
# Schnellstart
![]()
![]()
Diese Anleitung zeigt Ihnen, wie Sie in wenigen einfachen Schritten einen Cluster starten, Daten importieren und SQL-Abfragen ausführen können. Weitere Informationen zu anderen Entwicklertools wie dem Python-Client finden Sie im Abschnitt Entwicklertools.
# Wie starte ich Ihren ersten Cluster?
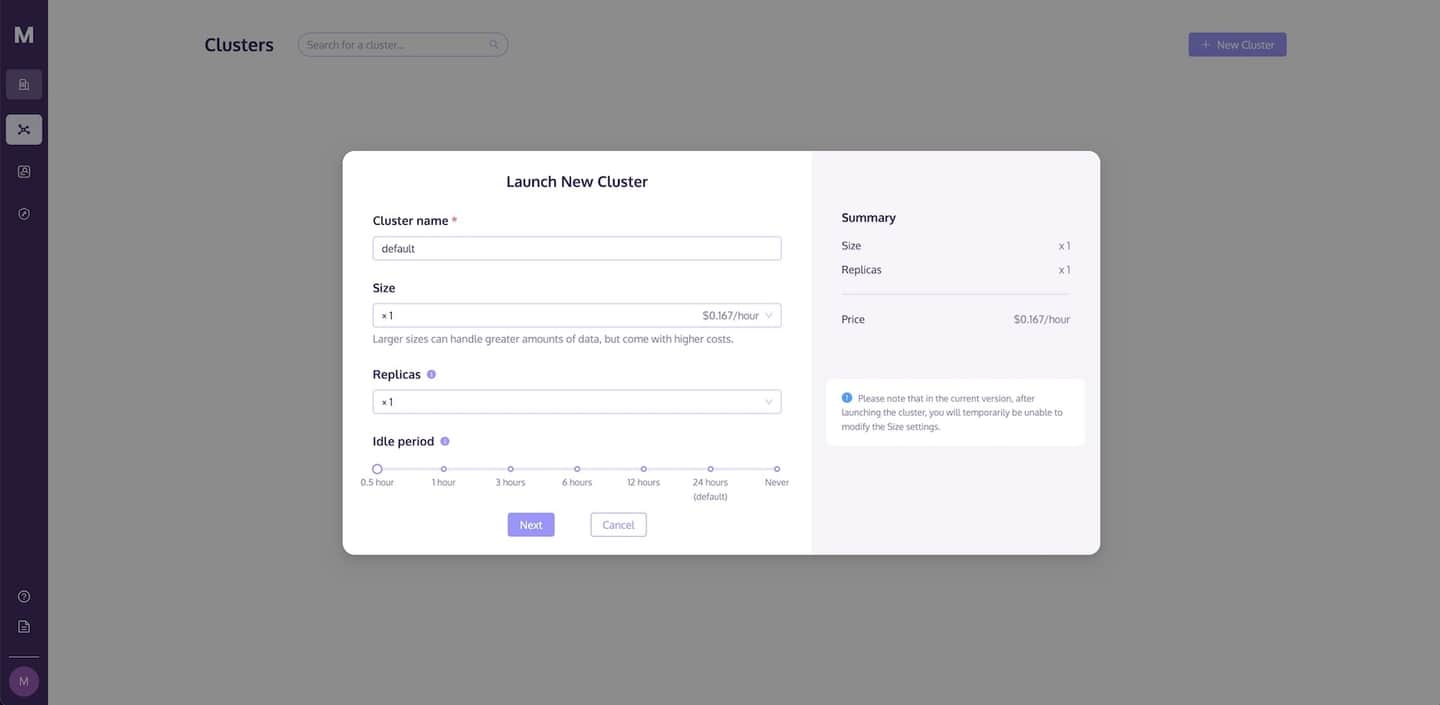
Bevor Sie Datenoperationen durchführen können, müssen Sie einen Cluster starten. Auf der Seite Cluster können Sie einen Cluster erstellen und die Rechen- und Speicherressourcen konfigurieren, um Ihren Anforderungen gerecht zu werden.
Befolgen Sie diese Schritte, um einen neuen Cluster zu starten:
- Gehen Sie zur Seite Cluster und klicken Sie auf die Schaltfläche +Neuer Cluster, um einen neuen Cluster zu starten.
- Geben Sie Ihrem Cluster einen Namen.
- Klicken Sie auf Starten, um den Cluster auszuführen.
TIP
Die Entwicklungsstufe von MyScale ist auf die Standardkonfiguration beschränkt und unterstützt keine mehrfachen Replikate. Wechseln Sie zum Standardtarif, um eine leistungsstärkere Konfiguration zu erhalten. Weitere Informationen finden Sie im Abschnitt Ändern Ihres Abrechnungsplans.
# Umgebung einrichten
Sie haben die Möglichkeit, eine Verbindung zu einer MyScale-Datenbank mit einem der folgenden Entwicklertools herzustellen:
Lassen Sie uns jedoch Python verwenden, um loszulegen.
# Mit Python
Bevor Sie mit Python beginnen, müssen Sie den ClickHouse-Client (opens new window) installieren, wie im folgenden Shell-Skript beschrieben:
pip install clickhouse-connect
Nach erfolgreicher Installation des ClickHouse-Clients ist der nächste Schritt, eine Verbindung zu Ihrem MyScale-Cluster innerhalb einer Python-App herzustellen, indem Sie die folgenden Details angeben:
- Cluster-Host
- Benutzername
- Passwort
Um diese Details zu finden, navigieren Sie zur MyScale-Clusterseite, klicken Sie auf den Dropdown-Link Aktion und wählen Sie Verbindungsdetails.
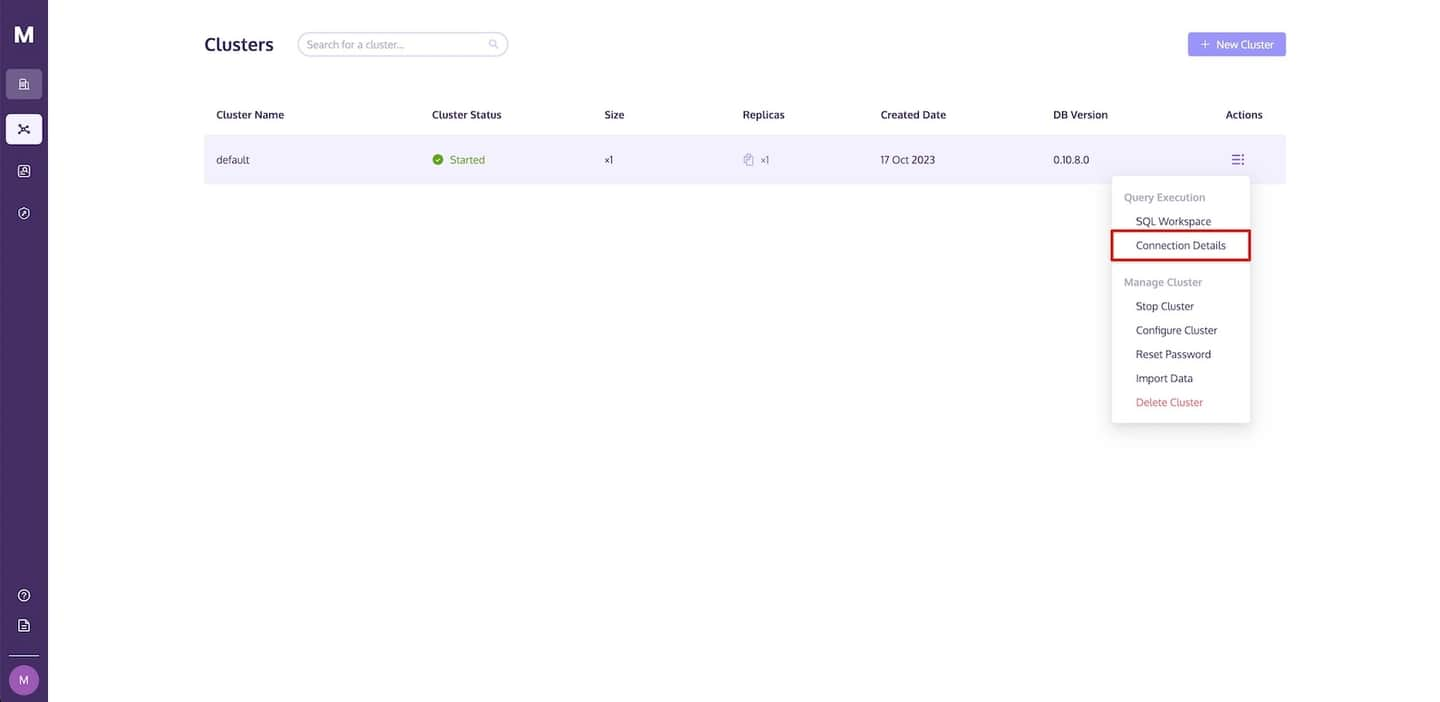
Wie im folgenden Bild zu sehen ist, wird ein Dialogfeld Verbindungsdetails angezeigt, das den erforderlichen Code enthält, um auf MyScale zuzugreifen. Klicken Sie auf das Kopiersymbol, um den entsprechenden Code zu kopieren, und fügen Sie ihn in Ihre Python-App ein.
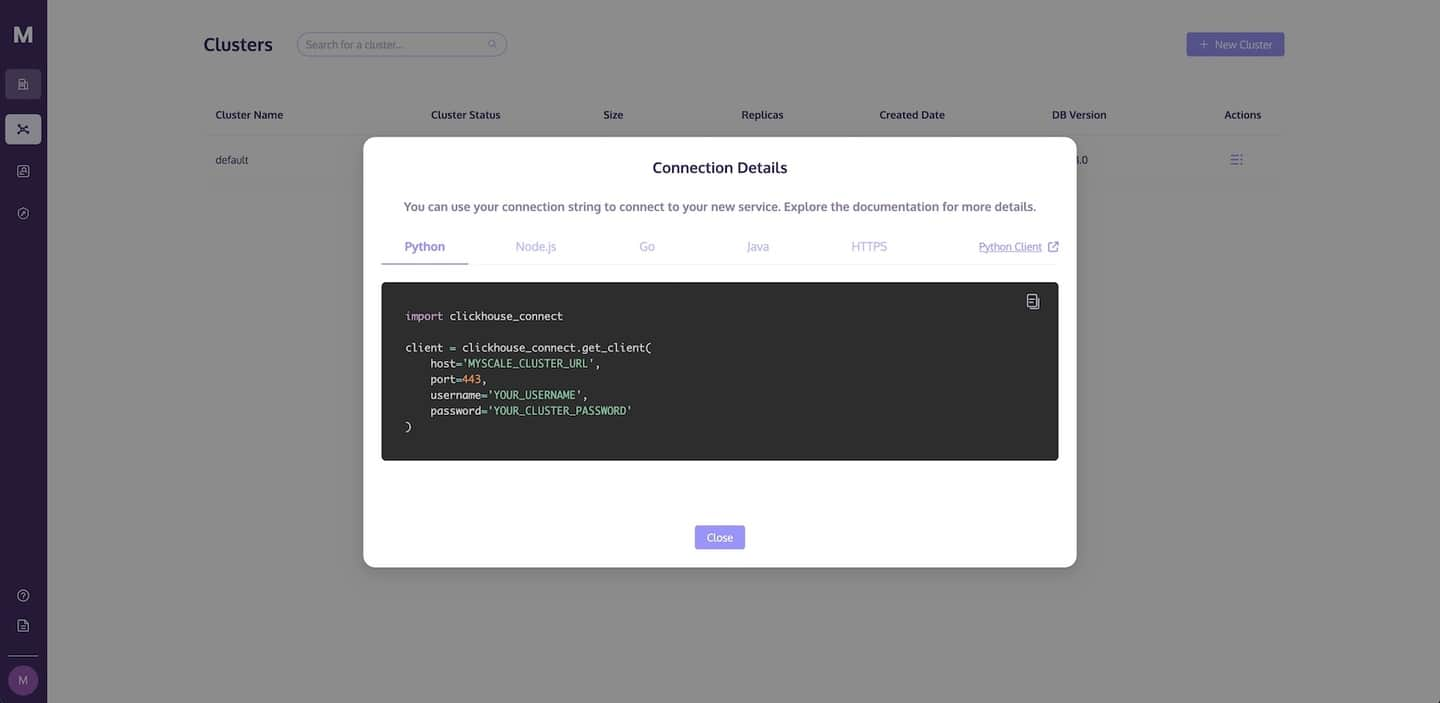
TIP
Weitere Informationen zum Herstellen einer Verbindung zu Ihrem MyScale-Cluster finden Sie unter Verbindungsdetails.
# Mit der MyScale-Konsole
Um die MyScale-Konsole zum Importieren von Daten in Ihre Datenbank und zum Ausführen von Abfragen zu verwenden, navigieren Sie zur Seite SQL-Arbeitsbereich. Ihr Cluster wird automatisch ausgewählt, wie unten gezeigt:
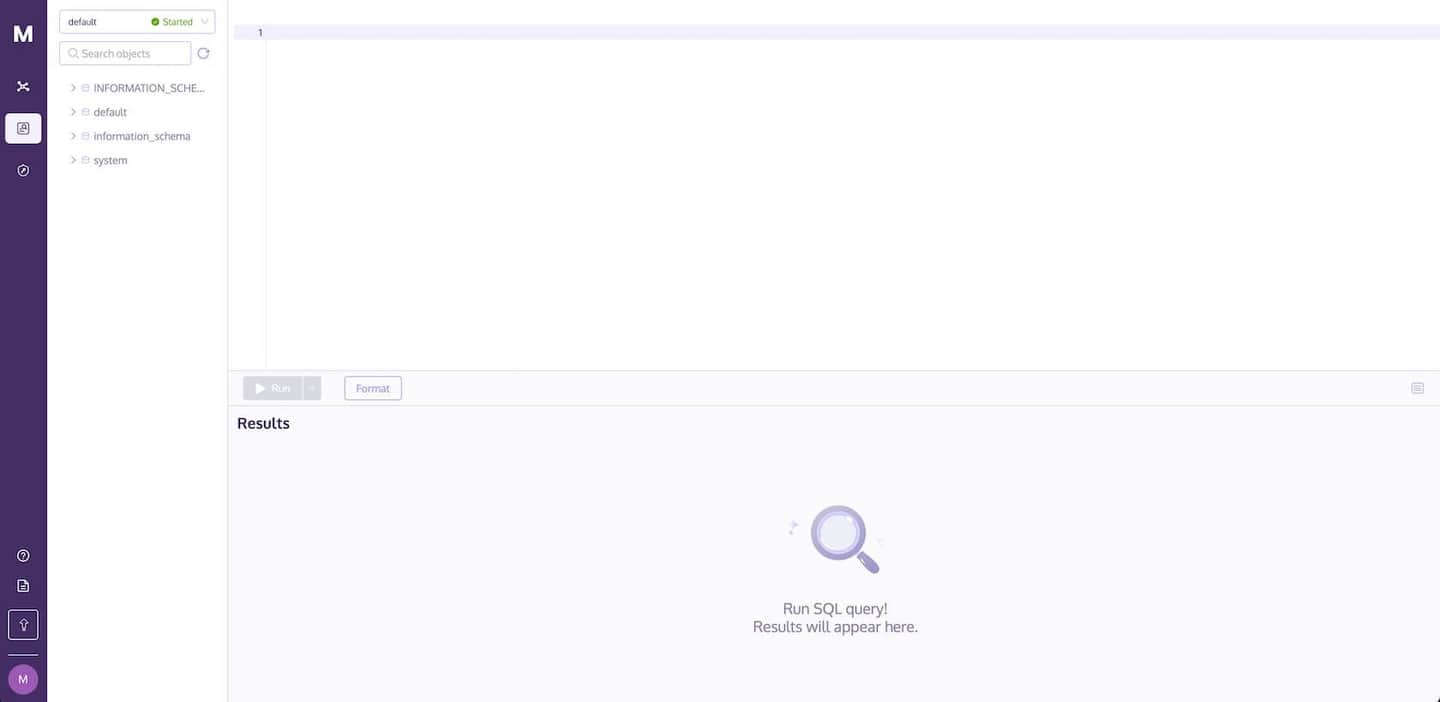
# Wie importiere ich Daten in die Datenbank?
Befolgen Sie diese Schritte, um Daten in MyScale zu importieren:
# Erstellen Sie eine Tabelle
Das Erstellen einer Datenbanktabelle in MyScale vor dem Importieren von Daten ist obligatorisch.
TIP
Weitere Informationen finden Sie in der Dokumentation zum Erstellen einer Datenbank und zum Erstellen einer Tabelle im Abschnitt SQL-Referenz.
Mit den folgenden Codebeispielen schreiben wir einen SQL-Befehl (sowohl in Python als auch in SQL), um eine neue Tabelle mit dem Namen default.myscale_categorical_search zu erstellen.
- Python
- SQL
# Erstellen Sie eine Tabelle mit 128-dimensionalen Vektoren.
client.command("""
CREATE TABLE default.myscale_categorical_search
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id""")
# Fügen Sie Daten in die Tabelle ein
TIP
MyScale unterstützt den Import von Daten aus Amazon S3 und anderen Cloud-Diensten mithilfe von S3-kompatiblen APIs. Weitere Informationen zum Importieren von Daten aus Amazon S3 finden Sie in der s3-Tabellenfunktion.
Wie in den folgenden Codeausschnitten beschrieben, verwenden wir SQL, um Daten in die Tabelle default.myscale_categorical_search zu importieren.
Unterstützte Dateiformate sind:
CSV(opens new window)CSVWithNames(opens new window)JSONEachRow(opens new window)Parquet(opens new window)
TIP
Weitere Informationen zu den Formaten für Ein- und Ausgabedaten finden Sie in der ausführlichen Beschreibung aller unterstützten Formate unter Formate für Ein- und Ausgabedaten (opens new window).
- Python
- SQL
client.command("""
INSERT INTO default.myscale_categorical_search
SELECT * FROM s3(
'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv',
'CSVWithNames',
'id UInt32, data Array(Float32), date Date, label Enum8(''person'' = 1, ''building'' = 2, ''animal'' = 3)'
)""")
# Erstellen Sie einen Vektorindex
Neben der Erstellung herkömmlicher Indizes für strukturierte Daten können Sie in MyScale auch einen Vektorindex für Vektor-Embeddings erstellen. Befolgen Sie diese Schritt-für-Schritt-Anleitung, um zu sehen, wie das geht:
# Erstellen Sie einen MSTG-Vektorindex
Wie die folgenden Codeausschnitte zeigen, besteht der erste Schritt darin, einen MSTG-Vektorindex zu erstellen, einen Vektorindex, der unseren proprietären Algorithmus MSTG verwendet.
- Python
- SQL
client.command("""
ALTER TABLE default.myscale_categorical_search
ADD VECTOR INDEX categorical_vector_idx data
TYPE MSTG
""")
TIP
Die Erstellungszeit des Index hängt von der Größe Ihres Datenimports ab.
# Überprüfen des Build-Status des Vektor-Index
Die folgenden Code-Snippets beschreiben, wie Sie SQL verwenden können, um den Build-Status des Vektor-Index zu überprüfen.
- Python
- SQL
# Abfragen der Systemtabelle 'vector_indices', um den Status der Indexerstellung zu überprüfen.
get_index_status="SELECT status FROM system.vector_indices WHERE table='myscale_categorical_search'"
# Den Status der Indexerstellung ausgeben. Der Status ist 'Built', wenn der Index erfolgreich erstellt wurde.
print(f"Der Index-Build-Status lautet {client.command(get_index_status)}")
Die Ausgabe wird in den folgenden Beispielen angezeigt:
- Python
- SQL
Der Index-Build-Status lautet Built
TIP
Weitere Informationen zu Vektorindizes finden Sie unter Vector Search.
# Ausführen von SQL-Abfragen
Nachdem Sie Daten in eine MyScale-Tabelle importiert und einen Vektor-Index erstellt haben, können Sie die Daten mithilfe der folgenden Suchtypen abfragen:
TIP
Der größte Vorteil beim Erstellen eines MSTG-Vektor-Index ist seine blitzschnelle Suchgeschwindigkeit.
# Vector Search
Normalerweise werden Texte oder Bilder wie "ein blaues Auto" oder Bilder eines blauen Autos abgefragt. MyScale behandelt jedoch alle Abfragen als Vektoren und gibt eine Antwort auf die Abfrage basierend auf der Ähnlichkeit ("Entfernung") zwischen der Abfrage und den vorhandenen Daten in der Tabelle zurück.
Verwenden Sie die folgenden Code-Snippets, um Daten mithilfe eines Vektors als Abfrage abzurufen:
- Python
- SQL
# Wählen Sie eine zufällige Zeile aus der Tabelle als Ziel aus
random_row = client.query("SELECT * FROM default.myscale_categorical_search ORDER BY rand() LIMIT 1")
assert random_row.row_count == 1
target_row_id = random_row.first_item["id"]
target_row_label = random_row.first_item["label"]
target_row_date = random_row.first_item["date"]
target_row_data = random_row.first_item["data"]
print("Derzeit ausgewähltes Element: id={}, label={}, date={}".format(target_row_id, target_row_label, target_row_date))
# Das Ergebnis der Abfrage abrufen.
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist FROM default.myscale_categorical_search ORDER BY dist LIMIT 10
""")
# Iterieren Sie durch die Zeilen des Abfrageergebnisses und geben Sie die 'id', 'date',
# 'label' und die Entfernung für jede Zeile aus.
print("Top 10 Kandidaten:")
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
Die Ergebnismenge mit den zehn ähnlichsten Ergebnissen lautet wie folgt:
| id | date | label | dist |
|---|---|---|---|
| 0 | 2030-09-26 | person | 0 |
| 2 | 1975-10-07 | animal | 60,088 |
| 395,686 | 1975-05-04 | animal | 70,682 |
| 203,483 | 1982-11-28 | building | 72,585 |
| 597,767 | 2020-09-10 | building | 72,743 |
| 794,777 | 2015-04-03 | person | 74,797 |
| 591,738 | 2008-07-15 | person | 75,256 |
| 209,719 | 1978-06-13 | building | 76,462 |
| 608,767 | 1970-12-19 | building | 79,107 |
| 591,816 | 1995-03-20 | building | 79,390 |
TIP
Diese Ergebnisse sind in Vektoreinbettungen, die Sie verwenden können, um die ursprünglichen Daten anhand der id der Ergebnisse abzurufen.
# Filtered Search
Nicht nur können wir Daten mithilfe einer Vektorsuche (unter Verwendung von Vektoreinbettungen) abfragen, sondern wir können auch SQL-Abfragen mithilfe einer Kombination aus strukturierten und Vektordaten ausführen, wie die folgenden Code-Snippets beschreiben:
- Python
- SQL
# Das Ergebnis der Abfrage abrufen.
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist
FROM default.myscale_categorical_search WHERE toYear(date) >= 2000 AND label = 'animal'
ORDER BY dist LIMIT 10
""")
# Iterieren Sie durch die Zeilen des Abfrageergebnisses und geben Sie die 'id', 'date',
# 'label' und die Entfernung für jede Zeile aus.
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
Die Ergebnismenge mit den zehn ähnlichsten Ergebnissen lautet wie folgt:
| id | date | label | dist |
|---|---|---|---|
| 601,326 | 2001-05-09 | animal | 83,481 |
| 406,181 | 2004-12-18 | animal | 93,655 |
| 13,369 | 2003-01-31 | animal | 95,158 |
| 209,834 | 2031-01-24 | animal | 97,258 |
| 10,216 | 2011-08-02 | animal | 103,297 |
| 605,180 | 2009-04-20 | animal | 103,839 |
| 21,768 | 2021-01-27 | animal | 105,764 |
| 1,988 | 2000-03-02 | animal | 107,305 |
| 598,464 | 2003-01-06 | animal | 109,670 |
| 200,525 | 2024-11-06 | animal | 110,029 |