将 JSON 字符串导入表中,并使用以下 WHERE 子句过滤结果:
WHERE column_json.attr_1 = value_1
您还可以按如下方式对嵌套属性进行过滤:
WHERE column_json.attr_1.attr_2 = value_1
尽管这是一个实验性功能 (opens new window),但它非常强大。我们在我们的LangChain (opens new window)和LlamaIndex (opens new window)向量存储实现中使用了这些对象。
# 值函数
MyScale 包括许多列数据处理函数,您可以在 WHERE 子句中使用这些函数,例如:
WHERE abs(column_1) > 5
您可以在 WHERE 子句中包含多个列:
WHERE column_1 + column_2 + column_3 > 10
# 数组函数
数组函数非常强大,特别是在我们的向量搜索中。在我们的文档 (opens new window)中,我们介绍了 MyScale 中用于最终 logit 计算和梯度计算的数组函数,用于我们的 few-shot 分类器。
ClickHouse 在数组函数方面有很好的文档 (opens new window)。
NOTE
如果您仍然需要关于 MyScale 中的数组函数的帮助,请加入我们的 discord (opens new window) 并提问。
# 子查询支持
子查询是查询中的查询。您还可以使用另一个 SELECT 查询编写带有 WHERE 子句的 WHERE 子句,如下所示:
WHERE column_1 IN (SELECT ... FROM another_table WHERE ...)

# 过滤向量搜索性能
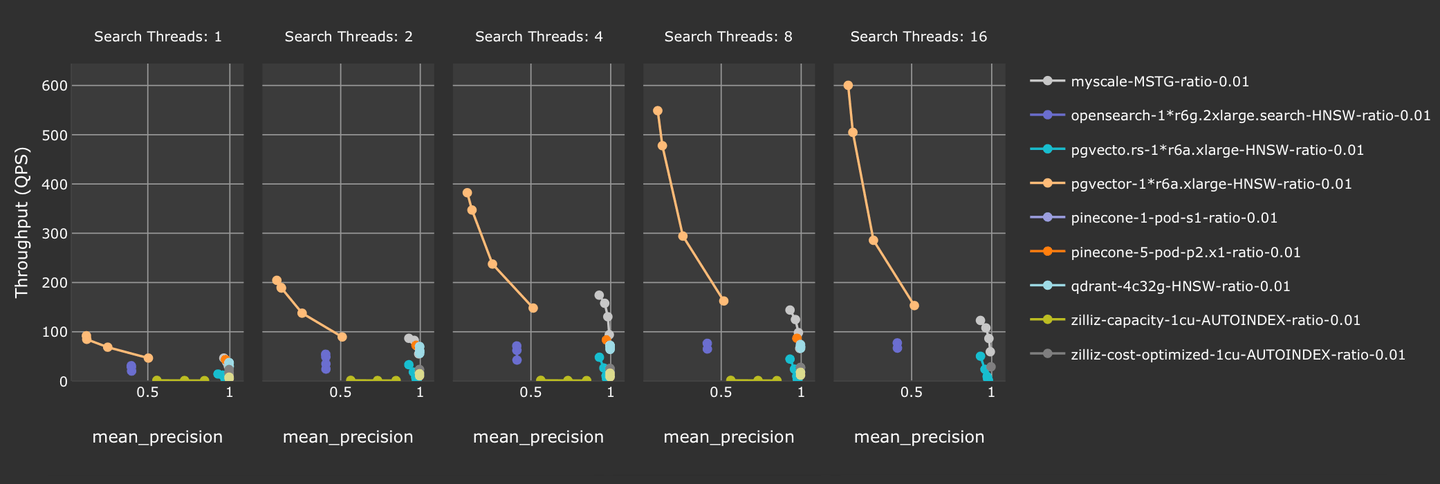
我们在 vector-db-benchmark (opens new window) 中调查了过滤向量搜索性能。我们使用了laion-768-5m-ip-probability,其中在查询期间添加了一个随机浮点数作为其过滤标记。我们还对 MyScale 进行了与其他流行的向量数据库解决方案的测试。如下图所示,MyScale 在准确性和吞吐量方面超过了大多数其他向量数据库解决方案。
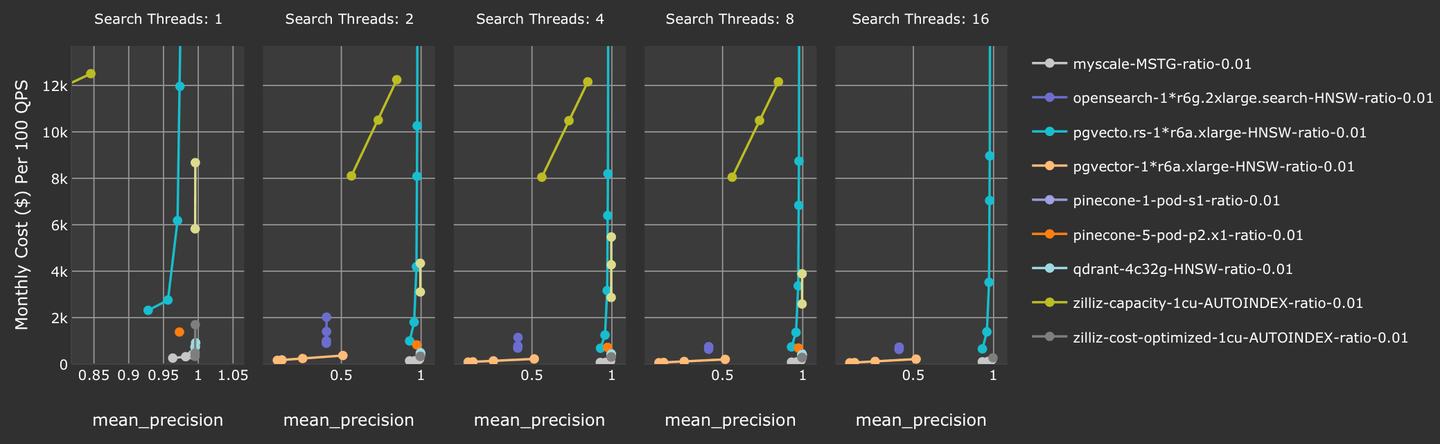
此外,当准确性>=90% 时,MyScale 实现了所有经过测试的向量数据库中最佳的成本效益。与其他 SQL 集成的向量数据库(如 pgvector 和 pgvector.rs)相比,MyScale 是唯一一个实现了生产就绪的准确性和吞吐量的 SQL 和向量集成数据库。
NOTE
有关更多信息,请参阅以下博客比较 pgvector 和 MyScale (opens new window)。
总之,MyScale 在更低的成本下提供了更高的准确性和吞吐量。在我们的产品线中的 s1 pod 中,我们还支持 500 万个向量,具有更多的数据类型和函数,对所有注册用户免费开放。
# 结论
过滤搜索是向量数据库中常见的一种查询类型,它允许您根据特定的条件或过滤器搜索相似的向量或数据点,特别是在处理可以表示为向量的数据时,如文本和图像嵌入或其他结构化数据。
MyScale 将 SQL 的强大功能嵌入到 AI 技术中,过滤搜索就是一个例子,为向量数据库提供了更复杂和灵活的查询能力。通过结合 AI 和 SQL,您可以执行复杂的数据操作和搜索,从而更轻松地提取有价值的见解,发现模式并执行不同的分析任务。
如果您对 SQL 如何提升您的 AI 应用程序感兴趣,请立即加入我们的 discord (opens new window) 或 X (opens new window)。



