
ChatGPT (opens new window) and other large language models (LLMs) (opens new window) have made big strides in understanding and generating human-like text. However, they often struggle with staying accurate and relevant, especially in fast-changing or specialized fields. This is because they rely on large but fixed datasets that can quickly become outdated. This is where vector databases (opens new window) can help, providing a way to keep these models updated and contextually aware.
Vector databases offer a solution to this challenge by providing LLMs, including ChatGPT, with access to relevant and up-to-date information that extends beyond their initial training. By integrating vector databases, these models can retrieve and leverage specific, domain-focused data, leading to improved response accuracy and contextual awareness.
This article explores how the utilization of vector databases can enhance the performance of ChatGPT. We will examine how the powerful retrieval capabilities of vector databases can enable ChatGPT to handle specialized tasks and detailed questions more effectively, making it a more reliable and versatile tool for users.
# Understanding Vector Databases
Before discussing their integration, it’s vital to understand what vector databases are and how they are revolutionizing AI.
# What is a Vector Database
A vector database is a special type of database designed to handle complex data points known as vectors (opens new window). Vectors are like lists of numbers that represent data in a way that makes it easy to compare and find similarities. Instead of organizing information in rows and columns like traditional databases, vector databases store data as these numerical lists. This makes them very good at handling tasks that involve finding patterns and similarities, such as recommending products or identifying similar images.
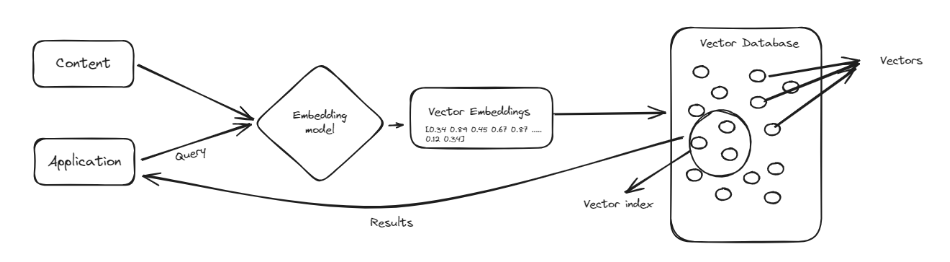
One of the main advantages of vector databases is their ability to quickly search through large amounts of data to find relevant information. They are particularly useful in fields like machine learning and artificial intelligence, where understanding relationships between data points is crucial. By using vector databases, we can enhance tools like ChatGPT, making them smarter and more efficient in processing and retrieving information, leading to better and more accurate responses.
# Vector Databases vs. Traditional Databases
When it comes to managing structured records and ensuring the integrity of stored data, traditional relational databases have no peer; however, compared to them:
- Vector databases are more flexible in dealing with multi-dimensional data points.
- Vector databases process huge amounts of information faster.
- Similarity-based retrieval methods work better on vector databases due to their efficiency in handling operations quickly during pattern recognition or similarity matching, which are important for AI applications.
# Why Vector Databases are Key for ChatGPT
LLMs like ChatGPT have demonstrated remarkable progress in natural language processing and generation. However, these models also face several limitations that can be addressed through the integration of vector databases.
- Knowledge hallucinations: A vector database would act as a reliable knowledge base and cut down on false information.
- No long-term memory storage capability: By storing relevant data efficiently, one can think of it as another memory for the respective model.
- Contextual understanding problem: Vector representations allow a nuanced understanding of context and relationships between concepts.
# Integrate ChatGPT with MyScale for an AI HR Assistant
In this tutorial, we will walk through the process of integrating ChatGPT with MyScale (opens new window), a powerful vector database, to create an AI HR assistant capable of answering employee queries around the clock. This practical example will demonstrate how vector databases can enhance ChatGPT by providing up-to-date, domain-specific information.
# Step 1: Set Up the Environment
First, we need to set up our environment by installing the necessary libraries. These libraries include langchain for managing language models and text processing, sentence-transformers for creating embeddings, and openai for the chatGPT model.
pip install langchain sentence-transformers openai
# Step 2: Configure Environment Variables
We need to configure the environment variables to connect to MyScale and OpenAI API. These variables include the host, port, username, and password for MyScale, and the API key for OpenAI.
import os
# Setting up the vector database connections
os.environ["MYSCALE_HOST"] = "your_host_name_here"
os.environ["MYSCALE_PORT"] = "port_number"
os.environ["MYSCALE_USERNAME"] = "your_user_name_here"
os.environ["MYSCALE_PASSWORD"] = "your_password_here"
# Setting up the API key for OpenAI
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
Note: If you don't have a MyScaleDB (opens new window) account, visit the MyScale website to sign up (opens new window) for a free account and follow the QuickStart guide (opens new window). To use the OpenAI API, create an account on the OpenAI website (opens new window) and obtain the API key.
# Step 3: Load Data
We load the employee handbook PDF and split it into pages for processing. This involves using a document loader.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
# Skipping the first few pages if necessary
pages = pages[4:]
The PyPDFLoader class is utilized to load PDF documents efficiently, handling the document loading process seamlessly. The load_and_split() method reads the document and splits it into individual pages, making the text more manageable for further processing. We remove the first four pages using pages = pages[4:] to exclude irrelevant information like the cover or table of contents.
# Step 4: Clean Data
Now, let’s clean the text extracted from the PDF to remove unwanted characters, spaces, and formatting.
import re
def clean_text(text):
# Remove all the newlines and replace multiple newlines with a single space
text = re.sub(r'\\s*\\n\\s*', ' ', text)
# Remove all the multiple spaces and replace them with a single space
text = re.sub(r'\\s+', ' ', text)
# Remove all the numbers at the beginning of lines (like '1 ', '2 ', etc.)
text = re.sub(r'^\\d+\\s*', '', text)
# Remove any remaining unwanted spaces or special characters
text = re.sub(r'[^A-Za-z0-9\\s,.-]', '', text)
# Strip leading and trailing spaces
text = text.strip()
return text
text = "\\n".join([doc.page_content for doc in pages])
cleaned_text = clean_text(text)
The clean_text function processes and sanitizes the text. It removes newlines, multiple spaces, numbers at the beginning of lines, and any remaining unwanted characters, resulting in clean and standardized text.
# Step 5: Split Data
The next step is to split text into smaller, manageable chunks for processing for our AI application.
from langchain.text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Maximum size of each chunk
chunk_overlap=300, # Overlap between chunks
length_function=len, # Function to calculate length
is_separator_regex=False,
)
docs = text_splitter.create_documents([cleaned_text])
The RecursiveCharacterTextSplitter class splits the text into chunks of a specified size with overlap to ensure continuity. This ensures that the text is broken down into manageable pieces without losing context.
# Step 6: Define the Embedding Model
We define the embedding model using OpenAIEmbeddings embeddings to convert text chunks into vector representations.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
The OpenAIEmbeddings class initializes a pre-trained transformer model to create embeddings (vector representations) for the text chunks, capturing the semantic meaning of the text.
# Step 7: Add Data to the MyScale Vector Store
Now, let’s add the vectorized text chunks to the MyScale vector store (opens new window) for efficient retrieval.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
The MyScale.from_documents(docs, embeddings) method stores the vector representations of the text chunks in the MyScale vector database, enabling efficient similarity searches.
# Step 8: Perform a Similarity Search
Let’s perform a similarity search on the stored vectors to test the working of our vector store.
output = docsearch.similarity_search("How much petrol employees get?", 3)
The similarity_search method searches the vector database for vectors similar to the query, retrieving the top six matches. After making the query, you’ll get results like this:
[Document(page_content='The employee can opt for additional contribution towards Provident Fund via Voluntary Provident Fund VPF Employers Contribution 12 of the Basic Salary of the Employee 9.2Gratuity Gratuity will be paid in compliance with the Payment of Gratuity Act of 1972 to all eligible employees of Adino Telecom Ltd. The employer shall pay gratuity to the eligible employee for every completed year of continuous service more than 5 years at the rate of 15 days salary per completed year of service. The rate of salary shall be the rate of last drawn salary. 9.3Mediclaim Medical Insurance Alleligibleemployees will be covered under the Star Healthc laim Medical policy for Self, Spouse and child up to Rs.1 lakh . 9.4ESIC All eligible employees are covered in compliance with the ESI Act of 1948. All employees drawing a monthly salary upto Rs. 10,000 per month are coverable under the ESI scheme. Employees contribution At the rate of 1.75 of Salary Employers Contribution At the rate of 4.75 of Salary.', metadata={'_dummy': 0}),
Document(page_content='ALLOTTED PER MONTHin Rs M5 M4 1500 M3 M2 1250 M1 M0 800 O1 O2 420 A1, A2 A3 300 Please note that no special approval will be given except to Business Managers who are required to make international calls. Please note that the above values are subject to change 437.3Conveyance Reimbursement Up to DM level Maximum of Rs. 1875 pm to be claimed at actuals Manager Level Maximum of Rs. 2,200 pm to be claimed at actuals Sr. Manager DGM level Maximum of Rs. 2,575 pm to be claimed at actual GM having car maximum Rs. 6 000 per month to be claimed at actua l. Car maintenance maximum Rs. 2,000 per month and Rs. 8000 per annum. The conveyance expenses will have to be kept at the above levels and no reimbursement will be allowed beyond the amount mentioned. In case of paid survey the conveyance will be at Rs. 5 ,000 pm. Please note that the above values are subject to change 447.4Internet Charges Rs. 300 pm for internet charges will be applicable only for Grade M5. 7.5Training policy', metadata={'_dummy': 0}),
Document(page_content='will be disbursed onthe completion of each year during Diwali. 4.Performance Incentive Employees are entitled to receiv e Performance Incentives based on their performance throughout the year. The incentive is disbursed once in a year. 5.Medical Eligible employees are covered under the Star Health Insurance Policy Scheme. 6.All employees who fall under the Income Tax should su bmit their Investment Plans by September of every financial year. 7.All the Investment Plan pro ofs need to be submitted by the end of January. 499.Benefits 509.1Provident Fund All employees are covered in compliance with the Provident Fund Act of 1952 according to which Employees Contribution 12 of the Basic Salary. The employee can opt for additional contribution towards Provident Fund via Voluntary Provident Fund VPF Employers Contribution 12 of the Basic Salary of the Employee 9.2Gratuity Gratuity will be paid in compliance with the Payment of Gratuity Act of 1972 to all eligible employees of Adino Telecom', metadata={'_dummy': 0})]
# Step 9: Set the Retriever
Now, let’s turn this vector store from a document search engine to a retriever. It will be used by the LLM chain to fetch relevant information.
retriever = docsearch.as_retriever()
The as_retriever method converts the vector store into a retriever object that fetches relevant documents based on their similarity to the query.
# Step 10: Define the LLM and the Chain
The final step is to define LLM (ChatGPT) and set up a retrieval-based QA chain.
from langchain_openai import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=False,
)
The OpenAI class initializes the ChatGPT model, while RetrievalQA.from_chain_type sets up a QA chain that uses the retriever to fetch relevant documents and the language model to generate answers.
# Step 11: Query the Chain
We query the QA chain to get answers from the AI HR assistant.
# Query the chain
response1 = qa.run("How much is the conveyance allowance?")
print(response1)
The qa.run(query) method sends a query to the QA chain, which retrieves relevant documents and generates an answer using ChatGPT. The responses to the queries are then printed.
Upon making the query, you’ll get a response like this:
" The conveyance allowance varies depending on the employee's grade and level, ranging from Rs. 1,875 per month for DM level employees to a maximum of Rs. 6,000 per month for GM level employees with a car. The amounts are subject to change."
Let’s make another query:
response2 = qa.run("What are the office working hours?")
print(response2)
This query will return results similar to this:
' The office working hours are from 9:00 am to 5:45 pm or from 9:30 am to 6:15 pm, with certain employees possibly having different schedules or shifts.'
This is how we can enhance the performance of ChatGPT by integrating it with vector databases. By doing so, we ensure that the model can access up-to-date, domain-specific information, leading to more accurate and relevant responses.

# Why Choose MyScale as a Vector Database
MyScale stands out as a vector database due to its full compatibility with SQL (opens new window), which simplifies complex data operations and semantic searches. Developers can use familiar SQL queries for handling vectors, avoiding the need to learn new tools. MyScale’s advanced vector indexing algorithms and OLAP architecture ensure high performance and scalability, making it suitable for managing data of large-scale AI applications efficiently.
Security and ease of integration are additional strengths of MyScale. It runs on a secure AWS infrastructure, offering features like encryption and access controls to protect data. MyScale also supports extensive monitoring tools (opens new window), providing real-time insights into the performance and security of LLM applications. As an open-source platform, MyScale encourages innovation and customization, making it a versatile choice for various AI projects.
# Conclusion
Combining LLMs like ChatGPT with vector databases enables developers to build powerful applications without retraining models on new data. This setup lets ChatGPT access real-time, specific information, making its responses more accurate and relevant.
Vector databases play a key role in improving the response quality and performance of LLMs. They ensure that models have access to the latest and most relevant data. MyScale excels in this area, providing efficient and scalable solutions that make integration easy and effective. MyScale has also outperformed specialized vector databases (opens new window) in terms of speed and performance. Moreover, new users can access 5 million free vector storage in its development pod, enabling them to test MyScale’s features and experience the benefits firsthand.
If you want to discuss more with us, you are welcome to join MyScale Discord (opens new window) to share your thoughts and feedback.



