
ChatGPT (opens new window)や他の大規模言語モデル(LLM) (opens new window)は、人間のようなテキストの理解と生成において大きな進歩を遂げています。しかし、特に急速に変化するまたは専門化された分野では、正確性と関連性を維持するのが難しいことがあります。これは、大きなが固定されたデータセットに依存しているためです。このようなデータセットはすぐに時代遅れになる可能性があります。ここで、ベクトルデータベース (opens new window)が役立ちます。ベクトルデータベースは、これらのモデルを最新の状態に保ち、文脈に即した情報を提供する方法を提供します。
ベクトルデータベースは、ChatGPTを含むLLMに、初期のトレーニングを超えた関連性のある最新の情報へのアクセスを提供することで、この課題に対する解決策を提供します。ベクトルデータベースを統合することで、これらのモデルは特定のドメインに焦点を当てたデータを取得し活用することができ、応答の正確性と文脈の理解が向上します。
この記事では、ベクトルデータベースの利用がChatGPTのパフォーマンスを向上させる方法について探求します。ベクトルデータベースの強力な検索機能がどのようにChatGPTを専門的なタスクや詳細な質問に効果的に対応させ、ユーザーにとってより信頼性の高い多目的なツールにするかを検討します。
# ベクトルデータベースの理解
統合について議論する前に、ベクトルデータベースとは何か、そしてAIを革新している方法について理解することが重要です。
# ベクトルデータベースとは
ベクトルデータベースは、ベクトル (opens new window)と呼ばれる複雑なデータポイントを処理するために設計された特殊なタイプのデータベースです。ベクトルは、データを比較し類似性を見つけることが容易な方法で表現する数値のリストのようなものです。ベクトルデータベースは、伝統的なデータベースのように情報を行と列で整理するのではなく、これらの数値のリストとしてデータを格納します。これにより、製品の推奨や類似した画像の識別など、パターンや類似性を見つけるタスクを非常に効率的に処理することができます。
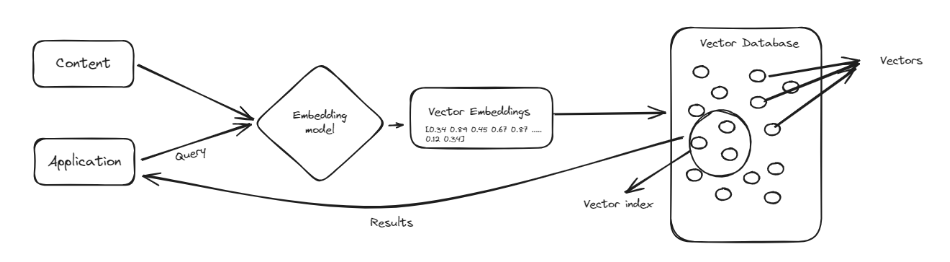
ベクトルデータベースの主な利点の1つは、大量のデータを迅速に検索して関連する情報を見つける能力です。これは、機械学習や人工知能などの分野で特に有用です。データポイント間の関係を理解することが重要な場合に、ベクトルデータベースを使用することで、ChatGPTなどのツールを強化し、情報の処理と取得をよりスマートかつ効率的に行うことができます。これにより、より良い応答とより正確な結果が得られます。
# ベクトルデータベースと従来のデータベースの比較
構造化されたレコードの管理と格納されたデータの整合性を確保する点では、従来の関係データベースには類似するものはありません。ただし、次の点でベクトルデータベースと比較すると:
- ベクトルデータベースは、多次元のデータポイントを扱うのに柔軟性があります。
- ベクトルデータベースは、大量の情報をより高速に処理します。
- 類似性に基づく検索方法は、AIアプリケーションに重要なパターン認識や類似性マッチングの操作を迅速に処理するため、ベクトルデータベース上でより効率的に機能します。
# ChatGPTにとってベクトルデータベースが重要な理由
ChatGPTなどのLLMは、自然言語処理と生成において驚異的な進歩を遂げています。しかし、これらのモデルはいくつかの制限に直面していますが、これらの制限はベクトルデータベースの統合によって解決することができます。
- 知識の幻覚:ベクトルデータベースは信頼性のある知識ベースとして機能し、誤った情報を削減します。
- 長期的なメモリストレージの能力がない:関連するデータを効率的に保存することにより、モデルの別のメモリとして考えることができます。
- 文脈の理解の問題:ベクトル表現により、文脈と概念間の微妙な理解が可能になります。
# MyScaleを使用したChatGPTとの統合:AI HRアシスタント
このチュートリアルでは、ChatGPTをMyScale (opens new window)という強力なベクトルデータベースと統合し、従業員の質問に答えるAI HRアシスタントを作成するプロセスを説明します。この実践的な例は、ベクトルデータベースがChatGPTを通じて最新のドメイン固有の情報を提供することで、ChatGPTを強化する方法を示します。
# ステップ1:環境のセットアップ
まず、必要なライブラリをインストールして環境をセットアップする必要があります。これらのライブラリには、言語モデルとテキスト処理を管理するための「langchain」、埋め込みを作成するための「sentence-transformers」、およびChatGPTモデルの「openai」が含まれます。
pip install langchain sentence-transformers openai
# ステップ2:環境変数の設定
MyScaleとOpenAI APIに接続するために環境変数を設定する必要があります。これらの変数には、MyScaleのホスト、ポート、ユーザー名、パスワード、およびOpenAIのAPIキーが含まれます。
import os
# ベクトルデータベースの接続の設定
os.environ["MYSCALE_HOST"] = "ここにホスト名を入力"
os.environ["MYSCALE_PORT"] = "ポート番号"
os.environ["MYSCALE_USERNAME"] = "ここにユーザー名を入力"
os.environ["MYSCALE_PASSWORD"] = "ここにパスワードを入力"
# OpenAIのAPIキーの設定
os.environ["OPENAI_API_KEY"] = "ここにAPIキーを入力"
注意: MyScaleDB (opens new window)のアカウントをお持ちでない場合は、MyScaleのウェブサイトにアクセスして無料アカウントを作成 (opens new window)し、クイックスタートガイド (opens new window)に従ってください。OpenAI APIを使用するには、OpenAIのウェブサイト (opens new window)でアカウントを作成し、APIキーを取得してください。
# ステップ3:データの読み込み
従業員ハンドブックのPDFを読み込み、処理のためにページに分割します。これにはドキュメントローダーを使用します。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
# 必要に応じて最初の数ページをスキップします
pages = pages[4:]
PyPDFLoaderクラスは、PDFドキュメントを効率的に読み込み、ドキュメントの読み込みプロセスをシームレスに処理します。load_and_split()メソッドはドキュメントを読み込み、個々のページに分割します。pages = pages[4:]を使用して最初の4ページを除外し、表紙や目次などの関係のない情報を除外します。
# ステップ4:データのクリーニング
次に、PDFから抽出したテキストを不要な文字、スペース、および書式設定を削除してクリーニングします。
import re
def clean_text(text):
# 改行をすべて削除し、複数の改行を単一のスペースに置き換える
text = re.sub(r'\s*\n\s*', ' ', text)
# 複数のスペースをすべて削除し、単一のスペースに置き換える
text = re.sub(r'\s+', ' ', text)
# 行の先頭の数字をすべて削除する(例:'1 '、'2 'など)
text = re.sub(r'^\d+\s*', '', text)
# 残っている不要なスペースや特殊文字を削除する
text = re.sub(r'[^A-Za-z0-9\s,.-]', '', text)
# 先頭と末尾のスペースを削除する
text = text.strip()
return text
text = "\n".join([doc.page_content for doc in pages])
cleaned_text = clean_text(text)
clean_text関数は、テキストを処理してクリーンで標準化されたテキストにします。改行、複数のスペース、行の先頭の数字、および残っている不要な文字を削除し、クリーンで標準化されたテキストを生成します。
# ステップ5:データの分割
次のステップは、AIアプリケーションの処理のためにテキストをより小さな管理可能なチャンクに分割することです。
from langchain.text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 各チャンクの最大サイズ
chunk_overlap=300, # チャンク間のオーバーラップ
length_function=len, # 長さを計算するための関数
is_separator_regex=False,
)
docs = text_splitter.create_documents([cleaned_text])
RecursiveCharacterTextSplitterクラスは、指定されたサイズのチャンクにテキストを分割し、連続性を確保するためのオーバーラップを持つテキストに分割します。これにより、文脈を失うことなくテキストを管理可能なピースに分割することができます。
# ステップ6:埋め込みモデルの定義
テキストチャンクをベクトル表現に変換するために、埋め込みモデルを定義します。
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
OpenAIEmbeddingsクラスは、事前学習済みのトランスフォーマーモデルを初期化し、テキストチャンクの埋め込み(ベクトル表現)を作成します。これにより、テキストの意味的な意味を捉えることができます。
# ステップ7:データをMyScaleベクトルストアに追加
ベクトル化されたテキストチャンクをMyScaleベクトルストア (opens new window)に追加し、効率的な検索を可能にします。
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
MyScale.from_documents(docs, embeddings)メソッドは、テキストチャンクのベクトル表現をMyScaleベクトルデータベースに格納し、効率的な類似性検索を可能にします。
# ステップ8:類似性検索の実行
格納されたベクトルに対して類似性検索を実行して、ベクトルストアの動作をテストしましょう。
output = docsearch.similarity_search("従業員がどれだけのガソリンを受け取るか?", 3)
similarity_searchメソッドは、クエリに類似したベクトルをベクトルデータベースから検索し、上位6つの一致を取得します。クエリを行った後、次のような結果が得られます。
[Document(page_content='従業員は追加の貢献を選択することができます。自主的な公的年金基金VPF 従業員の基本給の12 に対する雇用主の貢献 従業員の基本給の12 9.2退職金 退職金は、Adino Telecom Ltdのすべての対象従業員に対して、1972年の退職金支払い法に準拠して支払われます。雇用主は、完了した各年に対して15日の給与を支払います。給与のレートは、最後に引かれた給与のレートです。 9.3医療保険 すべての対象従業員は、Star Healthc laim Medicalポリシーの下で、自己、配偶者、および子供を最大1 lakhまでカバーされます。 9.4ESIC すべての対象従業員は、1948年のESI法に準拠してカバーされています。月給が10,000ルピー以下の従業員は、ESI制度の対象となります。従業員の貢献 給与の1.75の割合で 雇用主の貢献 給与の4.75の割合で。', metadata={'_dummy': 0}),
Document(page_content='月額割り当てin Rs M5 M4 1500 M3 M2 1250 M1 M0 800 O1 O2 420 A1, A2 A3 300 特別な承認は、国際電話を行う必要があるビジネスマネージャーにのみ与えられます。上記の値は変更される可能性があることに注意してください 437.3交通費の払い戻し DMレベルの最大額は、実際の請求額で月額1,875ルピーです。マネージャーレベルの最大額は、実際の請求額で月額2,200ルピーです。Sr.マネージャー DGMレベルの最大額は、実際の請求額で月額2,575ルピーです。車を持つGMの最大額は、月額6,000ルピーです。車のメンテナンスは、月額2,000ルピーと年間8,000ルピーです。交通費は、上記のレベルに保つ必要があり、上記の金額を超える請求は許可されません。有給調査の場合、交通費は月額5,000ルピーです。上記の値は変更される可能性があることに注意してください 447.4インターネット料金 グレードM5には月額300ルピーのインターネット料金が適用されます。 7.5トレーニングポリシー', metadata={'_dummy': 0}),
Document(page_content='Diwaliの各年の完了時に支払われます。 4.パフォーマンスインセンティブ 従業員は、年間を通じてのパフォーマンスに基づいてパフォーマンスインセンティブを受け取る権利があります。インセンティブは年に1回支払われます。 5.医療 対象従業員は、Star Health Insurance Policy Schemeの下でカバーされています。 6.所得税のあるすべての従業員は、毎年9月までに投資計画を提出する必要があります。 7.すべての投資計画の証明書は、1月末までに提出する必要があります。 499.福利厚生 509.1退職金 すべての従業員は、1952年の退職金法に準拠してカバーされています。従業員の貢献 基本給の12。従業員は追加の貢献を選択することができます。自主的な公的年金基金VPF 従業員の基本給の12 9.2退職金 退職金は、Adino Telecom', metadata={'_dummy': 0})]
# ステップ9:リトリーバの設定
ベクトルストアをドキュメント検索エンジンからリトリーバに変換し、LLMチェーンが関連情報を取得するために使用するようにします。
retriever = docsearch.as_retriever()
as_retrieverメソッドは、ベクトルストアをリトリーバオブジェクトに変換し、クエリに基づいて関連するドキュメントを取得するオブジェクトにします。
# ステップ10:LLMとチェーンの定義
最後のステップは、LLM(ChatGPT)を定義し、リトリーバベースのQAチェーンを設定することです。
from langchain_openai import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=False,
)
OpenAIクラスはChatGPTモデルを初期化し、RetrievalQA.from_chain_typeはリトリーバを使用して関連ドキュメントを取得し、言語モデルを使用して回答を生成するQAチェーンを設定します。
# ステップ11:チェーンへのクエリ
QAチェーンにクエリを送信してAI HRアシスタントから回答を取得します。
# チェーンにクエリを送信
response1 = qa.run("交通手当はいくらですか?")
print(response1)
qa.run(query)メソッドは、QAチェーンにクエリを送信し、関連ドキュメントを取得し、ChatGPTを使用して回答を生成します。クエリに対する応答は、次のように表示されます。
クエリを行った後、次のような結果が得られます。
"交通手当は、従業員のグレードとレベルによって異なります。DMレベルの従業員の場合、月額1,875ルピーからGMレベルの従業員の場合、最大月額6,000ルピーの車を持つ従業員までの範囲です。金額は変更される可能性があります。"
別のクエリを行ってみましょう。
response2 = qa.run("オフィスの勤務時間は何時から何時までですか?")
print(response2)
このクエリに対しては、次のような結果が返されます。
'オフィスの勤務時間は、午前9時から午後5時45分または午前9時30分から午後6時15分までです。一部の従業員には異なるスケジュールやシフトがある場合があります。'
これが、ChatGPTのパフォーマンスをベクトルデータベースと統合することでどのように向上させることができるかの例です。これにより、モデルが最新のドメイン固有の情報にアクセスできることが保証され、より正確で関連性の高い応答が得られます。

# ベクトルデータベースとしてMyScaleを選ぶ理由
MyScaleは、SQLとの完全な互換性 (opens new window)を備えており、複雑なデータ操作や意味検索を簡素化します。開発者は、ベクトルを扱うために新しいツールを学ぶ必要がなく、既知のSQLクエリを使用することができます。MyScaleの高度なベクトルインデックスアルゴリズムとOLAPアーキテクチャにより、高いパフォーマンスとスケーラビリティが実現され、大規模なAIアプリケーションのデータ管理に適しています。
セキュリティと統合の容易さも、MyScaleの追加の強みです。MyScaleは、安全なAWSインフラストラクチャ上で実行され、データを保護するための暗号化やアクセス制御などの機能を提供します。MyScaleはまた、LLMアプリケーションのパフォーマンスとセキュリティのリアルタイムの洞察を提供する包括的なモニタリングツール (opens new window)をサポートしています。オープンソースプラットフォームとして、MyScaleはイノベーションとカスタマイズを促進し、さまざまなAIプロジェクトに適した柔軟な選択肢となっています。
# 結論
ChatGPTなどのLLMをベクトルデータベースと組み合わせることで、新しいデータに対してモデルを再トレーニングすることなく、強力なアプリケーションを構築することができます。このセットアップにより、ChatGPTはリアルタイムで特定の情報にアクセスできるようになり、応答がより正確で関連性の高いものになります。
ベクトルデータベースは、LLMの応答品質とパフォーマンスの向上に重要な役割を果たします。これにより、モデルが最新かつ関連性の高いデータにアクセスできることが保証されます。MyScaleは、効率とパフォーマンスの面で専門のベクトルデータベースを凌駕 (opens new window)しています。さらに、新規ユーザーは開発ポッドで500万の無料ベクトルストレージにアクセスできるため、MyScaleの機能をテストし、利点を直接体験することができます。
もしもっと詳しく話し合いたい場合は、MyScaleのDiscord (opens new window)に参加して、ご意見やフィードバックを共有してください。



