
Retrieval augmented generation (opens new window) (RAG) was a major breakthrough in the domain of natural language processing (NLP), particularly for the development of AI applications. RAG combines a large knowledge base (opens new window) and the linguistic capabilities of large language models (opens new window) (LLMs) with data retrieval capabilities. The ability to retrieve and use information in real time makes AI interactions more genuine and informed.
RAG has obviously improved the way users interact with AI. For example, LLM-powered chatbots (opens new window) can already handle complicated questions and tailor their responses to individual users. RAG applications enhance this by not just using the training data, but also by looking up up-to-date information during the interaction.
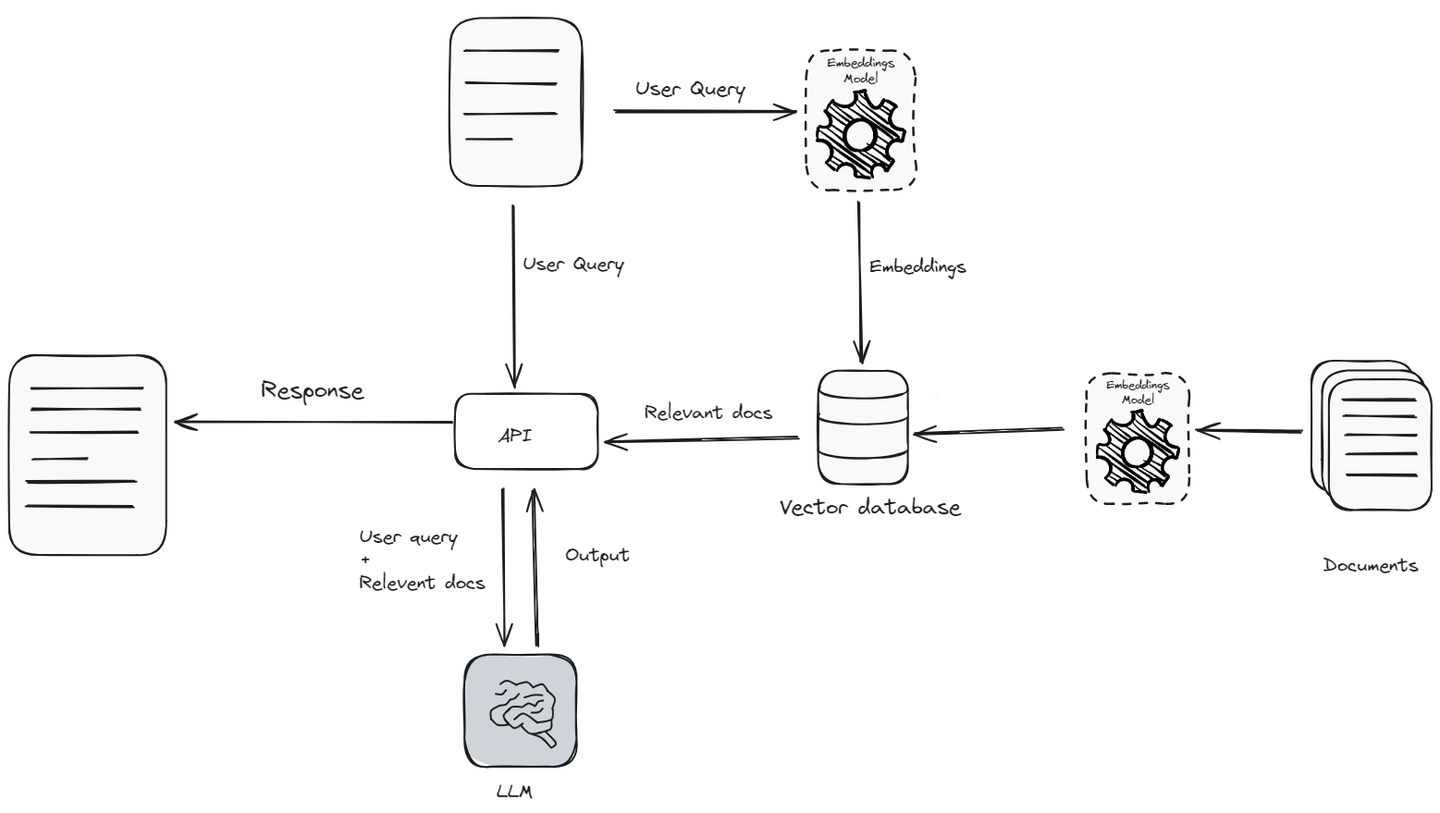
However, RAG applications work pretty well when used on a small scale but pose significant challenges when we try to scale them, such as managing the API and data storage costs, reducing latency and increasing throughput, efficiently searching across large knowledge bases, and ensuring user privacy.
In this blog, we will explore the various challenges encountered when scaling RAG applications, along with effective solutions to address them.
# Managing Costs: Data Storage and API Usage
One of the biggest hurdles in expanding RAG applications is managing costs, particularly due to the dependency on APIs from large language models (LLMs) like OpenAI (opens new window), or Gemini (opens new window). When you are building an RAG application, there are three major cost factors to consider:
- LLM API
- Embeddings models API
- Vector database
The cost of these APIs is higher because service providers manage everything on their end, such as computational costs, training, etc. This setup might be sustainable for smaller projects, but as your application's usage scales up, the costs can quickly become a significant burden.
Let's say you're using gpt-4 in your RAG application and your RAG application handles over 10 million input and 3 million output tokens daily, you could be looking at costs of around $480 each day, which is a significant amount to run any application. At the same time, the vector databases also need regular updates and must be scaled as your data grows, which adds even more to your costs.
# Cost Reduction Strategies
As we've discussed, certain components in the RAG architecture can be quite expensive. Let's discuss some of the strategies to reduce the cost of these components.
- Finetune an LLM and embedding model: To minimize the costs associated with the LLM API and embedding model, the most effective approach is to choose an open-source LLM (opens new window) and embedding model and then, finetune them using your data. However, this requires a lot of data, technical expertise, and computational resources.
- Caching: Using a cache (opens new window) to store responses from an LLM can reduce the cost of API calls as well as make your application faster and more efficient. When a response is saved in the cache, it can be quickly retrieved if needed again, without having to ask the LLM for it a second time. The usage of a cache can reduce the cost of API calls by up to 10%. You can use different caching techniques (opens new window) from LangChain.
- Concise Input Prompts: You can reduce the number of input tokens required by refining and shortening the input prompts. This not only allows the model to understand the user query better but also lowers costs since fewer tokens are used.
- Limiting Output Tokens: Setting a limit on the number of output tokens can prevent the model from generating unnecessarily long responses, thus controlling costs while still providing relevant information.
# Reduce the Cost of Vector Databases
A vector database plays a crucial role in an RAG application, and the type of data you input is equally important. As the saying goes, "garbage in, garbage out".
- Pre-processing: The aim of preprocessing the data is to achieve text standardization and consistency. Text standardization removes irrelevant details and special characters, making the data-rich in context and consistent. Focusing on clarity, context, and correctness not only enhances the system's efficiency but also reduces the data volume. The reduction in data volume means there's less to store, which lowers storage costs and improves the efficiency of data retrieval.
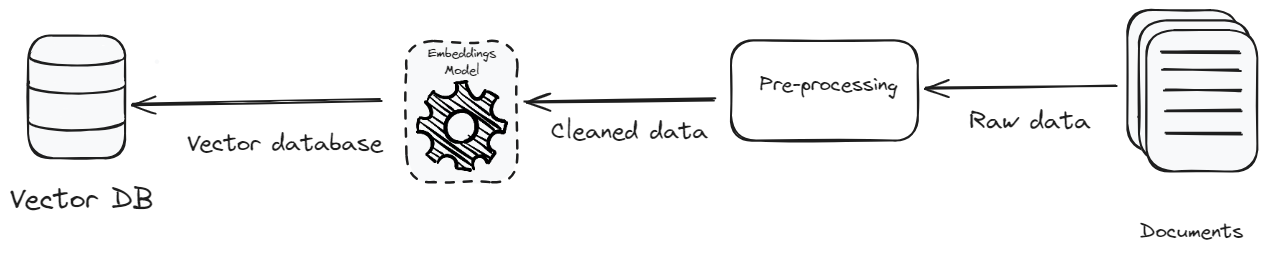
- Cost-Efficient Vector Database: Another method to reduce costs is to select a less expensive vector database. Currently, there are so many options available in the market, but it's crucial to choose one that is not only affordable but also scalable. MyScaleDB (opens new window) is a vector database that has been specially designed for developing scalable RAG applications keeping in mind several factors, especially cost. It's one of the cheapest vector databases available in the market with much better performance than its competitors.
Related Article: Getting Started with MyScale (opens new window)
# The Large Number of Users Affects the Performance
As an RAG application scales, it must not only support an increasing number of users but also sustain its speed, efficiency, and reliability. This involves optimizing the system to ensure peak performance, even with high numbers of simultaneous users.
Latency: For real-time applications like chatbots, maintaining low latency (opens new window) is crucial. Latency refers to the delay before a transfer of data begins following an instruction for its transfer. Techniques to minimize latency include optimizing network paths, reducing the complexity of data handling, and using faster processing hardware. One way to manage latency effectively is to limit prompt sizes to essential information, avoiding overly complex instructions that can slow down processing.
Throughput: During periods of high demand, the ability to process a large number of requests simultaneously without slowdown is known as throughput. This can be significantly enhanced by using techniques like continuous batching, where requests are batched dynamically as they arrive, rather than waiting for a batch to be filled.
# Suggestions to Improve Performance:
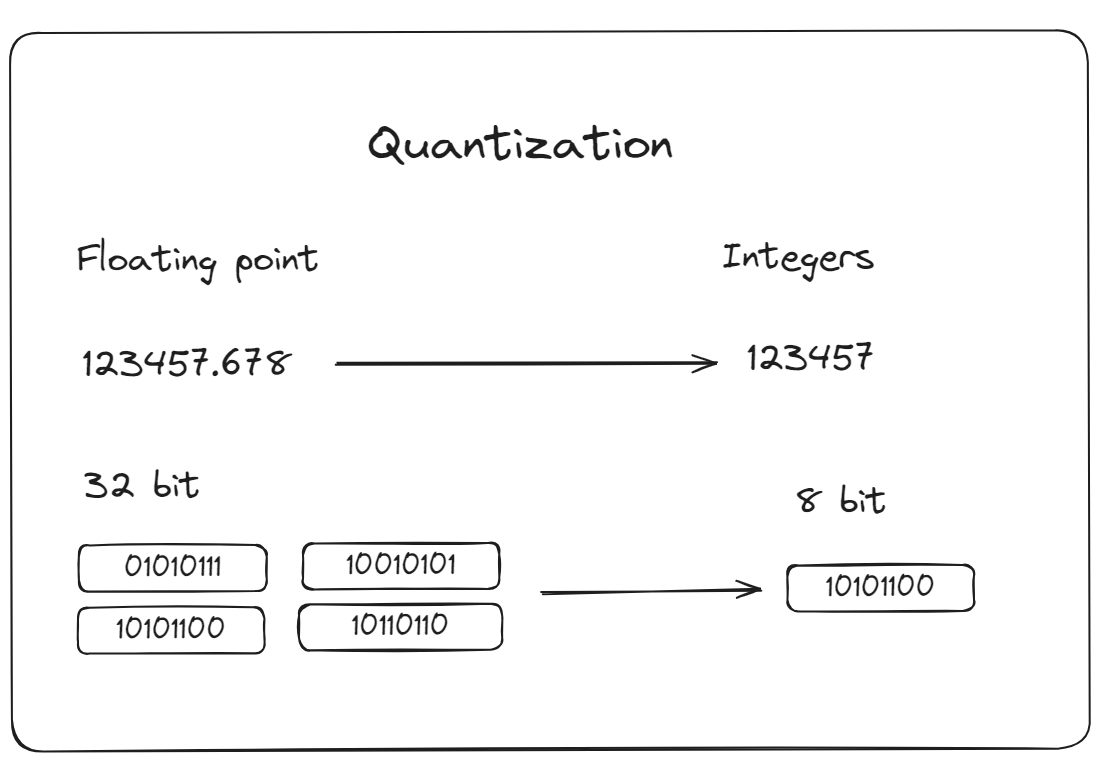
Quantization: It's a process of reducing the precision of the numbers used to represent model parameters. This reduces the model calculations, which can decrease the computational resources required and thus speed up inference times. MyScaleDB provides advanced vector indexing options such as IVFPQ (Inverted File Partitioning and Quantization) or HNSWSQ (Hierarchical Navigable Small World Quantization). These methodologes are designed to improve the performance of your application by optimizing data retrieval processes.
Besides these popular algorithms, MyScaleDB has developed Multi-Scale Tree Graph (MSTG) (an enterprise feature) , which features novel strategies around quantization and tiered storage. This algorithm is recommended for achieving both low cost and high precision, in contrast with IVFPQ or HNSWSQ. By utilizing memory combined with fast NVMe SSDs, MSTG significantly reduces resource consumption compared to IVF and HNSW algorithms while maintaining exceptional performance and precision.
Multi-threading: Multi-threading (opens new window) will allow your application to handle multiple requests at the same time by using the capabilities of multi-core processors. By doing so, it minimizes delays and increases the system's overall speed, especially when managing many users or complex queries.
Dynamic batching: Instead of processing requests to large language models (LLMs) sequentially, dynamic batching intelligently groups multiple requests together to be sent as a single batch. This method enhances efficiency, particularly when dealing with service providers like OpenAI and Gemini, who impose API rate limitations. Using dynamic batching allows you to handle a larger number of requests within these rate limits, making your service more reliable and optimizing API usage.
# Efficient Search Across the Massive Embedding Spaces
Efficient retrieval primarily depends on how well a vector database indexes data and how quickly and effectively it retrieves relevant information. Every vector database performs quite well when the dataset is small, but issues arise as the volume of the data increases. The complexity of indexing and retrieving relevant information grows. This can lead to a slower retrieval process, which is critical in environments where real-time or near-real-time responses are required. Additionally, the larger the database, the harder it is to maintain its accuracy and consistency. Errors, duplications, and outdated information can easily creep in, which can compromise the quality of the outputs provided by the LLM application.
Furthermore, the nature of RAG systems, which rely on retrieving the most relevant pieces of information from vast datasets, means that any degradation in data quality directly impacts the performance and reliability of the application. As datasets grow, ensuring that each query is met with the most accurate and contextually appropriate response becomes increasingly difficult.
# Solutions for Optimized Search:
To ensure that the growth in data volume does not compromise the system's performance or the quality of its outputs, several factors are needed to be considered:
- Efficient Indexing: The use of more sophisticated indexing methods or more efficient vector database solutions is needed to handle large datasets without compromising on speed. MyScaleDB (opens new window) provides a state-of-the-art advanced vector indexing method, MSTG (opens new window), which is designed for handling very large datasets. It has also outperformed other indexing methods with 390 QPS (Queries Per Second) on the LAION 5M dataset, achieving a 95% recall rate and maintaining an average query latency of 18ms with the s1.x1 pod.
- Better Quality Data: To enhance the quality of data, which is very important for the accuracy and reliability of RAG systems, implementing several pre-processing techniques is required. This would help us to refine the dataset, reducing the noise and increasing the precision of the retrieved information. It will directly impact the effectiveness of the RAG application.
- Data Pruning and Optimization: You can regularly review and prune the dataset to remove outdated or irrelevant vectors to keep the database lean and efficient.
Furthermore, MyScaleDB also outperformed other vector databases in data ingestion time by completing tasks in almost 30 minutes for 5M data points. If you sign up, you get to use one x1 pod for free, which can handle up to 5 million vectors.

# The Risk of a Data Breach is Always There
In RAG applications, privacy concerns are notably significant due to two primary aspects: the use of an LLM API and the storage of data in a vector database. When passing private data through an LLM API, there is a risk that the data could be exposed to third-party servers, potentially leading to breaches of sensitive information. Additionally, storing data in a vector database that may not be fully secure can also pose risks to data privacy.
# Solutions for Enhancing Privacy:
To deal with these risks, particularly when dealing with sensitive or highly confidential data, consider the following strategies:
In-House LLM Development: Instead of relying on third-party LLM APIs, you can pick any open-source LLM, and fine-tune it on your data in-house (opens new window). This approach ensures that all sensitive data remains within the controlled environment of your organization, significantly reducing the likelihood of data breaches.
Secured Vector Database: Make sure that your vector database is secured with the latest encryption standards and access controls. MyScaleDB is trusted by teams and organizations due to its robust security features. It is operating on a multi-tenant Kubernetes cluster which is hosted on a secure, fully-managed AWS infrastructure. MyScaleDB safeguards customer data by storing it in isolated containers and continuously monitors operational metrics to uphold system health and performance. Additionally, it has successfully completed the SOC 2 Type 1 audit, adhering to the highest global standards for data security. With MyScaleDB, you can be confident that your data remains strictly your own.
Related Article: Outperforming Specialized Vector Databases with MyScale (opens new window)
# Conclusion
While Retrieval Augmented Generation (RAG) is a great advancement in AI, it does have its challenges. These include high costs for APIs and data storage, increased latency, and the need for efficient throughput as more users come on board. Privacy and data security also become critical as the amount of stored data grows.
We can tackle these issues with several strategies. Reducing costs is possible by using in-house, fine-tuned open-source LLMs and by caching to cut down on API usage. To improve latency and throughput, we can use techniques like dynamic batching and advanced quantization to make processing faster and more efficient. For better security, developing proprietary LLMs and using a vector database like MyScaleDB is a great option.
If you have any suggestions, please reach out to us through Twitter (opens new window) or Discord (opens new window).




