
As data volumes and complexity continue to grow, scalable NoSQL database solutions are becoming a trending alternative to traditional relational databases. One type that is generating a lot of interest is the vector database. Promising advanced semantic search capabilities, vector databases utilize high-dimensional vector search rather than traditional SQL queries to organize and retrieve data based on its meaning and similarity.
Before choosing a vector database, there are some key factors you need to consider carefully to ensure it will meet your application and analytics requirements both now and in the future. That’s what we will discuss in this blog. These factors are divided into three major categories: the core functionalities of a vector database, the operational considerations, and the usability and ecosystem. Let's get started!
# Core Functionalities
The core functionalities of a vector database include performance, indexing methods, query language and API support, and data model and schema.
# Performance
When selecting a vector database, performance is crucial as it ensures smooth application operation, facilitating efficient searches for similar items, nearest neighbor vectors, and data analysis. The performance of a vector database can be measured through the following factors:
- Number of Queries Per Second (QPS): This measures how many queries your database can handle in a second. A higher QPS means the database can support more concurrent searches, crucial for applications requiring real-time data analysis or user interactions.
- Average Query Latency: It's about how long it takes for the database to return a result after a query is made. Lower latency ensures that your application feels faster and more responsive to the user, enhancing the overall user experience.
- Data Ingestion Time: The speed with which new data can be added to the database is vital, especially in dynamic environments where data is constantly being updated. Efficient data ingestion ensures that your database is always up-to-date and ready for queries.
MyScaleDB is a vector database with outstanding performance compared to other vector databases. For larger datasets, MyScaleDB now reports an enhanced performance (opens new window) with 390 QPS (Queries Per Second) on the LAION 5M dataset, achieving a 95% recall rate and maintaining an average query latency of 18ms with the x1 pod.
MyScaleDB also outperformed other vector databases in data ingestion time by completing tasks in almost 30 minutes for 5M data points. If you sign up, you get to use the x1 pod for free, which can handle up to 5 million vectors.
Related Artilcle: How MyScale Outperformes other specialized vector databases? (opens new window)
# Indexing Method
The key to a vector database is how it processes the high-dimensional vector data. Different vector databases use different indexing methods to make sure that data can be found quickly and accurately, keeping everything organized and efficient. Here are some common indexing methods in vector databases:
- k-d trees are tree structures used for indexing points in a k-dimensional space. They are particularly useful for multidimensional data, such as vectors. k-d trees partition the space into regions, facilitating quick nearest-neighbor searches.
- Ball trees are similar to k-d trees but effective for datasets with variable densities. They represent the dataset by enclosing points within hyperspheres, making them suitable for applications like nearest-neighbor searches.
- Locality-sensitive hashing (LSH) is a probabilistic method to hash input items so that similar items map to the same buckets with high probability. It is useful for approximate similarity searches, which makes it suitable for applications like recommendation systems.
- Graph-based index represents data as a graph, where nodes and edges are represented as vectors and relationships. This index is beneficial for capturing complex relationships and is often used in applications such as social network analysis.
- Inverted File (IVF) vector index is a method for efficient similarity search in high-dimensional vector spaces, using clustering to partition the vectors into Voronoi cells, where each cell corresponds to a centroid, and an inverted index is built to quickly locate vectors within a given cell during queries.
- Product quantization (PQ) method divides vectors into smaller subvectors and quantizes them independently. It's efficient for high-dimensional data and is often used in image retrieval applications. PQ can be effectively combined with graph-based index as well as IVF.
- Spatial hashing involves dividing the vector space into cells and assigning each vector to a cell based on its location. This method is useful for spatial queries and is commonly used in computer graphics and computer-aided design.
Many algorithms face limitations, especially when there's a significant increase in index size for massive datasets, which requires storing all the vector data in memory. Multi-Scale Tree Graph (MSTG) (opens new window) is developed by MyScaleDB and it overcomes the limitations by combining hierarchical tree clustering with graph traversal, and memory with fast NVMe SSDs. MSTG significantly reduces the resource consumption of IVF/HNSW while retaining exceptional performance. It builds fast, searches fast, and remains fast and accurate under different filtered search ratios while being resource and cost-efficient.
# Query Language and API Support
The query language and application programming interface (API) support define how users interact with and retrieve information from the database. They are crucial factors in evaluating whether a vector database is user-friendly, adaptable, and seamlessly integrable within diverse technological ecosystems. These components empower users to extract valuable insights by interacting with the database, enabling a smooth and effective data management experience.
MyScaleDB is an all-in-one vector database and fully compatible with SQL, which not only simplifies complex data operations, semantic search and structured data query through SQL, but also makes it ideal for almost all developers to leverage existing SQL knowledge to get started with a vector database and does data tasks. At the same time, MyScaleDB's API support facilitates automation and integration with other systems.
# Data Model and Schema
The data model and schema of a vector database are its blueprints that dictate how data is stored and accessed. This impacts on storage efficiency, query performance, scalability, and developer experience. MyScaleDB uses a hybrid data model that combines the strengths of structured and vector data representations, which means it can effectively store tabular data (like traditional databases) and high-dimensional vectors as well.
# Operational Considerations
Let’s discuss scalability, security and monitoring as operational considerations of a vector database.
# Scalability
Scalability refers to its ability to handle increasing data volume and user demands without compromising performance or functionality. In vector databases, there are two types of scaling: vertical scaling and horizontal scaling. Vertical scaling means expanding the computational power of hardware and software. Meanwhile, horizontal scaling means the addition of additional server nodes. It is crucial for future-proofing your vector database and ensuring it can support the growth of your AI applications. MyScaleDB provides vertical scaling.
# Security
Security in a vector database contains various aspects that protect both the data itself and the functionality of the database system. Look for features like encryption, access controls, authentication mechanisms, network security, and disaster recovery in your vector database because they act as the digital shield that keeps your data safe and sound.
MyScaleDB is trusted by teams and organizations like yours for a variety of reasons.
- MyScaleDB runs on a multi-tenant Kubernetes cluster on a fully-managed and secure AWS infrastructure.
- It ensures customer data is stored in isolated containers.
- Access to your data for any reason beyond API service calls is strictly prohibited.
- MyScaleDB exclusively monitors operational metrics to maintain system health and performance.
- MyScaleDB has achieved SOC 2 Type 1 compliance, meeting the world's top standard for keeping information safe.
# Monitoring
Monitoring plays a crucial role in choosing a vector database for multiple reasons. It provides us insights and progress tracking to make timely decisions for performance optimization, continuous improvement, and adaptability.
MyScaleDB offers comprehensive monitoring tools to track performance metrics, resource utilization, and security events, providing real-time insights into your database's health and activity.
Related Article: Performance Gain with Retrieval Augmented Generation (opens new window)
# Usability and Ecosystem
Usability and ecosystem comprises pricing, documentation, community, support, and ecosystem integration.
# Community and Support
Community support plays a vital role in using vector databases effectively. It empowers users, encourages collaboration, and contributes to the ongoing improvement and success of vector database implementations across various applications and industries. It also helps in debugging issues and asking queries for clarifications. You can get responses from MyScaleDB's technical experts promptly across multiple channels like Discord (opens new window), Twitter (opens new window), LinkedIn (opens new window), and Medium (opens new window).
# Pricing
Pricing is a major factor behind the selection of a vector database. A clear understanding of pricing ensures a cost-effective and sustainable relationship with the vector database. Look into the pricing models offered by different databases and assess how they align with your budget and usage requirements.
MyScaleDB offers multiple pricing options (opens new window), including free-of-cost services to individuals for small applications. It also offers a standard package for AI services and an enterprise package for large organizations. MyScaleDB charges for storage and computation separately, meaning the computation fee is charged only when queries run. And recently, MyScaleDB released a new capacity-optimized pod for just $68/mo that can host 10M 768D vectors, making it easier than ever to create powerful GenAI apps without breaking the bank.
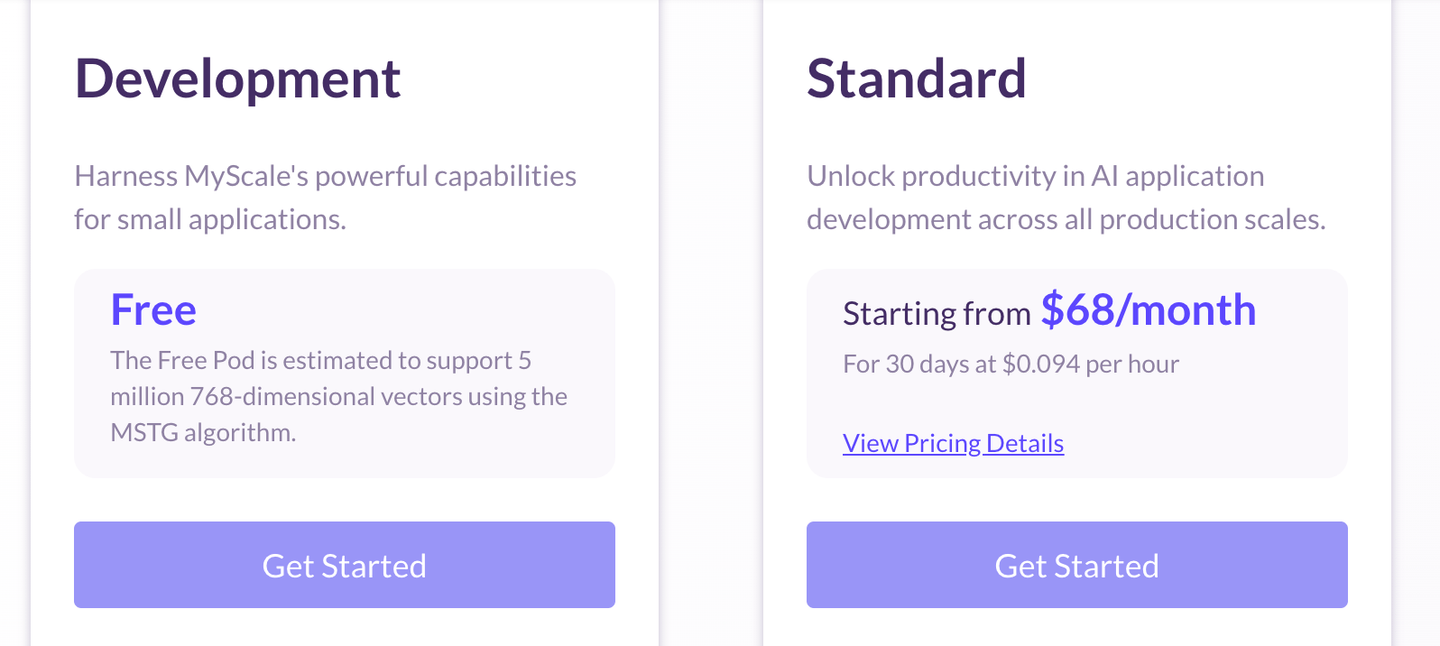
If you have an estimate of the size of your data vector, you can also calculate the price using the price estimator.
# Ecosystem Integrations
Let's discuss the ecosystem integrations below:
Developer Tools: Developer tools are crucial in choosing the right vector database for your project. It can boost productivity and efficiency by integrating existing developer tools you are comfortable with. MyScaleDB has integrated various developer tools such as Python Client (opens new window), Node.js (opens new window), Go Client (opens new window), ClientJDBC Driver (opens new window), and HTTPS Interface (opens new window).
Large language models (LLM): LLM integration significantly expands the capabilities of a vector database by unlocking advanced semantic search, contextualization of data, personalized recommendations, knowledge augmentation, and conversational interfaces. MyScaleDB provides multiple LLM integrations, including OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window), and LlamaIndex (opens new window).
Related Article: Advanced Facebook Event Data Analysis with a Vector Database (opens new window)
# Documentation
The availability of detailed documentation is important in selecting a vector database. It helps in understanding functionality, efficient development, integration, long-term support, and ensuring a smooth learning curve.
MyScaleDB provides extensive and well-detailed documentation that covers user guides (opens new window), tutorials (opens new window), blogs (opens new window), sample applications (opens new window) and API integration (opens new window) docs, and active support channels like Discord and Twitter.

# Comparison
Let’s compare MyScaleDB with some popular vector databases.
| Features | MyScaleDB | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| Open-source | Yes | No | Yes | Yes | Yes |
| SQL | Yes | No | No | No | No |
| Cloud deployment | Yes | Yes | Yes | Yes | Yes |
| Query languages | SQL & SDKs | SDKs | GraphQL | C++, Python SDKs | SDKs |
| LLM integration | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain |
| Cost | Free & Paid tiers | Paid tiers | 14-day free & Paid tiers | Paid tiers | Free & Paid tiers |
# Conclusion
It's not easy to select a right vector database, we've discussed different factors you can consider before selecting any vector database, including three major categories that cover core functionalities, operational considerations, usability and ecosystem integration.
Furthermore, if efficient handling of large-scale data volumes and dealing with data complexity are your top-tier selection criteria, consider using MyScaleDB. By combining the strengths of ClickHouse and the MSTG algorithm, MyScaleDB provides cost-effective solutions for complex and large-scale vector searches in both speed and precision.
You can find benchmark reports between MyScaleDB and other competitors in the following content as well:



