
Large language models (LLMs) (opens new window) have revolutionized AI with their ability to generate human-like text, excelling in tasks like content creation and intelligent responses. However, they are limited by the data they were trained on, which can lead to outdated or inaccurate information, known as "information hallucinations." To address this issue, Retrieval-Augmented Generation (RAG) (opens new window) has emerged, combining LLMs with external retrieval systems to pull in up-to-date and relevant information, resulting in more accurate and dynamic responses.
This blog series will explore the evolution of RAG, focusing on the shift from traditional "naive" RAG to more sophisticated "advanced" RAG techniques. We’ll dive into key components of advanced RAG, including:
Topics:
Naive RAG vs. Advanced RAG
By the end of this series, you’ll gain a comprehensive understanding of how these components work together to elevate the performance of advanced RAG systems.
# What is RAG
RAG is a strategic enhancement designed to elevate the performance of LLMs. By incorporating a step that retrieves information during text generation, RAG ensures that the model's responses are accurate and up-to-date. RAG has evolved significantly, leading to the development of two main modes:
- Naive RAG: This is the most basic version, where the system simply retrieves the relevant information from a knowledge base and directly gives it to the LLM to generate the response.
- Advanced RAG: This version goes a step further. It adds additional processing steps before and after retrieval to refine the retrieved information. These steps enhance the quality and accuracy of the generated response, ensuring it integrates seamlessly with the model's output.
# Naive RAG
The Naive RAG is the simplest version of the RAG ecosystem, offering a straightforward method for combining retrieval data with LLM models to efficiently respond to users.
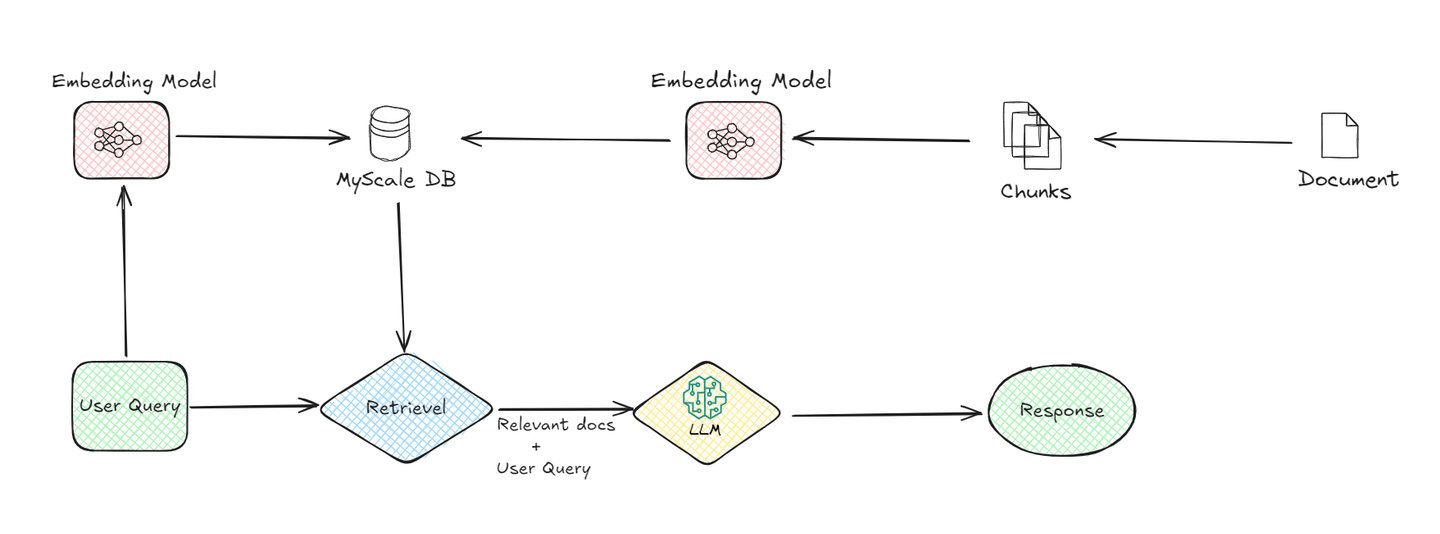
A basic system has the following components:
1. Document Chunking:
The process begins with documents being split into smaller chunks. This is essential because smaller chunks are easier to manage and process. For instance, when you have a long document, it’s broken down into segments, making it easier for the system to retrieve relevant information later.
2. Embedding Model:
The embedding model is a critical part of the RAG system. It converts both the document chunks and the user query into numerical form, often called embeddings (opens new window). This conversion is necessary because computers understand numerical data better. The embedding model uses advanced machine learning techniques to represent the meaning of text in a mathematical way. For example, when a user asks a question, the model transforms this question into a set of numbers that capture the semantics of the query.
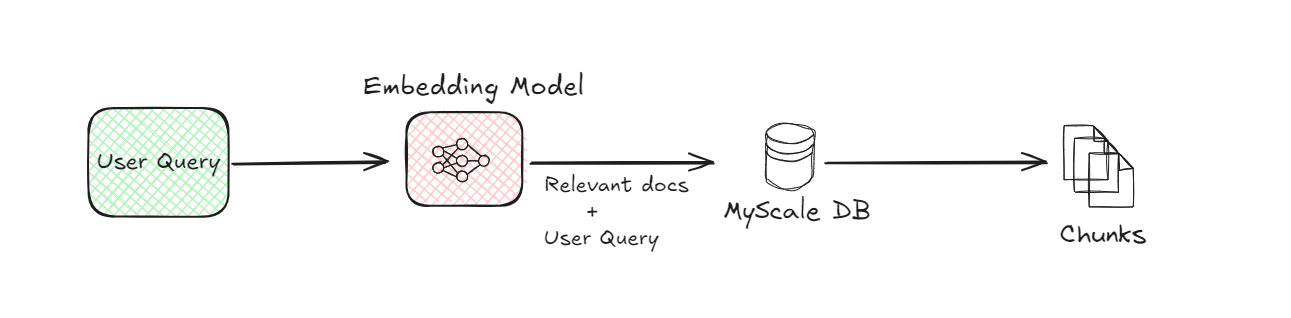
3. Vector Database (MyScaleDB):
Once the document chunks are converted into embeddings, they are stored in a vector database (opens new window) like MyScaleDB (opens new window). The vector databases are designed to efficiently store and retrieve these embeddings. When a user submits a query, the system uses the vector database to find the most relevant document chunks by comparing the embeddings of the query with those stored in the database. This comparison helps in identifying the chunks that are most similar to what the user is asking.
4. Retrieval:
After the vector database identifies the relevant document chunks, they are retrieved. This retrieval process is crucial because it narrows down the information that will be used to generate the final response. Essentially, it acts as a filter, ensuring that only the most relevant data is passed on to the next stage.
5. LLM (Large Language Model):
The LLM takes over once the relevant chunks are retrieved. Its job is to understand the retrieved information and generate a coherent response to the user’s query. The LLM uses the user query and the retrieved chunks to provide a response that is not only relevant but also contextually appropriate. This model is responsible for interpreting the data and formulating a response in natural language that the user can easily understand.
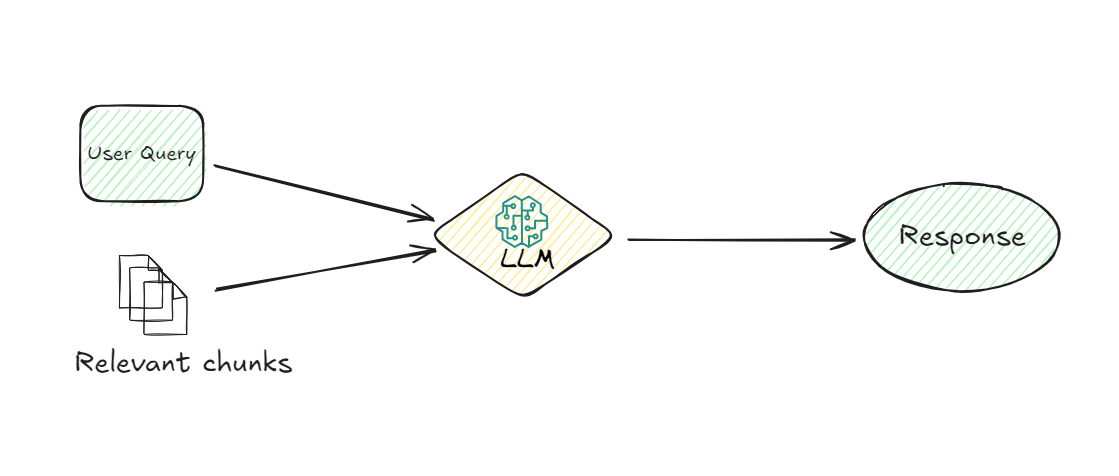
6. Response Generation:
Finally, the system generates a response based on the information processed by the LLM. This response is then delivered back to the user, providing them with the information they were seeking in a clear and concise manner.
By understanding the flow of data from the user's query to the final response, we can appreciate how each component of the Naive RAG system plays a pivotal role in ensuring that the user receives accurate and relevant information.
# Advantages
- Simplicity of Implementation: RAG is straightforward to set up as it directly integrates retrieval with generation, reducing the complexity involved in enhancing language models without needing intricate modifications or additional components.
- No Need for Fine-Tuning: One of the significant advantages of RAG is that it doesn't require fine-tuning (opens new window) of the LLM. This not only saves time and reduces operational costs but also allows for faster deployment of RAG systems.
- Enhanced Accuracy: By leveraging external, up-to-date information, Naive RAG significantly improves the accuracy of generated responses. This ensures that the outputs are not only relevant but also reflect the latest data available.
- Reduced Hallucinations: RAG mitigates the common issue of LLMs generating incorrect or fabricated information by grounding responses in real, factual data retrieved during the process.
- Scalability and Flexibility: The simplicity of Naive RAG makes it easier to scale across different applications, as it can be adapted without significant changes to existing retrieval or generative components. This flexibility allows it to be deployed across various domains with minimal customization.
# Drawbacks
- Limited Processing: The retrieved information is used directly, without further processing or refinement, which might lead to coherence issues in the generated responses.
- Dependency on Retrieval Quality: The quality of the final output heavily depends on the retrieval module's ability to find the most relevant information. Poor retrieval can lead to less accurate or relevant responses.
- Scalability Issues: As the dataset grows, the retrieval process may become slower, affecting the overall performance and response time.
- Context Limitations: Naive RAG may struggle to understand the broader context of a query, leading to responses that, while accurate, might not fully align with the user's intent.
By examining these advantages and drawbacks, we can comprehensively understand where Naive RAG excels and where it might face challenges. This will pave the way for improvements and create the opportunity to develop advanced RAG.
# Advanced RAG
Building upon the foundation of Naive RAG, Advanced RAG (opens new window) introduces a layer of sophistication to the process. Unlike Naive RAG, which directly incorporates retrieved information, Advanced RAG involves additional processing steps that optimize the relevance, and overall quality of the response.
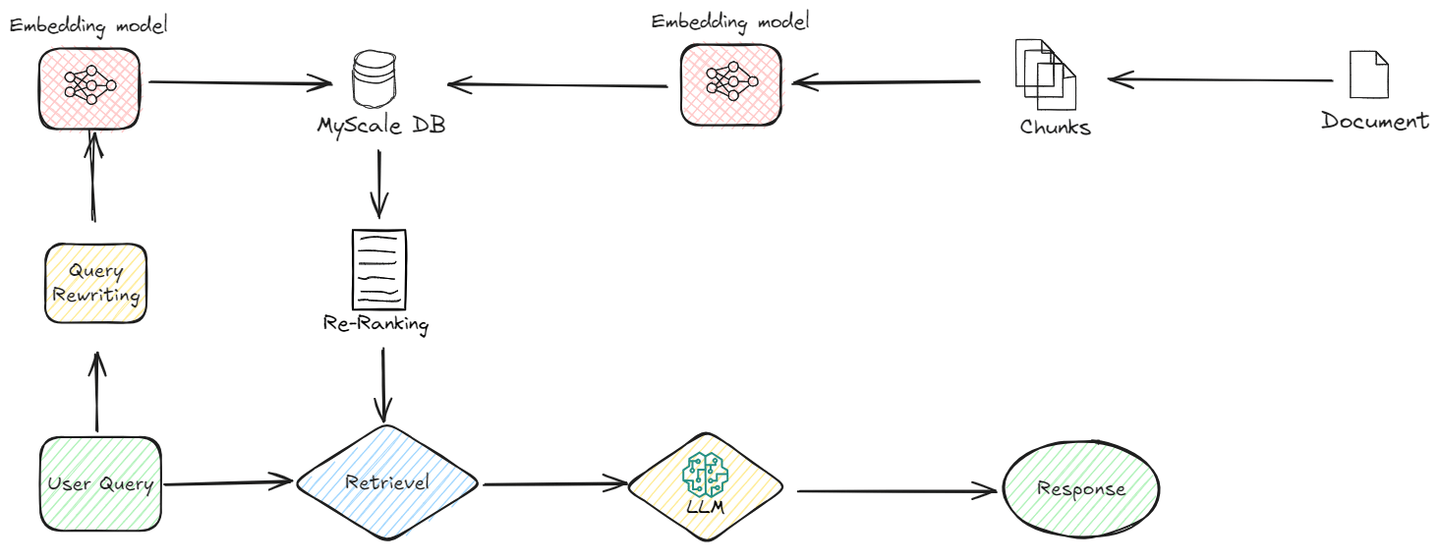
Let’s understand how it works:
# Pre-Retrieval Optimizations
In Advanced RAG, the retrieval process is refined even before the actual retrieval takes place. Here's what happens in this phase:
# Indexing Improvements
Indexing methods (opens new window) play a vital role in efficiently organizing and retrieving data in databases. Traditional indexing methods, such as B-Trees (opens new window) and Hash indexing (opens new window), have been widely used for this purpose. However, the search speed of these algorithms decreases as the data size increases. Therefore, we need more efficient indexing methods for larger datasets. MyScale's MSTG (Multi-Strategy Tree-Graph) (opens new window) indexing algorithm is a prime example of such an advancement. This algorithm outperforms other indexing methods in terms of speed and performance.
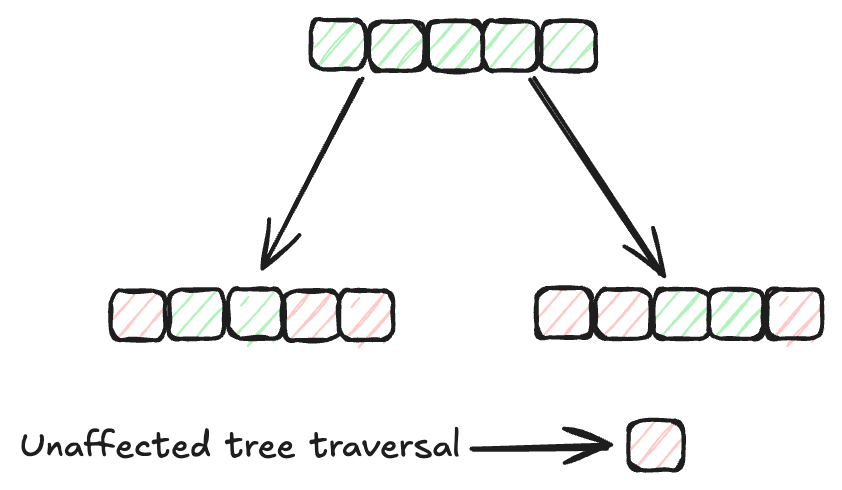
MSTG merges the strengths of both hierarchical graph (opens new window) and tree structures (opens new window). Typically, graph algorithms are faster for unfiltered searches but may not be efficient for filtered searches. On the other hand, tree algorithms excel in filtered searches but are slower for unfiltered ones. By combining these two approaches, MSTG ensures high performance and accuracy for both unfiltered and filtered searches, making it a robust choice for a variety of search scenarios.
# Query Re-writing
Before the retrieval process begins, the original user query undergoes several enhancements to improve its accuracy and relevance. This step ensures that the retrieval system fetches the most pertinent information. Techniques such as query rewriting (opens new window), expansion, and transformation are employed here. For instance, if a user's query is too broad, query rewriting can refine it by adding more context or specific terms, while query expansion might add synonyms or related terms to capture a wider range of relevant documents.
# Dynamic Embeddings
In Naive RAG, a single embedding model might be used for all types of data, which can lead to inefficiencies. Advanced RAG, however, fine-tunes and adjusts embeddings based on the specific task or domain. This means that the embedding model is trained or adapted to better capture the contextual understanding required for a particular type of query or dataset.
By using dynamic embeddings, the system becomes more efficient and accurate, as the embeddings are more closely aligned with the nuances of the specific task at hand.
# Hybrid Search
Advanced RAG also leverages a hybrid search (opens new window) approach, which combines different search strategies to enhance retrieval performance. This might include keyword-based searches, semantic searches, and neural searches. For instance, MyScaleDB supports filtered vector search (opens new window) and full-text search (opens new window), allowing the use of complex SQL queries due to its SQL-friendly syntax. This hybrid approach ensures that the system can retrieve information with a high degree of relevance, regardless of the nature of the query.
# Post-Retrieval Processing
After the retrieval process, Advanced RAG doesn't stop there. It further processes the retrieved data to ensure the highest quality and relevance in the final output.
# Re-ranking
After the retrieval process, Advanced RAG takes an extra step to refine the information. This step, known as re-ranking, ensures that the most relevant and useful data is prioritized. Initially, the system retrieves several pieces of information that might be related to the user’s query. However, not all of this information is equally valuable. Re-ranking helps in sorting this data based on additional factors like how closely it matches the query and how well it fits the context.
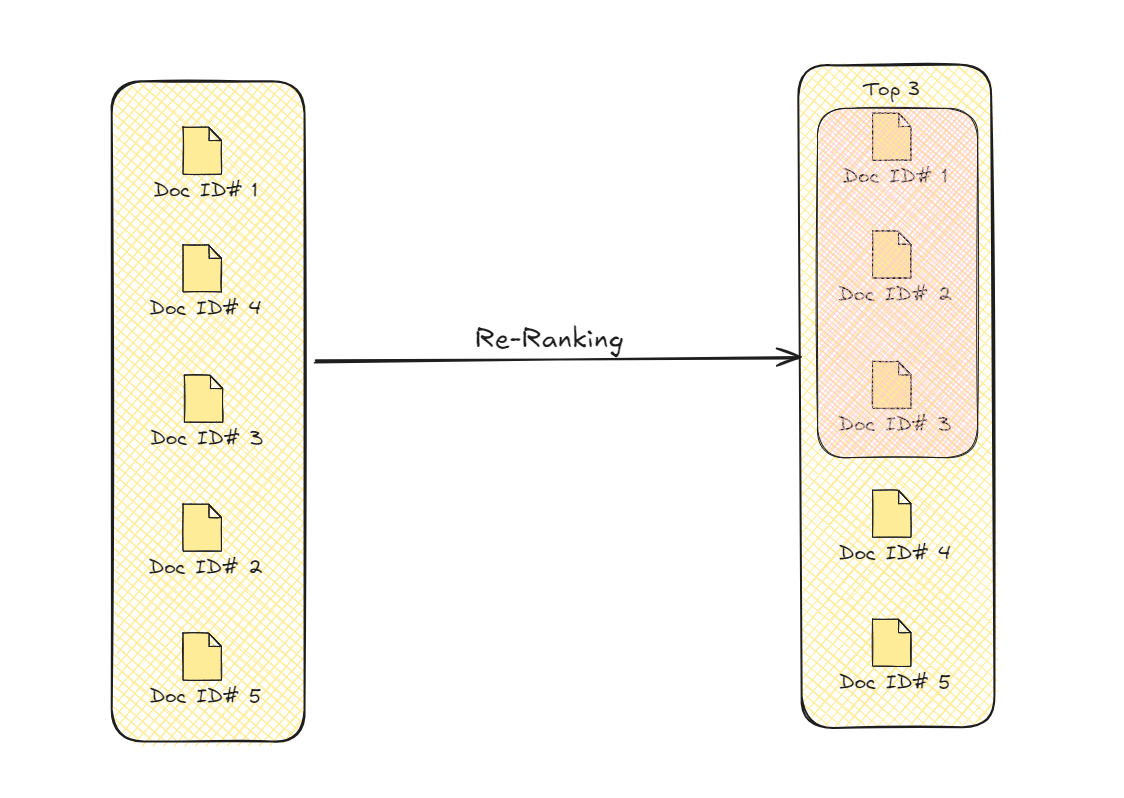
By reassessing the retrieved content, re-ranking places the most relevant pieces at the top. This ensures that the generated response is not only accurate but also coherent and directly addresses the user's needs. The process uses various criteria, such as semantic relevance and contextual appropriateness, to reorder the information. This refinement leads to a final response that is more focused and precise, enhancing the overall quality of the output.
# Context Compression
After filtering the relevant documents, even with the use of a re-ranking algorithm, there may still be irrelevant data within those filtered documents for answering the user's query. The process of eliminating or removing this extraneous data is what we refer to as contextual compression. This step is applied right before passing the relevant documents to the LLM, ensuring that the LLM only receives the most relevant information, enabling it to deliver the best possible results.
# Advantages
To better understand the differences between these two approaches, let's explore the specific advantages that advanced RAG offers over naive RAG.
- Better Relevance with Re-ranking: Re-ranking makes sure the most relevant information comes first, improving both the accuracy and flow of the final response.
- Dynamic Embeddings for Better Context: Dynamic embeddings are customized for specific tasks, helping the system understand and respond more accurately to different queries.
- More Accurate Retrieval with Hybrid Search: Hybrid search uses multiple strategies to find data more effectively, ensuring higher relevance and precision in the results.
- Efficient Responses with Context Compression: Context compression removes unnecessary details, making the process faster and leading to more focused, high-quality answers.
- Enhanced User Query Understanding: By rewriting and expanding queries before retrieval, advanced RAG ensures that user queries are fully understood, leading to more accurate and relevant results.
Advanced RAG marks a major improvement in the quality of responses generated by language models. By adding a refinement stage, it effectively tackles key issues found in Naive RAG, such as coherence and relevance.
# Comparative Analysis: Advanced RAG Unveiled - I: Naive RAG Vs. Advanced RAG
By comparing naive RAG and advanced RAG, we can observe how advanced RAG expands on the basic framework of naive RAG. It introduces key improvements that enhance accuracy, efficiency, and the overall quality of retrieval.
| Criteria | Naive RAG | Advanced RAG |
|---|---|---|
| Accuracy and Relevance | Provides basic accuracy by using the retrieved information. | Improves accuracy and relevance with advanced filtering, re-ranking, and better context use. |
| Data Retrieval | Uses basic similarity checks, which might miss some relevant data. | Optimizes retrieval with techniques like hybrid search and dynamic embeddings, ensuring highly relevant and accurate data. |
| Query Optimization | Handles queries in a straightforward way without much enhancement. | Improves query handling with methods like query rewriting and adding metadata, making retrieval more precise. |
| Scalability | May become less efficient as data size grows, affecting retrieval. | Designed to handle large datasets efficiently, using better indexing and retrieval methods to keep performance high. |
| Multi-Stage Retrieval | Does a single pass of retrieval, which might miss important data. | Uses a multi-stage process, refining initial results with steps like reranking and context compression to ensure final outputs are accurate and relevant. |

# Conclusion
When choosing between naive RAG and advanced RAG, consider the specific needs of your application. Naive RAG is ideal for simpler use cases where speed and straightforward implementation are priorities. It enhances LLM performance in scenarios where deep contextual understanding isn't critical. On the other hand, Advanced RAG is better suited for more complex applications, offering improved accuracy and coherence through additional processing steps like refined filtering and re-ranking, making it the preferred choice for handling larger datasets and complex queries.
Pioneering the future of data-driven intelligence, MyScale offers an advanced RAG solution to elevate your GenAI initiatives. From blazing-fast vector search to intelligent reranking, MyScale's platform is engineered to deliver unparalleled performance and flexibility. Discover how MyScale RAG solution can empower your organization to extract maximum value from your knowledge bases.
Next, we'll delve into Query Rewriting—a critical component of Advanced RAG. This technique enhances the accuracy and relevance of retrieved information by refining the way queries are structured before they are sent to the retrieval system. We'll explore the strategies behind effective query rewriting and discuss how it plays a vital role in improving the overall performance of RAG systems. Stay tuned for a deeper look into how this process can transform the way AI models interact with external data!




