
# 物体检测之旅
之前的教程演示了MyScale数据库的一些基本用法,比如插入和查询Top-K非结构化向量。而这个演示将尝试涵盖MyScale中更高级的功能。
MyScale旨在为SQL中的大规模向量搜索提供高性能支持。我们引入了COCO数据集 (opens new window)作为我们的数据源,以使本教程更加实用。该数据集包含超过28万张图像和约130万个标注对象。提取和查询对象级别的信息需要对图像有更细粒度的理解。此外,由于对象的数量远远大于图像的数量,特别是对于像COCO这样的数据集,这个任务变得更加庞大和困难。
搜索对象是一项复杂的任务,而在数十亿个对象中进行搜索则更具挑战性。但它比图像级别的搜索有更多的应用。例如,对象级别的理解可以减少许多行业中数据标注和对象注释过程的工作量。
数据中的对象级别信息有多种形式。边界框是存储最流行和最便宜的解决方案。它使用一个可以从图像中裁剪出对象的矩形和一个描述其所属类别的标签。我们需要保存矩形及其标签或标签嵌入以供进一步查询。除此之外,我们还需要处理边界框之间的关系。边界框之间涉及的关系可以列举如下:
- 一张图像可能包含多个不同实例的边界框。
- 边界框可能存在重复。
考虑到上述所有因素,我们可以将它们分为两部分:MyScale可以处理的部分和不能处理的部分。数据库可以通过同时使用一个边界框表和一个图像表来处理第一个因素。它还可以执行更多操作,如对象排序和分组、多准则搜索和预测概率计算。您只需要处理第二个因素:消除重复的边界框,这可以通过非最大抑制(NMS)简单实现。
# 数据集概述
我们从COCO数据集中选择了287,104张图像,包括训练/测试/验证/未标记集中的所有图像。该数据集包含81个类别的约130万个标注图像。我们选择这个数据集是因为它具有高方差和物体密度,这可能会让我们在检索未覆盖的物体类别时获得惊喜。例如,检测穿着白色衬衫的人、橱柜甚至停车标志:
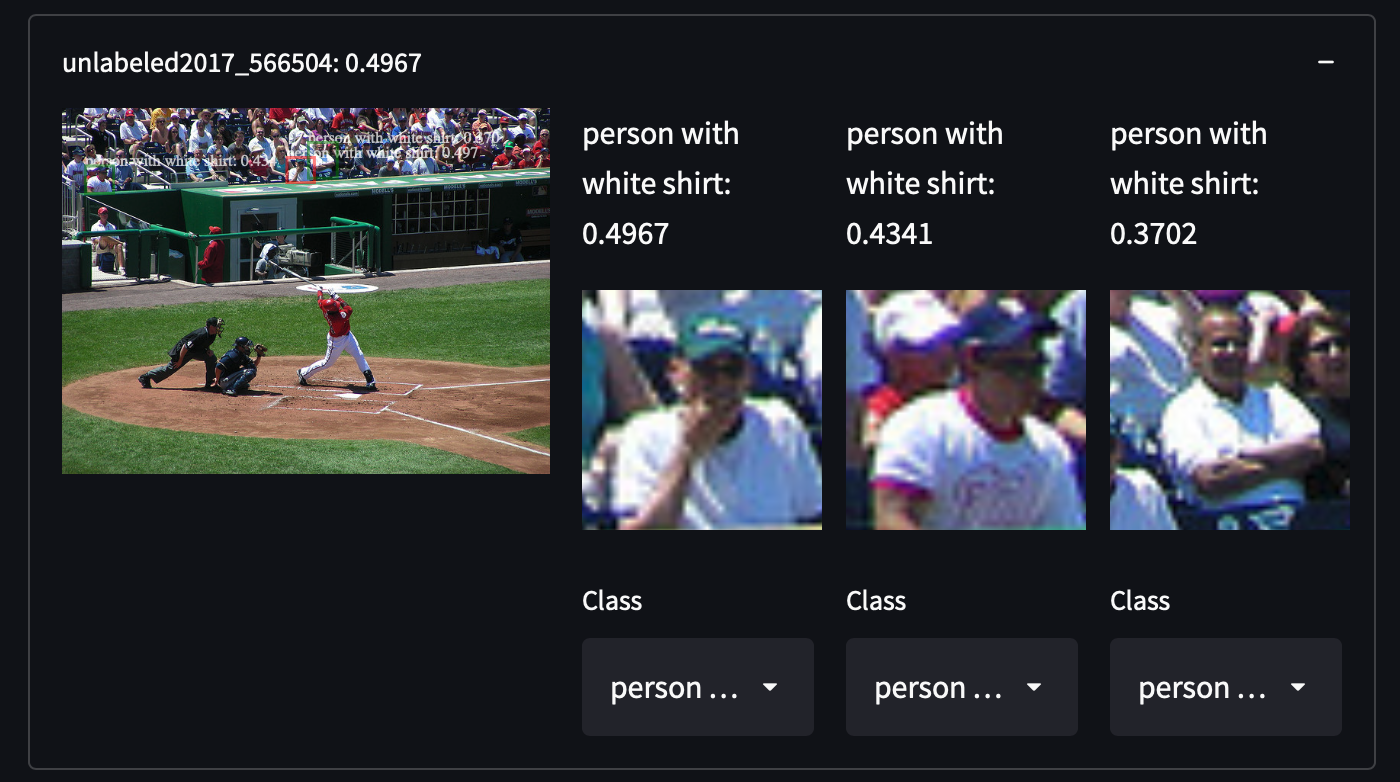
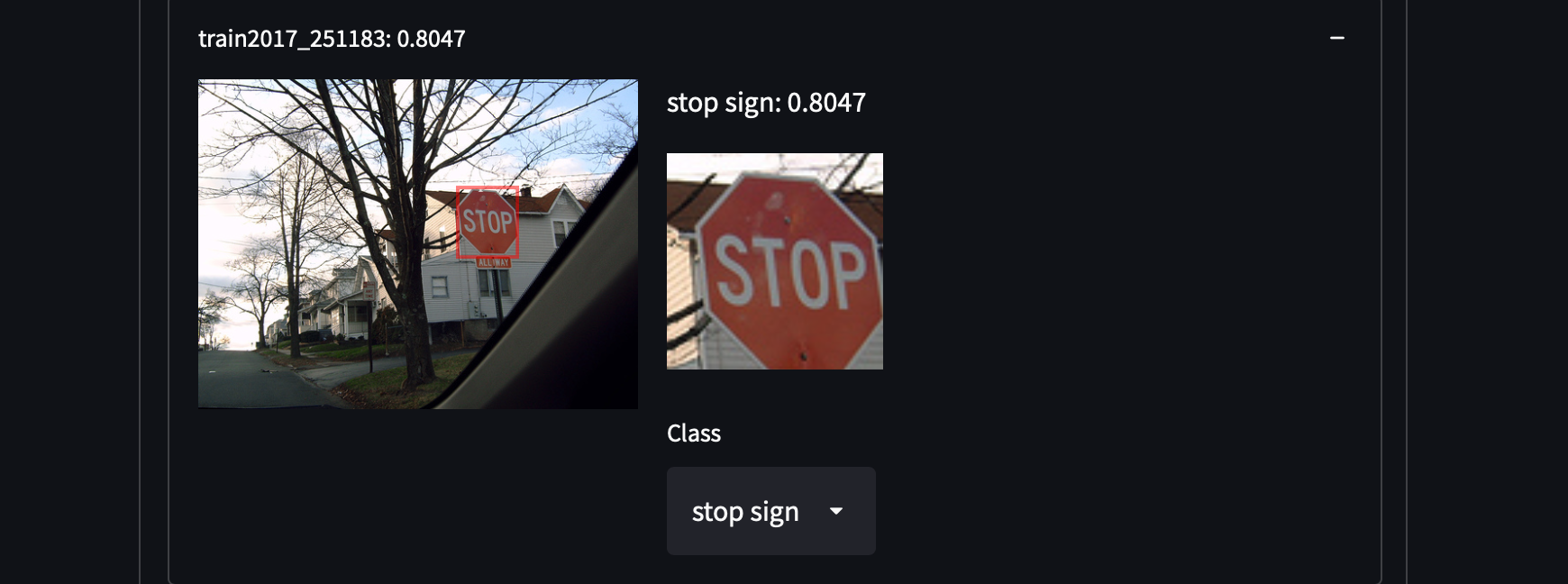
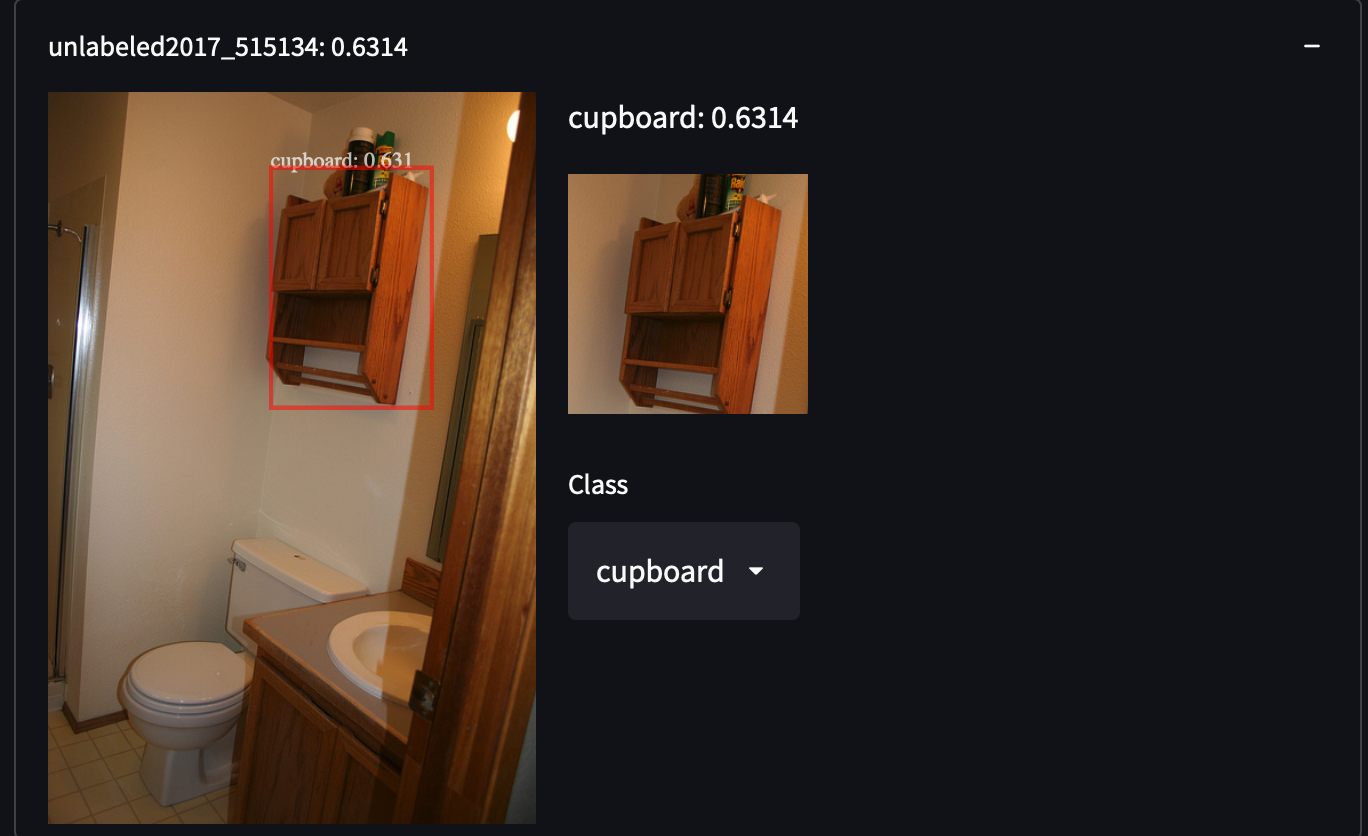 获取COCO数据集非常容易。只需下载所有的JSON文件并解析即可。
获取COCO数据集非常容易。只需下载所有的JSON文件并解析即可。
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip annotations_trainval2017.zip
加载和解析数据后,您将在键coco_url下找到每个图像的唯一URL。我们将使用特定的图像来演示如何提取特征。
import requests
from PIL import Image
from io import BytesIO
from transformers import OwlViTProcessor, OwlViTForObjectDetection
response = requests.get("http://images.cocodataset.org/train2017/000000391895.jpg")
img = Image.open(BytesIO(response.content))
img_s = img.size
if img.mode in ['L', 'CMYK', 'RGBA']:
# L是灰度图像,CMYK使用替代色彩通道
img = img.convert('RGB')
# 开放词汇物体检测
视觉-文本模型是为黑魔法而生的。它可以通过一个咒语给出一个分类器。CLIP (opens new window)在图像级别上实现了这一点,实现了零样本图像分类。它使用对比损失将视觉和文本领域的特征进行对齐。我们已经在少样本学习演示 (opens new window)中看到了它惊人的性能。受到CLIP的启发,如果我们将CLIP应用于小的图像块并在这些小的图像块上预测边界框,可能会更有趣。每个边界框的对齐的视觉-文本特征将使我们成为一个零样本检测器。然后,通过使用查询嵌入将这些边界框与类别嵌入之间的内积进行排序,我们可以在数据集中找到相似的对象。
然而,当您设法设计存储解决方案时,可能会遇到一个陷阱。实际的网络输出比图示的要复杂一些。除了图示中绘制的两个输出之外,它还生成一个缩放因子和一个偏移标量,以放大或缩小对预测的置信度。因此,实际的预测公式应该写成这样并简化为这样:
让我们回到代码。像往常一样,我们对图像进行预处理以适应模型的输入。
from transformers import OwlViTProcessor, OwlViTForObjectDetection
name = "google/owlvit-base-patch32"
model = OwlViTForObjectDetection.from_pretrained(name)
processor = OwlViTProcessor.from_pretrained(name)
# 预处理图像
ret = processor(text=txt, images=img, return_tensor='pt')
img = ret['pixel_values'][0]
我们在OWLViT中进行了一些微调,因为我们想手动使用先前的公式提取图像特征和边界框。
def extract_visual_feature(img):
with torch.no_grad():
model.eval()
# 从ViT中提取特征
vision_outputs = model.owlvit.vision_model(
pixel_values=img,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
use_hidden_state=False,
)
last_hidden_state = vision_outputs[0]
image_embeds = model.owlvit.vision_model.post_layernorm(
last_hidden_state)
# 调整类别令牌的大小
new_size = tuple(np.array(image_embeds.shape) - np.array((0, 1, 0)))
class_token_out = torch.broadcast_to(image_embeds[:, :1, :], new_size)
# 将图像嵌入与类别令牌合并
image_embeds = image_embeds[:, 1:, :] * class_token_out
image_embeds = model.layer_norm(image_embeds)
# 调整为[batch_size, num_patches, num_patches, hidden_size]
new_size = (
image_embeds.shape[0],
int(np.sqrt(image_embeds.shape[1])),
int(np.sqrt(image_embeds.shape[1])),
image_embeds.shape[-1],
)
image_embeds = image_embeds.reshape(new_size)
# 文本和视觉变换器的最后隐藏状态
vision_model_last_hidden_state = vision_outputs[0]
feature_map = image_embeds
batch_size, num_patches, num_patches, hidden_dim = feature_map.shape
image_feats = torch.reshape(
feature_map, (batch_size, num_patches * num_patches, hidden_dim))
# 预测物体边界框
pred_boxes = model.box_predictor(image_feats, feature_map)
image_class_embeds = model.class_head.dense0(image_feats)
image_class_embeds /= torch.linalg.norm(
image_class_embeds, dim=-1, keepdim=True) + 1e-6
# 对logits应用可学习的偏移和缩放
logit_shift = model.class_head.logit_shift(image_feats)
logit_scale = model.class_head.logit_scale(image_feats)
logit_scale = model.class_head.elu(logit_scale) + 1
prelogit = torch.cat([image_class_embeds * logit_scale,
logit_shift * logit_scale], dim=-1)
return prelogit, image_class_embeds, pred_boxes
# 提取!
prelogit, image_class_embeds, pred_boxes = extract_visual_feature(
img.unsqueeze(0))
剩下的就取决于您了!您需要做的就是存储这些数据并将它们上传到MyScale。您可以按照我们的SQL参考插入自己的数据!
# 存储和查询设计的最佳实践
我们有两种类型的实例:边界框和图像。边界框属于图像。因此,在两个表中存储数据更加高效和灵活。
# 存储设计
# 图像表
| 列 | 数据类型 | |
|---|---|---|
| img_id | 字符串 | 主键 |
| img_url | 字符串 | |
| img_w | Int32 | |
| img_h | Int32 |
# 对象表
| 列 | 数据类型 | |
|---|---|---|
| obj_id | 字符串 | 主键 |
| img_id | 字符串 | (外键) |
| box_cx | Float32 | |
| box_cy | Float32 | |
| box_w | Float32 | |
| box_h | Float32 | |
| class_embedding | Array(Float32) | 长度 = 512 |
| prelogit | Array(Float32) | 长度 = 513 |
表结构SQL:
CREATE TABLE IMG_TABLE (
`img_id` String,
`img_url` String,
`img_w` Int32,
`img_h` Int32
) ENGINE = MergeTree PRIMARY KEY img_id
ORDER BY
img_id SETTINGS index_granularity = 8192
CREATE TABLE OBJ_TABLE (
`obj_id` String,
`img_id` String,
`box_cx` Float32,
`box_cy` Float32,
`box_w` Float32,
`box_h` Float32,
`logit_resid` Float32,
`class_embedding` Array(Float32),
`prelogit` Array(Float32),
CONSTRAINT cls_emb_len CHECK length(class_embedding) = 512,
CONSTRAINT prelogit_len CHECK length(prelogit) = 513,
VECTOR INDEX vindex prelogit TYPE MSTG('metric_type=IP')
) ENGINE = MergeTree PRIMARY KEY obj_id
ORDER BY
obj_id SETTINGS index_granularity = 8192
我们使用了 MSTG 作为我们的向量搜索算法。有关配置详细信息,请参阅向量搜索。
# 查询设计
我们将用户的每个短语视为一个单独的查询,并检索每个查询的前 K 个结果。这些查询应该按图像分组,并按组合得分排序。例如,包含多个相关对象的图像应该比只包含一个相关对象的图像排名更高。因此,我们还需要使用 SQL 来计算这一点。
# 子查询:避免对大数据列进行过多读取
对于我们收到的每个文本查询,我们查询 class_embedding、预测的框和置信度以及它们的图像信息。在正常应用程序中,class_embedding 列实际上并不是必需的。但对于像这样的 few-shot 学习器,我们需要这些原始向量来训练我们的分类器。这给我们在处理大数据列、使用多个向量进行搜索以及减少不必要的网络流量以提高速度方面带来了挑战。这是一个高级查询设计和优化的很好展示。
直观地说,通过我们的向量距离函数,我们可以将我们的 SQL 组合成以下形式以实现我们的目标:
-- 例如,我们有一个标签 `0` 的查询和 _xq0 作为我们的查询向量
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l,
distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
JOIN IMG_TABLE
ON OBJ_TABLE.img_id = IMG_TABLE.img_id
ORDER BY dist DESC LIMIT 10
这是正确的,但不高效。这个查询将读取所有列,包括存储在 class_embedding 列中的巨大向量数据。这将是一场灾难,并且会将搜索速度拖到地面上。您将不得不等待数据库读取数据以获取结果。因此,我们必须改变查询方式。
我们查询的真正目标是检索查询向量的最近邻居及其信息。我们可以将其分为两个步骤,换句话说,两个子查询。首先,获取这些框的 obj_id,然后获取框的位置和嵌入。WHERE 在过滤掉不必要的数据时也很方便。改进后的查询如下所示:
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
WHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
我们使用 WHERE 在将图像表和对象表连接在一起之前过滤掉非 TopK 的对象。这样可以避免对 class_embedding 列进行大量读取。在修剪掉这些未使用的数据之后,我们可以轻松读取我们查询所需的数据。很好,我们手头上有一个快速而功能强大的查询!
# 分组子查询
首先,我们需要在分组之前合并所有子查询。当您有多个子查询需要收集时,UNION ALL (opens new window) 是有用的。此外,我们知道某些图像可能包含多个对象。我们不希望框散布在结果中的各个位置,因此我们需要对它们进行分组。现在是使用 GROUP BY 子句的时候了。但是,您需要将查询的每个列放在聚合函数下或在 GROUP BY 后面。在这种情况下,我们使用 groupArray (opens new window) 将所有分组结果连接成一个数组。因此,我们的最终查询版本将是:
SELECT img_id, groupArray(obj_id) AS box_id, img_url, img_w, img_h,
groupArray(box_cx) AS cx, groupArray(box_cy) AS cy,
groupArray(box_w) AS w, groupArray(box_h) AS h,
groupArray(l) as label, groupArray(class_embedding) AS cls_emb
FROM (
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
UNION ALL
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 1 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq1}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
))
GROUP BY img_id, img_url, img_w, img_h
# 减少应用程序与 MyScale 之间的网络流量
应用程序可能受限于弱网络连接,假设您对此无能为力。如果发生这种情况,请不要绝望。MyScale 比您想象的更强大。减少网络流量将是您唯一的目标,但是如何做到呢?如果您不检索嵌入数据,您将无法在服务器上计算梯度...实际上,这个计算不一定要在您的服务器上执行,它可以在数据库内部进行。正如它可以使用中间层输出计算网络的输出并对其进行排序一样,您可以期望它也可以计算梯度。计算梯度可以帮助您避免直接从数据库检索嵌入,这通常需要超过 20MB 的数据来进行单个查询。在 10Mbps 带宽下,这可能需要长达 20 秒的时间。在某些情况下,这是完全不可接受的。
让我们看看如何做到这一点。假设我们采用二元交叉熵作为训练 few-shot 分类器的损失函数,我们可以轻松地获得
其中
SELECT sumForEachArray(arrayMap((x,p,y)->arrayMap(i->i*(p-y), x), X, P, Y)) AS grad FROM (
SELECT groupArray(arrayPopBack(prelogit)) AS X,
groupArray(1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, <your-weight>))))) AS P,
<your-label> AS Y
FROM <your-db>
WHERE obj_id IN [<your-objects>]
)
上述 SQL 可以直接给出梯度。您的应用程序只需要处理剩下的部分:使用学习率应用此梯度。相信我,这个技巧非常快。
# 使用数组函数的高级用法
在查询过程中,我们需要计算不存在于任何列中的数据。与聚合函数 (opens new window)不同,我们需要对数组对象逐个元素进行计算。因此,这里就有了数组函数 (opens new window)。ClickHouse 提供了许多方便的函数来帮助我们操作数组。MyScale 的向量搜索算法与 ClickHouse 的 Array (opens new window) 兼容。因此,您可以利用 ClickHouse 中的所有数组函数。这里我们有两个示例来演示如何使用数组函数。
# 计算预测置信度
回顾上面的公式,预测的置信度是通过一个 sigmoid 函数映射的内积计算的。在这里,我们使用 arrayMap (opens new window) 和 arraySum (opens new window) 来计算最终的 logit。计算函数如下:
SELECT 1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, {_xq0})))) AS pred_logit
FROM OBJ_TABLE LIMIT 10
map 函数逐个元素地将两个数组相乘:_xq0 和来自 prelogit 列的每个数组。此函数可以消耗单个数组或来自列的数组。
# 计算图像得分
为了给用户提供更好的体验,我们应该根据图像的整体相关性对图像进行排序。在这里,我们提供一个简单的示例,以描述如何使用 ClickHouse 数组函数来描述图像的整体相关性。在本节中,我们将介绍 arrayReduce (opens new window)。这个函数是一组函数中的一部分,其中之一是 maxIf。它可以根据给定的掩码计算数组中的最大值。
我们将整体图像相关性定义为每个类别 logit 的总和。更具体地说,我们首先通过类别标签计算每个标签的最大置信度,然后将它们相加。这意味着图像中包含的类别越多,图像的相关性越高。此外,最大置信度越高,相关性越高。
我们获取先前计算的 pred_logit,表达式如下:
arraySum(arrayFilter(x->NOT isNaN(x),
array(arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=0, label)),
arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=1, label)))))
首先,我们使用 arrayMap 函数为给定的标签计算一个掩码,然后使用它来计算用户查询中每个标签的最大分数。我们将计算得到的最大分数集合转换为数组,并在它们的任何值不为 Nan 时计算它们的总和。这将立即给出您的整体图像得分。
# 最后
本教程为您提供了有关 MyScale 的高级用法示例。它涵盖了子查询、分组、数组函数和 MyScale 中的高效 SQL 设计。以下是一些可能有用的要点:
- 对于复杂的向量距离:尝试使 MyScale 的事情变得可爱。大多数距离函数总是可以转换为 L2 距离、余弦距离或内积之一。确保您知道将要处理的函数是哪个。
- 对于复杂的向量 SQL:将大向量列留在后面,先处理/检索小列。
- 对于高级计算:数组函数始终是您最好的朋友。使用 SQL 计算这些数字可以给您带来额外的力量:如果您在 MyScale 内部进行排序/选择,成本将很低,并且还可以为您节省每天的几分钱,因为在 Web 服务器上进行的计算更少。
 京公网安备 11010802042981号
京公网安备 11010802042981号