
Stellen Sie sich vor, Sie sind ein Softwareentwickler, der nach Techniken zur Datenbankoptimierung sucht, insbesondere um die Effizienz von Abfragen in groß angelegten Datenbanken zu steigern. In einer herkömmlichen SQL-Datenbank könnten Sie Schlüsselwörter wie "B-Baum-Indizierung" oder einfach "Indizierung" verwenden, um verwandte Blogs oder Artikel zu finden. Diese auf Schlüsselwörtern basierende Methode könnte jedoch wichtige Blogs oder Artikel übersehen, die unterschiedliche, aber verwandte Phrasen verwenden, wie z.B. "SQL-Tuning" oder "Indizierungsstrategien".
Betrachten Sie ein anderes Szenario, in dem Sie den Kontext, aber nicht den genauen Namen einer bestimmten Technik kennen. Herkömmliche Datenbanken, die auf exakten Schlüsselwortübereinstimmungen beruhen, stoßen in solchen Situationen an ihre Grenzen, da sie allein auf der Grundlage des Kontexts nicht suchen können.
Was wir brauchen, ist eine Suchtechnik, die über einfache Schlüsselwortübereinstimmung hinausgeht und Ergebnisse auf der Grundlage semantischer Ähnlichkeiten liefert. Hier kommt Vector Search ins Spiel. Im Gegensatz zu herkömmlichen Schlüsselwortübereinstimmungstechniken vergleicht Vector Search die Semantik Ihrer Abfrage mit den Einträgen in der Datenbank und liefert relevantere und genauere Ergebnisse.
In diesem Blog werden wir alles rund um Vector Search besprechen, angefangen bei den grundlegenden Konzepten bis hin zu fortgeschritteneren Techniken. Fangen wir mit einem Überblick über Vector Search an.
# Ein Überblick über Vector Search
Vector Search ist eine ausgeklügelte Datenabruftechnik, die sich darauf konzentriert, die kontextuellen Bedeutungen von Suchanfragen und Datenbeständen abzugleichen, anstatt nur den Text abzugleichen. Um diese Technik umzusetzen, müssen wir sowohl die Suchanfrage als auch eine bestimmte Spalte des Datensatzes in numerische Darstellungen umwandeln, die als Vektor-Einbettungen bezeichnet werden. Anschließend berechnen wir die Distanz (kosinussimilarity oder euklidische Distanz) zwischen dem Abfragevektor und den Vektor-Einbettungen in der Datenbank. Dann identifizieren wir die nächsten oder ähnlichsten Einträge basierend auf diesen berechneten Distanzen. Schließlich geben wir die Top-k-Ergebnisse mit den kleinsten Distanzen zum Abfragevektor zurück.
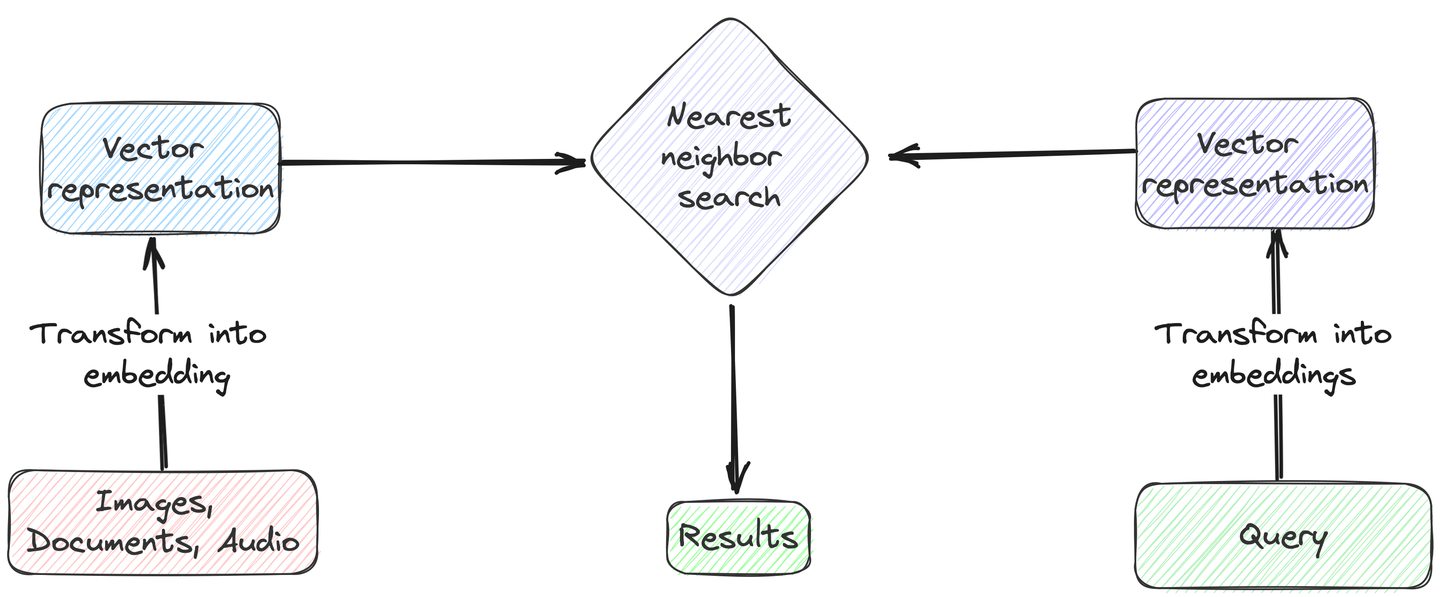
# Typische Szenarien für Vector Search
- Ähnlichkeitssuche: Verwenden Sie dies, um andere Vektoren im Merkmalsraum zu finden, die einem gegebenen Vektor ähnlich sind. Wird in Bereichen wie Bild-, Audio- und Textanalyse weit verbreitet eingesetzt.
- Empfehlungssysteme: Erzielen Sie personalisierte Empfehlungen, indem Sie Vektorrepräsentationen von Benutzern und Elementen analysieren, z.B. Film-, Produkt- oder Musikempfehlungen.
- Natural Language Processing: Suchen Sie nach semantischer Ähnlichkeit in Textdaten, unterstützt semantische Suche und Relevanzanalyse.
- Frage-Antwort-System (QA-System): Suchen Sie nach verwandten Passagen, deren Vektorrepräsentationen der Eingabefrage am ähnlichsten sind. Die endgültige Antwort kann mithilfe eines Large Language Model (LLM) basierend auf der Frage und den abgerufenen Passagen generiert werden.
Brute-Force-Vector-Suche funktioniert sehr gut für die semantische Suche, wenn der Datensatz klein ist und die Abfragen einfach sind. Ihre Leistung nimmt jedoch ab, wenn der Datensatz wächst oder die Abfragen komplexer werden, was zu einigen Nachteilen führt.
# Herausforderungen bei der Implementierung von Vector Search
Lassen Sie uns einige der mit der Verwendung einer einfachen Vector-Suche verbundenen Probleme diskutieren, insbesondere wenn die Datensatzgröße zunimmt:
- Leistung: Wie bereits erwähnt, berechnet die brute-force Vector-Suche die Distanz zwischen einem Abfragevektor und allen Vektoren in der Datenbank. Sie funktioniert gut für kleinere Datensätze, aber wenn die Anzahl der Vektoren auf Millionen von Einträgen ansteigt, wächst die Suchzeit und der Rechenaufwand, um die Distanz zwischen den Millionen von Einträgen zu finden.
- Skalierbarkeit: Die Datenmenge wächst exponentiell, was es für die brute-force Vector-Suche sehr schwierig macht, Ergebnisse mit derselben Geschwindigkeit und Genauigkeit bei der Abfrage großer Datensätze zu erzielen. Dies erfordert innovative Möglichkeiten, um umfangreiche Daten zu verwalten und gleichzeitig Geschwindigkeit und Genauigkeit beizubehalten.
- Kombination mit strukturierten Daten: In einfachen Anwendungen wird entweder eine SQL-Abfrage zur Abfrage strukturierter Daten oder eine Vector-Suche zur Abfrage unstrukturierter Daten verwendet, aber Anwendungen erfordern oft die Fähigkeiten beider Ansätze. Die Integration dieser beiden kann technisch herausfordernd sein, insbesondere wenn sie in verschiedenen Systemen verarbeitet werden. Wenn wir Vector-Suche nutzen und gleichzeitig SQL WHERE-Klauseln für die Filterung anwenden, erhöht sich die Abfrageverarbeitungszeit aufgrund der erhöhten Vielfalt und Größe der Daten.
Als Lösung für diese Herausforderungen stehen effiziente Vector-Indexierungstechniken zur Verfügung.
# Häufig verwendete Vector-Indexierungstechniken
Um den Herausforderungen großer Vektordaten gerecht zu werden, werden verschiedene Indexierungstechniken eingesetzt, um effiziente approximative Vector-Suchen zu organisieren und zu erleichtern. Werfen wir einen Blick auf einige dieser Techniken.
# Hierarchical Navigable Small World (HSNW)
Der HNSW-Algorithmus nutzt eine mehrschichtige Graphenstruktur, um Vektoren zu speichern und effizient durchsuchen zu können. Auf jeder Ebene sind Vektoren nicht nur mit anderen Vektoren auf derselben Ebene verbunden, sondern auch mit Vektoren in den darunter liegenden Ebenen. Diese Struktur ermöglicht eine effiziente Erkundung von benachbarten Vektoren, während der Suchraum überschaubar bleibt. Die oberen Ebenen enthalten nur eine geringe Anzahl von Knoten, während die Anzahl der Knoten exponentiell abnimmt, wenn wir die Hierarchie hinabsteigen. Die unterste Ebene umfasst schließlich alle Datenpunkte in der Datenbank. Diese hierarchische Gestaltung definiert die charakteristische Architektur des HNSW-Algorithmus.
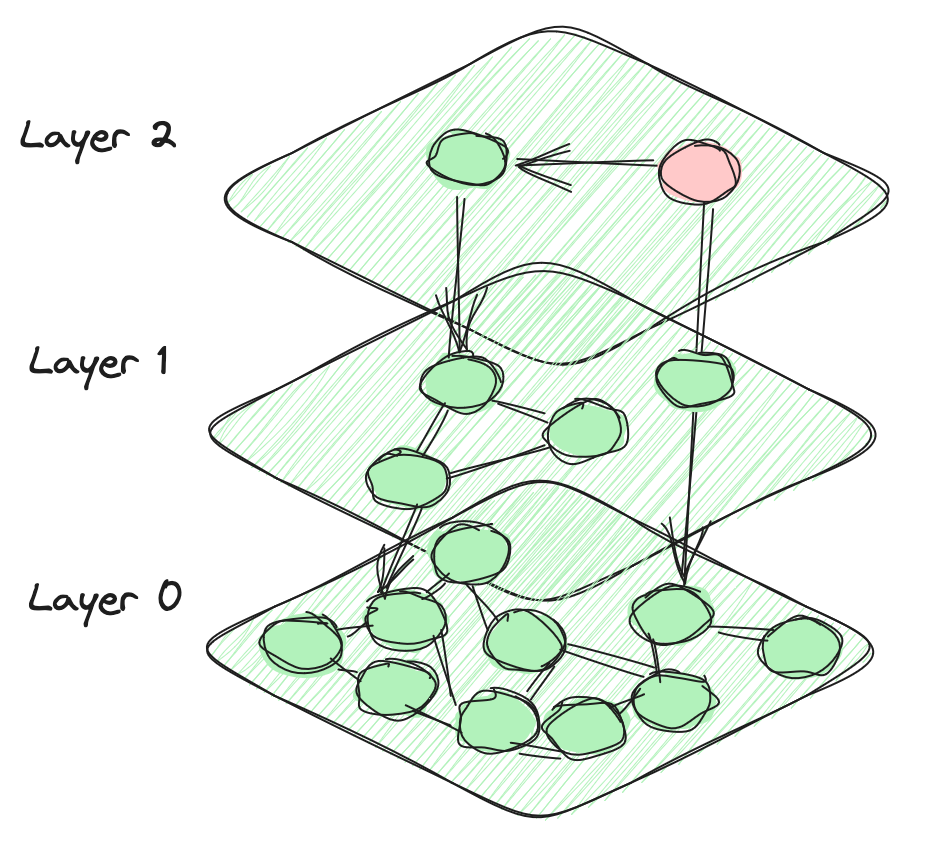
Der Suchprozess beginnt mit einem ausgewählten Vektor, von dem aus die Distanzen zu verbundenen Vektoren sowohl in der aktuellen als auch in den vorhergehenden Ebenen berechnet werden. Diese Methode ist gierig und bewegt sich kontinuierlich auf den Vektor zu, der der aktuellen Position am nächsten ist, und iteriert, bis ein Vektor identifiziert wird, der unter allen verbundenen Vektoren am nächsten liegt. Obwohl der HNSW-Index in der Regel bei einfachen Vector-Suchen hervorragende Leistungen erbringt, erfordert er erhebliche Ressourcen und benötigt viel Zeit für den Aufbau. Darüber hinaus kann die Genauigkeit und Effizienz von gefilterten Suchen unter diesen Bedingungen aufgrund einer verringerten Graphenvernetzung erheblich abnehmen.
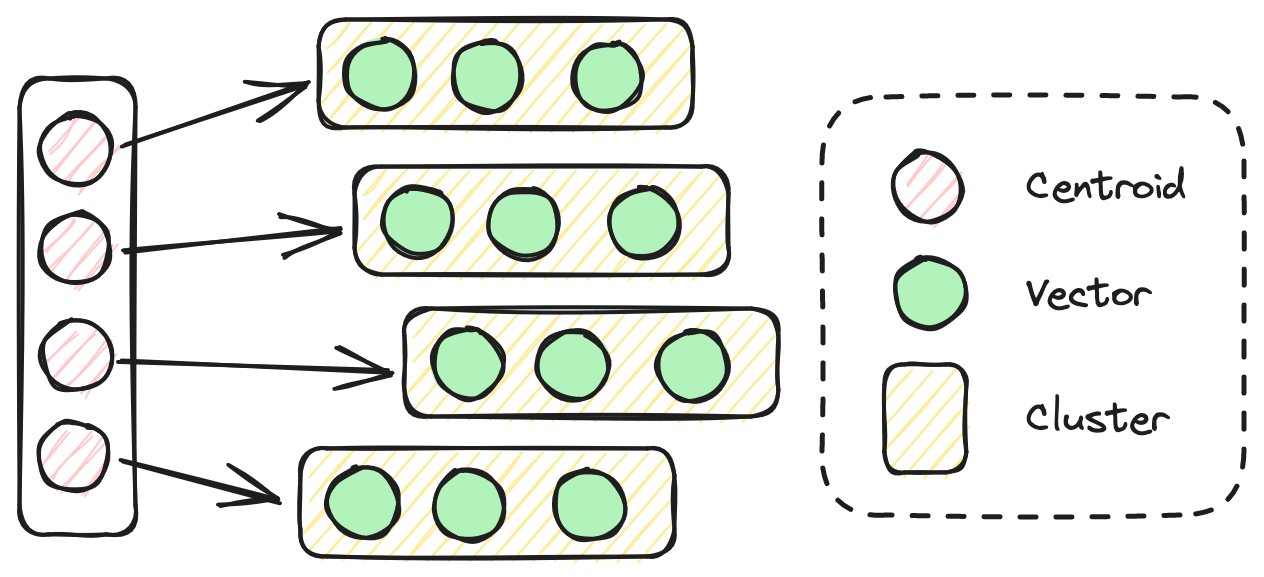
# Inverted Vector File (IVF) Index
Der IVF-Index verwaltet hochdimensionale Datensuchen effizient, indem er Clusterzentroide als invertierten Index verwendet. Er segmentiert Vektoren basierend auf geometrischer Nähe in Cluster, wobei das Zentroid jedes Clusters als vereinfachte Darstellung dient. Bei der Suche nach den ähnlichsten Elementen zu einem Abfragevektor identifiziert der Algorithmus zunächst die dem Abfragevektor am nächsten gelegenen Zentroide. Anschließend sucht er nur innerhalb der zugehörigen Liste von Vektoren für diese Zentroide, anstatt den gesamten Datensatz zu durchsuchen. IVF benötigt weniger Zeit zum Aufbau im Vergleich zu HSNW, erzielt jedoch auch eine geringere Genauigkeit und Geschwindigkeit während des Suchprozesses.


# MyScale in Aktion: Lösungen und praktische Anwendungen
Als SQL-Vector-Datenbank ist MyScale (opens new window) darauf ausgelegt, komplexe Abfragen zu verarbeiten, schnelle Datenabrufe zu ermöglichen und große Datenmengen effizient zu speichern. Was MyScale gegenüber spezialisierten Vector-Datenbanken (opens new window) auszeichnet, ist die Kombination einer schnellen SQL-Ausführungsmaschine (basierend auf ClickHouse) mit unserem proprietären Multi-scale Tree Graph (MSTG)-Algorithmus. MSTG vereint die Vorteile von Baum- und graphenbasierten Algorithmen und ermöglicht es MyScale, schnell zu bauen und schnell zu suchen, Geschwindigkeit und Genauigkeit bei unterschiedlichen gefilterten Suchverhältnissen beizubehalten und dabei Ressourcen- und Kosteneffizienz zu gewährleisten.
Werfen wir nun einen Blick auf mehrere praktische Anwendungen, in denen MyScale sehr hilfreich sein kann:
- Wissensbasierte QA-Anwendungen: Bei der Entwicklung eines Frage-Antwort- (QA-) Systems ist MyScale eine ideale Vector-Datenbank mit der Fähigkeit zur Selbstabfrage sowie flexibler Filterung für hoch relevante Ergebnisse aus Ihren Dokumenten. Darüber hinaus zeichnet sich MyScale durch Skalierbarkeit aus, sodass Sie problemlos mehrere Benutzer gleichzeitig verwalten können. Weitere Informationen finden Sie in unserer abstraktiven QA (opens new window) Dokumentation. Darüber hinaus können Sie Selbstabfragen mit fortschrittlichen Algorithmen nutzen, um die Genauigkeit und Geschwindigkeit Ihrer Suchergebnisse zu verbessern.
- Groß angelegter KI-Chatbot: Die Entwicklung eines groß angelegten Chatbots ist eine anspruchsvolle Aufgabe, insbesondere wenn Sie zahlreiche Benutzer gleichzeitig verwalten müssen und sicherstellen möchten, dass sie separat behandelt werden. Darüber hinaus muss der Chatbot genaue Antworten liefern. MyScale hat durch seine SQL-kompatible rollenbasierte Zugriffskontrolle (opens new window) und groß angelegte Mandantenfähigkeit (opens new window) durch Datenpartitionierung und gefilterte Suche das Erstellen von Chatbots (opens new window) vereinfacht, sodass Sie mehrere Benutzer verwalten können.
- Bildsuche: Wenn Sie ein System entwickeln, das eine semantische oder ähnliche Bildsuche durchführt, kann MyScale Ihre wachsenden Bilddaten problemlos verarbeiten und dabei leistungsfähig und ressourceneffizient bleiben. Sie können auch komplexere SQL- und Vektor-Join-Abfragen schreiben, um Bilder anhand von Metadaten oder visuellem Inhalt abzugleichen. Weitere Informationen finden Sie in unserer Bildsuchprojekt (opens new window) Dokumentation.
Neben diesen praktischen Anwendungen können Sie durch die Integration von MyScale's SQL- und Vektorfähigkeiten fortschrittliche Empfehlungssysteme (opens new window), Objekterkennungsanwendungen (opens new window) und vieles mehr entwickeln.
# Fazit
Vector Search übertrifft die traditionelle Begriffsübereinstimmung, indem es die Semantik innerhalb von Vektoreinbettungen interpretiert. Dieser Ansatz ist nicht nur für Texteffekte, sondern erstreckt sich auch auf Bilder, Audio und verschiedene multimodale unstrukturierte Daten, wie sie in Modellen wie ImageBind (opens new window) demonstriert werden. Diese Technologie steht jedoch vor Herausforderungen wie dem Rechenaufwand und dem Speicherbedarf sowie der semantischen Unschärfe hochdimensionaler Vektoren. MyScale löst diese Probleme, indem es SQL und Vector-Suche innovativ zu einem vereinheitlichten, leistungsstarken, kosteneffizienten System verschmilzt. Diese Fusion ermöglicht eine Vielzahl von Anwendungen, von QA-Systemen über KI-Chatbots bis hin zur Bildsuche, und zeigt ihre Vielseitigkeit und Effizienz.
Schließlich heißen wir Sie herzlich willkommen, sich mit uns auf Twitter (opens new window) und Discord (opens new window) zu verbinden. Wir freuen uns darauf, Ihre Erkenntnisse zu hören und zu diskutieren.



