
世界のデータは爆発的に成長し、2025年までに181ゼタバイトに達する (opens new window)と予測されています。そのうち80%は構造化されていないデータですが、これは従来のデータベースにとっては効果的に処理できない課題となっています。フルテキスト検索は、ユーザーがトピックやキーアイデアに基づいて検索することができる直感的で効率的な構造化されていないテキストデータへのアクセスを可能にします。
MyScaleDB (opens new window)は、ベクトル検索に最適化されたClickHouseのオープンソースフォークであり、Tantivy (opens new window)というフルテキスト検索エンジンライブラリの統合により、テキスト検索の機能を大幅に強化しました。
このアップグレードにより、ClickHouseをログとして使用し、ElasticsearchやLokiの代替として頻繁に使用しているユーザーや、ベクトル検索とテキスト検索を組み合わせて精度を向上させるためにMyScaleDBを利用しているユーザーに大きな利益がもたらされます。
この記事では、統合プロセスの技術的な詳細と、それがMyScaleDBのパフォーマンス向上にどのように貢献しているかについて探っていきます。
# ClickHouseのネイティブテキスト検索の制限
ClickHouseは、hasToken、startsWith、multiSearchAnyなどの基本的なテキスト検索関数を提供しており、シンプルな用語クエリのシナリオには適しています。しかし、フレーズクエリや曖昧なテキストマッチング、BM25の関連度ランキングなどのより複雑な要件には対応していません。そのため、MyScaleDBでは、フルテキストインデックスの基礎としてTantivyを導入し、MyScaleDBにフルテキスト検索の機能を付加しました。Tantivyのフルテキストインデックスは、曖昧なテキストクエリやBM25の関連度ランキングをサポートし、hasTokenやmultiSearchAnyの用語マッチングを高速化します。
# Tantivyを選んだ理由
Tantivyは、Rustで書かれたオープンソースのフルテキスト検索エンジンライブラリです。大量のテキストデータを効率的に処理するために設計されています。
# Tantivyの主な原則を理解する
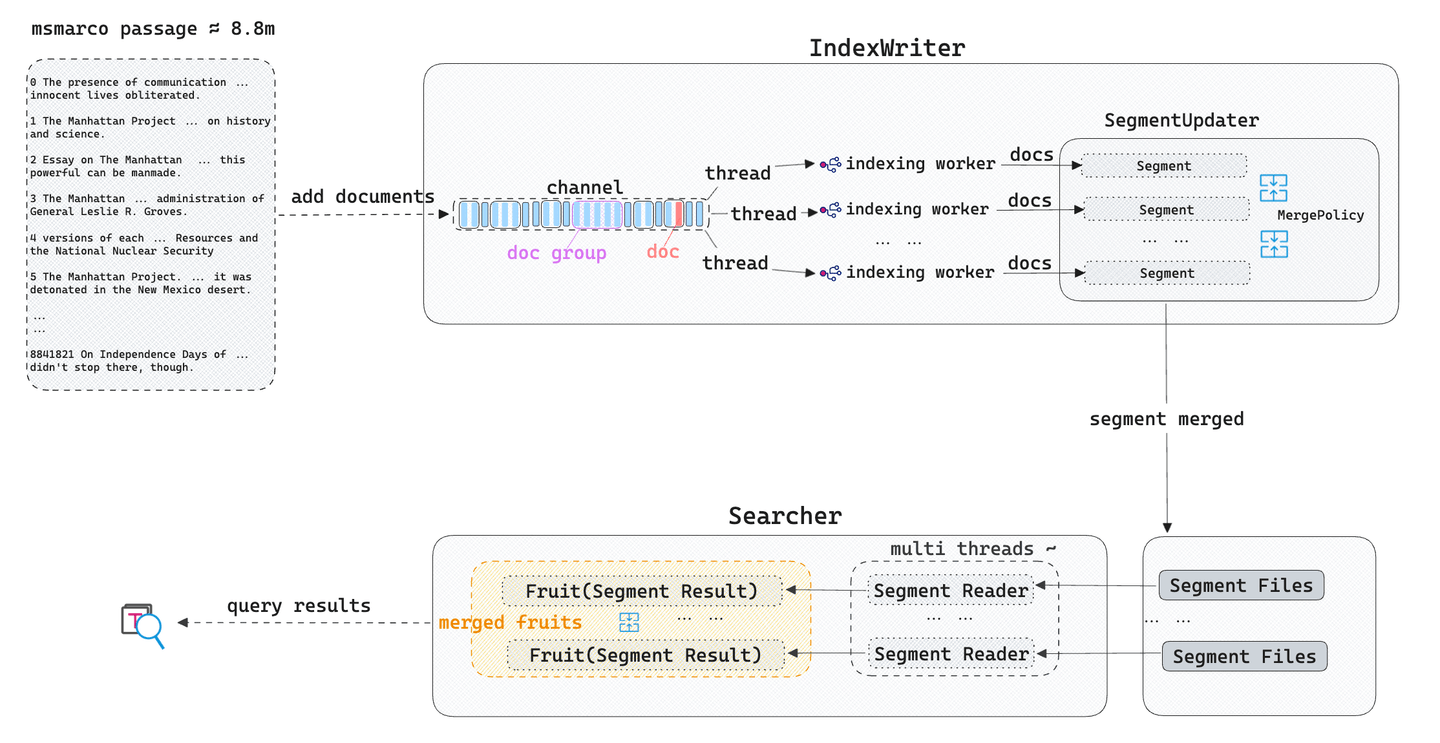
インデックスの構築: Tantivyは入力テキストをトークンに分割し、独立したトークンに分割します。そして、逆インデックス(ポスティングリスト)を作成し、それをインデックスファイル(セグメント)に書き込みます。同時に、Tantivyのバックグラウンドスレッドはマージ戦略を使用してこれらのセグメントインデックスファイルをマージおよび更新します。
テキスト検索の実行: ユーザーがテキスト検索クエリを開始すると、Tantivyはクエリ文を解析し、トークンを抽出し、各セグメントでクエリ条件とBM25関連度アルゴリズムに基づいてドキュメントをソートおよびスコアリングします。最終的に、これらのセグメントからのクエリ結果は関連度スコアに基づいてマージされ、ユーザーに返されます。
# Tantivyの主な機能
- BM25関連度スコアリング: Elasticsearch、Lucene、Solrはすべて、デフォルトの関連度ランキングアルゴリズムとしてBM25を使用しています。BM25スコアは、テキスト検索の正確性と関連性を評価し、ユーザーの検索体験を向上させます。
- 設定可能なトークナイザ: 様々な言語のトークナイザをサポートし、ユーザーの多様なトークン化ニーズに対応します。
- 自然言語クエリ: ユーザーはAND、OR、INなどのキーワードを使用して柔軟にテキストクエリを組み合わせることができ、SQL文の複雑さを軽減します。
その他の機能については、Tantivyのドキュメント (opens new window)を参照してください。
# MyScaleDBとのシームレスな統合
C++で書かれたMyScaleDBは、ClickHouseを基盤として開発されたAIネイティブアプリケーション向けの堅牢な検索エンジンです。MyScaleDBのフルテキスト検索機能を強化するためには、MyScaleDBに直接組み込むことができるライブラリが必要でした。
Tantivyは、Apache Luceneに触発されたフルテキスト検索ライブラリです。ElasticsearchやApache Solrなどの他のエンジンとは異なり、TantivyはMyScaleDBなどのさまざまなデータベースに統合することができます。TantivyはRustプログラミング言語で書かれており、C++プログラムとはCorrosion (opens new window)を使用して簡単に統合することができます。
# 統合プロセス
# TantivyのためのC++ラッパーの作成
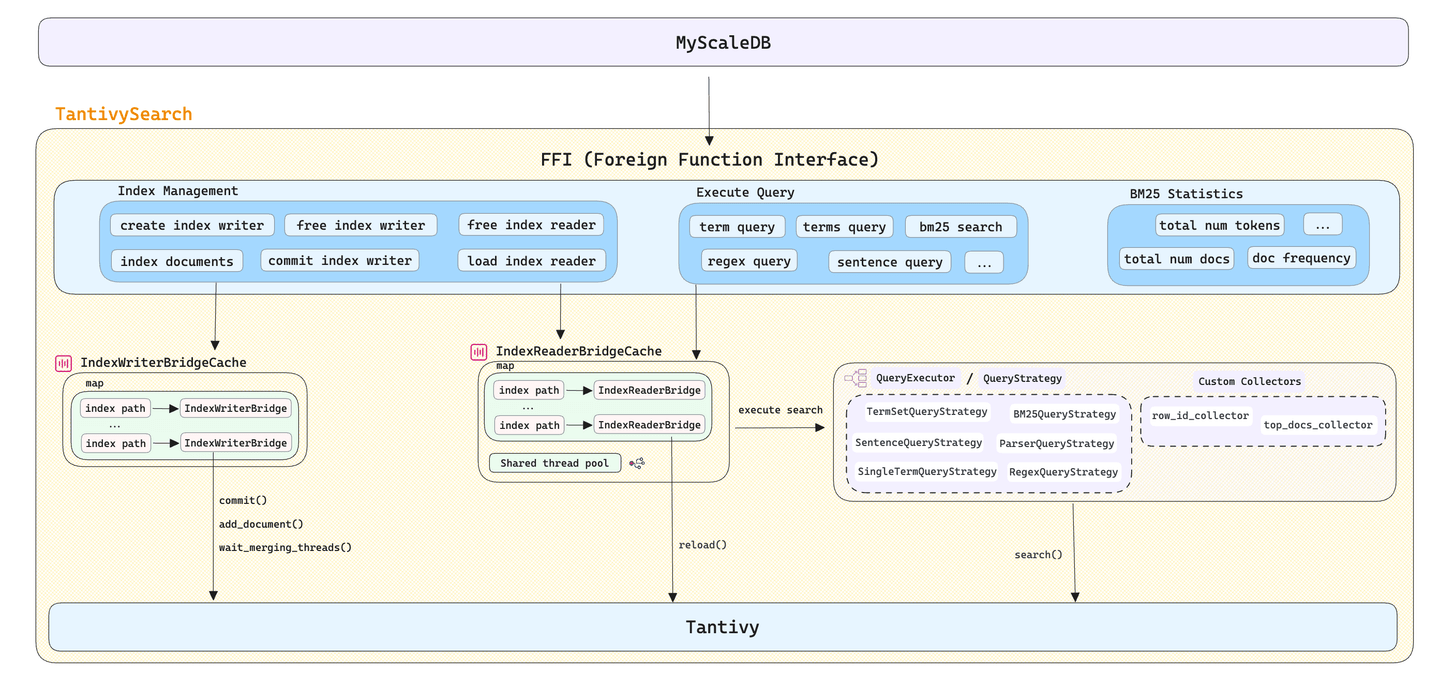
MyScaleDBでは、Tantivyライブラリをそのまま使用することはできませんでした。クロス言語の開発(C++とRust)の課題に対処するために、tantivy-search (opens new window)というTantivyのC++ラッパーを開発しました。これにより、MyScaleDBのFFIインターフェースを提供し、インデックスの作成、破棄、ロードの直接的な管理、さまざまなシナリオでの柔軟なテキスト検索要件の処理が可能になりました。
# ClickHouseのスキッピングインデックスとしてのTantivyの実装
ClickHouseのスキッピングインデックス (opens new window)は、WHERE句を持つクエリの高速化に主に使用されます。私たちは、Tantivyを基礎とした新しいスキッピングインデックスのタイプであるFTS(フルテキスト検索)を実装しました。したがって、FTSインデックスを持つClickHouseの各データパートごとにTantivyインデックスを構築します。先に述べたように、Tantivyは各インデックスに複数のセグメントファイルを生成します。データパートに保存するファイルの数を減らすために、MyScaleDBはこれらのセグメントファイルを2つのファイルにシリアライズし、データパートに保存します。skp_idx_[index_name].metaファイルには各セグメントファイルの名前とオフセットが記録され、skp_idx_[index_name].dataファイルには各セグメントファイルの元のデータが保存されます。
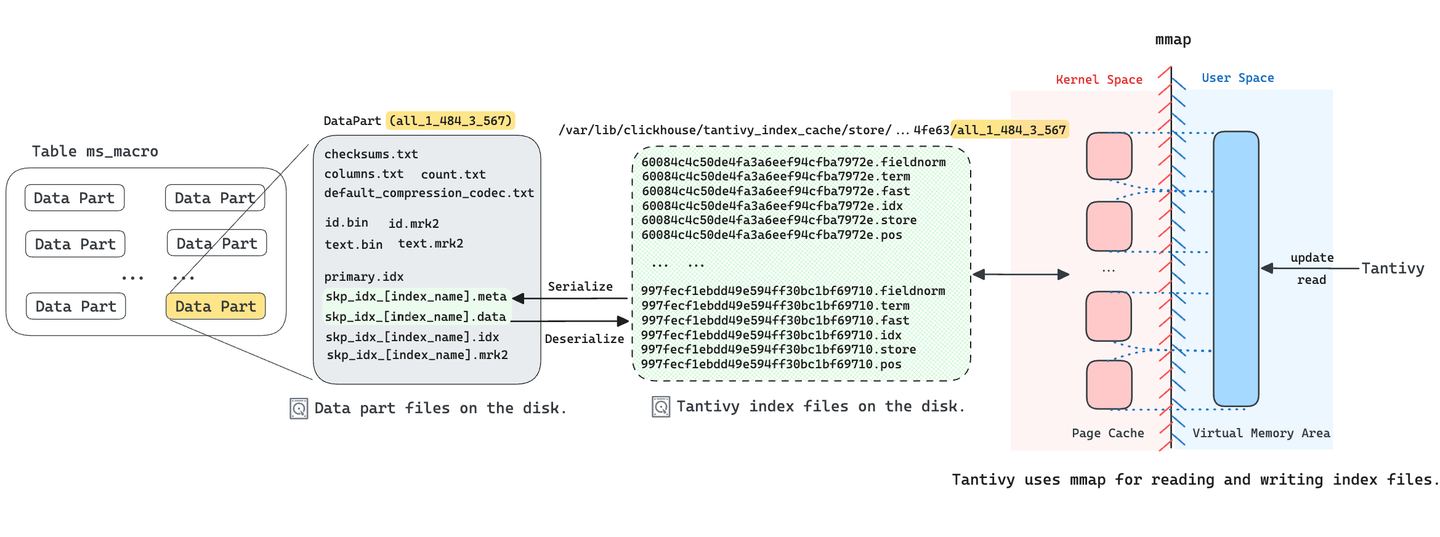
Tantivyはメモリマッピング(mmap)を使用してセグメントファイルにアクセスします。これにより、並行して検索する速度が向上し、インデックスの構築効率も向上します。しかし、Tantivyはskp_idx_[index_name].dataファイルを直接メモリにマップすることはできません。そのため、FTSインデックスが必要なクエリが発生した場合、MyScaleDBはインデックスファイル(.metaおよび.data)をTantivyセグメントファイルに逆シリアル化し、一時ディレクトリにロードします。これらの逆シリアル化されたセグメントファイルは、Tantivyによってメモリマッピングを介してロードされ、さまざまなタイプのテキスト検索を実行するために使用されます。したがって、ユーザーからの最初のクエリリクエストは数秒かかる場合があります。
マネージドMyScaleDBサービス (opens new window)では、TantivyのセグメントインデックスファイルをNVMe SSDに保存しています。これにより、I/O待ち時間が短縮され、ランダムアクセスとページフォルト例外の処理が必要なシナリオでのmmapのパフォーマンスが向上します。
# ClickHouseのネイティブテキスト検索関数の強化
フィルタ条件を含むリクエストがFTSインデックスを持つ列に対して初めて行われる場合、MyScaleDBはまずFTSインデックスにアクセスします。SQLのフィルタ条件を満たす列のすべての行IDを取得し、これらの行IDをroaring bitmap (opens new window)と呼ばれる高度なビットマップデータ構造に格納します。グラニュールをトラバースする際に、グラニュールの行ID範囲がビットマップと交差するかどうかを判断し、グラニュールをドロップできるかどうかを判断します。最終的に、MyScaleDBはドロップされていないグラニュールのみにアクセスし、クエリの高速化を実現します。
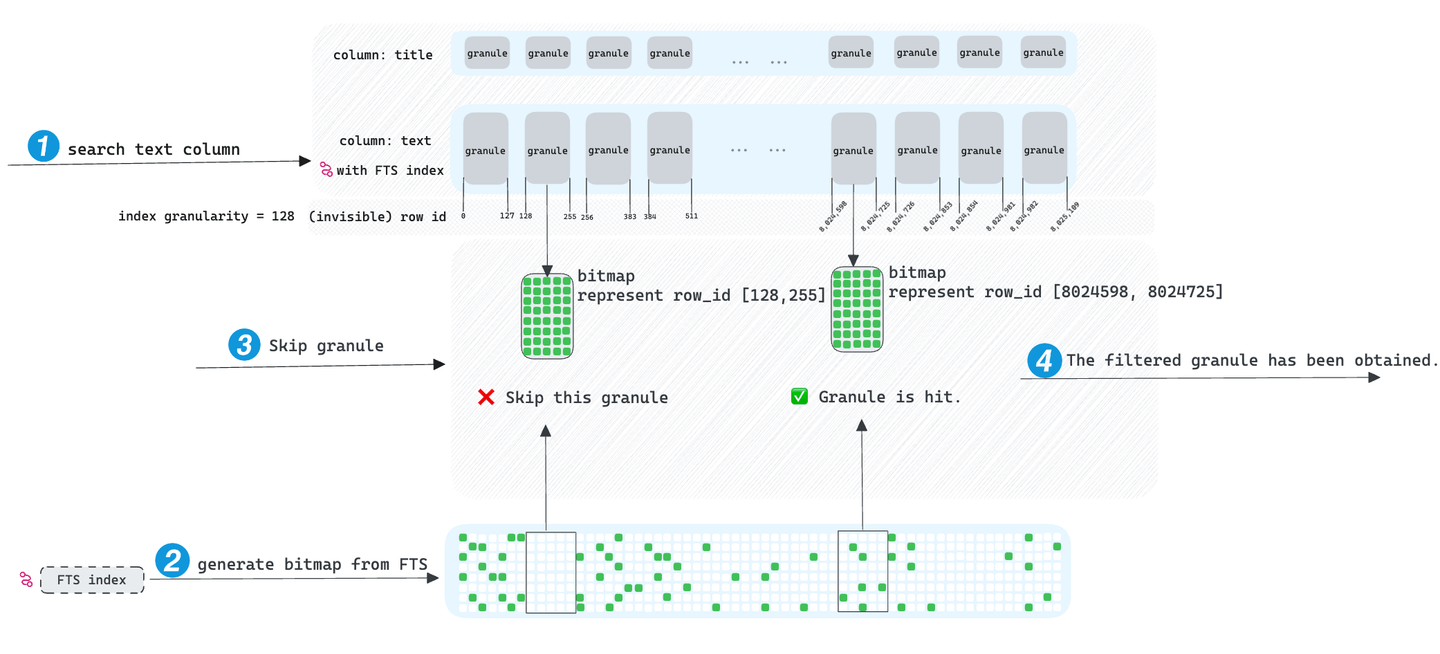
理想的には、スキッピングインデックスはクエリの高速化に貢献しますが、効果は限定的です。検索対象の用語がほとんどのグラニュールに出現する場合、MyScaleDBはごくわずかなグラニュールをスキップするだけであり、クエリに対して多数のグラニュールにアクセスする必要があります。そのため、このような場合にはスキッピングインデックスは効果がありません。一方、MyScaleDBはTextSearch関数を導入し、スキッピングインデックスの効率の低さを解消するだけでなく、他の実用的な機能も提供しています。
# TextSearch関数の導入
Tantivyのフルテキスト検索機能を最大限に活用するために、TextSearch関数をMyScaleDBに組み込みました。これにより、ユーザーは曖昧なテキスト検索リクエストを実行し、BM25スコアの関連度に基づいてソートされたドキュメントのセットを取得することができます。さらに、ユーザーはTextSearch関数内で自然言語クエリを使用することができ、SQLの記述の複雑さを大幅に軽減することができます。
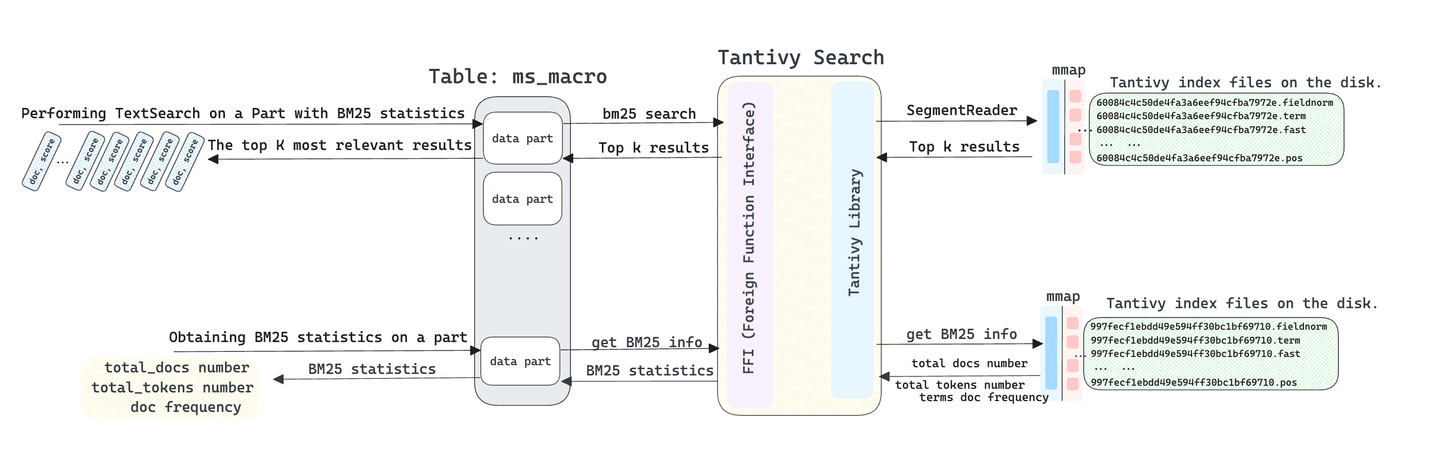
TextSearch関数は、テーブル内のテキストを検索する際に、上位K件の関連結果を取得します。実行に関しては、MyScaleDBはすべてのデータパートで並行してTextSearchテキスト検索を実行します。したがって、各パートはBM25スコアでソートされた上位K件の結果を収集します。その後、MyScaleDBはこれらのデータパートから得られた結果をBM25スコアに基づいて集約します。最後に、MyScaleDBはユーザーのSQLクエリで指定されたORDER BYおよびLIMIT節に従って、上位K件の結果を保持します。TextSearch関数はデータパート内のデータを直接読み取るのではなく、Tantivyを介してインデックスの検索結果を直接取得するため、非常に高速です。
重要な点として、MyScaleDBはデータを格納するために複数のデータパートを使用し、各データパートはテーブル全体の一部を格納する責任を持っています。各パートから得られた同じ回答テキストに対応するBM25スコアを単純に平均することはできません。なぜなら、各パートは現在のパート内の「総ドキュメント数」、「総トークン数」、「ドキュメントの頻度」のみを考慮してBM25スコアを計算し、他のパート内のBM25アルゴリズム関連のパラメータを考慮していないからです。そのため、最終的なマージ結果の精度が低下する可能性があります。
この問題に対処するために、TextSearchクエリを開始する前に、各パート内でBM25統計情報を計算します。そして、それらを論理的に対応するテーブル全体のBM25統計情報に統合します。さらに、Tantivyライブラリを修正して共有BM25情報の使用をサポートしました。これにより、複数のパート間でのTextSearch検索結果の正確性が保証されます。
以下は、ms_macroデータセットで基本的なテキスト検索を実行するためのTextSearch関数の簡単な例です。TextSearch関数の使用方法についての詳細は、TextSearchドキュメント (opens new window)を参照してください。
SELECT
id,
text,
TextSearch(text, 'who is Obama') AS score
FROM ms_macro
ORDER BY score DESC
LIMIT 5
出力:
| id | text | score |
|---|---|---|
| 2717481 | Sasha Obama Biography. Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.448088 |
| 5016433 | Sasha Obama Biography. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.407547 |
| 564474 | Michelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million.Michelle Obama was born January 17, 1964 in Chicago, Illinois.ichelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million. | 14.88242 |
| 5016431 | Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. | 14.63069 |
| 1939756 | Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $40 million. Michelle Obama was born January 17, 1964 in Chicago, Illinois. She is best known for being the wife of the 44th President of the United States, Barack Obama. She attended Princeton University, graduating cum laude in 1985, and went on to earn a law degree from Harvard Law School in 1988. | 14.230849 |

# パフォーマンス評価
clickhouse-benchmark (opens new window)を使用して、異なるインデックスを使用した場合のMyScaleDBの検索パフォーマンスを比較しました。評価には、MyScaleDBの実装されたFTSインデックス、ClickHouseの組み込みの逆インデックス、およびインデックスを設定しないシナリオを含めました。
# ベンチマークのセットアップ
# データセットの詳細
テキスト検索のパフォーマンスをテストするために、Microsoftが提供するms_macroデータセット (opens new window)を使用しました。ms_macroデータセットには8,841,823のテキストレコードが含まれており、これをParquet形式に変換してMyScaleDBに簡単にインポートできるようにしました。さらに、異なる単語の出現頻度に基づいて検索パフォーマンスをテストするためのSQLファイルのセットを作成しました。このテストで使用したデータセットにアクセスするためのS3へのリンクは以下の通りです。
- ms_macro_text.parquet (opens new window): 1.6GB
- ms_macro_query_files.tar.gz (opens new window): 5.8MB
ms_macro_query_files.tar.gzファイルには、このテストで使用されるすべてのSQLファイルが含まれています。たとえば、各SQLファイルの名前は、データセット内の検索語の出現頻度とSQLファイルに含まれるクエリの数を示しています。たとえば、ms_macro_count_hastoken_100_100k.sqlファイルには10万件のクエリが含まれており、各クエリの単語がデータセット内で100回出現します。
以下は、hasTokenおよびTextSearchクエリの例です。
SELECT count(*) FROM ms_macro WHERE hasToken(text, 'Crimp');
SELECT count(*) FROM (
SELECT TextSearch(text, 'Crimp') AS score
FROM ms_macro ORDER BY score DESC LIMIT 10000000
) as subquery;
# テスト環境
テスト環境には64GBのメモリが搭載されていますが、テスト中のMyScaleDBのメモリ消費量は約2.5GBにとどまっています。
| 項目 | 値 |
|---|---|
| システムバージョン | Ubuntu 22.04.3 LTS |
| CPU | 16コア(AMD Ryzen 9 6900HX) |
| メモリ速度 | 64GB |
| ディスク | 512GB NVMe SSD |
| MyScaleDB | v1.5 |
# データのインポート手順
ms_macroデータセットのためのテーブルを作成します。
CREATE TABLE default.ms_macro
(
`id` UInt64,
`text` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
S3からデータを直接MyScaleDBにインポートします。
INSERT INTO default.ms_macro
SELECT * FROM
s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/ms_macro_text.parquet','Parquet');
ms_macroのデータパートをマージして検索速度を向上させます。この操作はオプションです。
OPTIMIZE TABLE default.ms_macro final;
SELECT count(*) FROM system.parts WHERE table = 'ms_macro';
出力:
| count() |
|---|
| 1 |
ms_macroに8,841,823のレコードが含まれていることを確認します。
SELECT count(*) FROM default.ms_macro;
出力:
| count() |
|---|
| 8841823 |
# インデックスの作成
3種類のインデックスのパフォーマンスを評価します: FTS、Inverted、およびNone(インデックスを設定しないシナリオ)。
- FTSインデックスの作成
-- FTSインデックスを作成する際に、ms_macroのtext列に他のインデックスが存在しないことを確認してください。
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS fts_idx;
ALTER TABLE default.ms_macro ADD INDEX fts_idx text TYPE fts;
ALTER TABLE default.ms_macro MATERIALIZE INDEX fts_idx;
- Invertedインデックスの作成
-- Invertedインデックスを作成する際に、ms_macroのtext列に他のインデックスが存在しないことを確認してください。
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS inverted_idx;
ALTER TABLE default.ms_macro ADD INDEX inverted_idx text TYPE inverted;
ALTER TABLE default.ms_macro MATERIALIZE INDEX inverted_idx;
- Noneインデックス: ms_macroテーブルのtext列にはインデックスが存在しないことを確認してください。
# ベンチマークの実行
clickhouse-benchmarkを使用してストレステストを実行します。詳細な使用方法については、ClickHouseのドキュメント (opens new window)を参照してください。
clickhouse-benchmark -c 8 --timelimit=60 --randomize --log_queries=0 --delay=0 < ms_macro_count_hastoken_100_100k.sql -h 127.0.0.1 --port 9000
# 評価結果
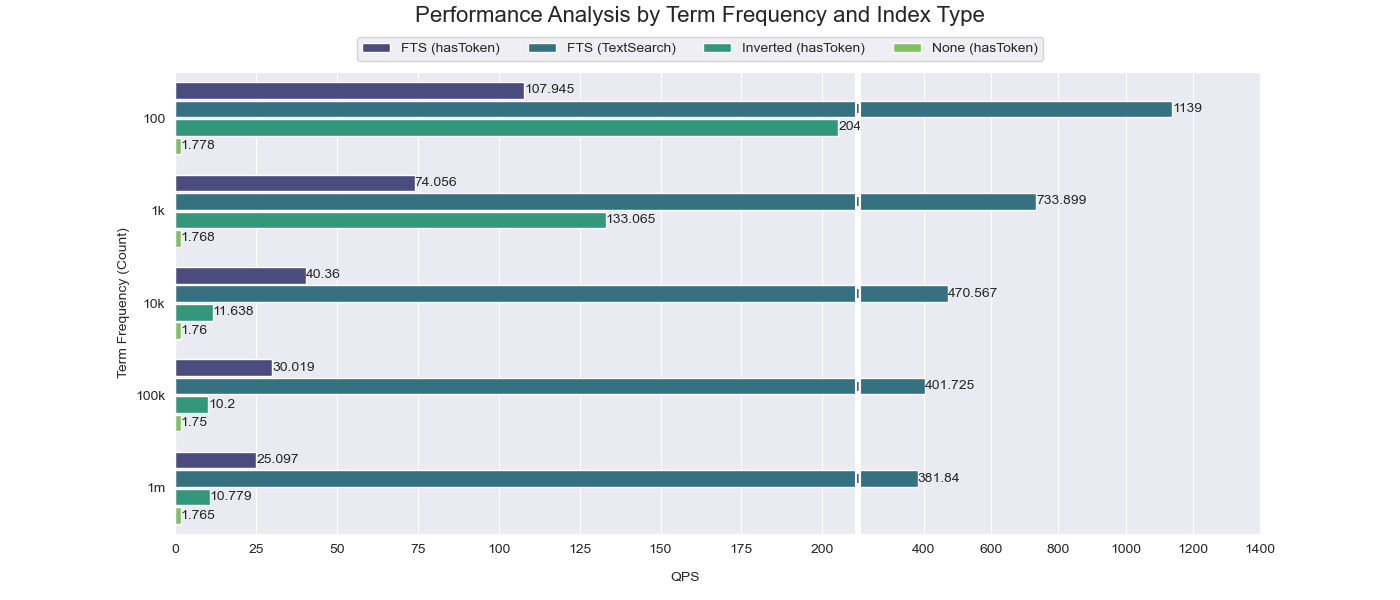
比較結果から明らかなように、検索語の出現頻度が高い場合(100K〜1M)、スキッピングインデックスの効果は非常に限定的です(インデックスを設定しない場合と比較して10倍の改善にとどまります)。しかし、検索語の出現頻度が低い場合(100〜1K)、スキッピングインデックスは大幅な高速化効果を実現できます(インデックスを設定しない場合と比較して100倍の改善があります)。
一方、TextSearch関数は、すべてのシナリオでスキッピングインデックスと逆インデックスを常に上回るパフォーマンスを発揮します。これは、TextSearchがTantivyのフルテキスト検索機能を直接活用し、グラニュールをスキャンする必要がなく、代わりにインデックスから結果を直接取得するためです。これにより、より高速かつ効率的な検索プロセスが実現されます。
# 結論
TantivyをMyScaleDBに統合することで、テキスト検索の機能が大幅に強化され、テキストデータの分析や大規模な言語モデル(LLM)を使用した検索増強生成(RAG)において強力なツールとなりました。ClickHouseのネイティブテキスト検索関数の制限を解消し、BM25関連度スコアリング、設定可能なトークナイザ、自然言語クエリなどの高度な機能を導入することで、MyScaleDBは複雑なテキスト検索要件に対する堅牢で効率的なソリューションを提供します。
TantivyのためのC++ラッパーの実装、新しいスキッピングインデックスの作成、およびTextSearch関数の導入が、この改善に貢献しています。これらの強化は、MyScaleDBのパフォーマンスを向上させるだけでなく、さまざまなアプリケーションで効率的かつ正確なテキスト検索を実現するための選択肢としてのMyScaleDBの利用範囲を拡大しています。
TextSearch関数やその他の機能の使用方法についての詳細は、テキスト検索 (opens new window)およびハイブリッド検索 (opens new window)のドキュメントを参照してください。
この記事がMyScaleDBの統合プロセスとその利点についての有益な情報を提供できたことを願っています。MyScaleDBの機能をさらに向上させるためのさまざまなアップデートや改善にご期待ください。



