
MyScale 是一款高性能的、支持 SQL 的向量数据库,完全托管在 AWS 上。MyScale 的优势在于它对标准 SQL 语法的全面支持和 与专业向量数据库相匹配甚至超越的性能水平。
本文的目的是探讨 MyScale 如何利用 AWS 的基础设施堆栈来构建一个健壮、稳定且高效的云数据库。
# 向量数据库和嵌入
但首先,让我们先描述一下向量数据库、向量嵌入,以及专业向量数据库是如何存储向量嵌入或对象的数学表示(如文档),捕获它们的语义关系和上下文信息的。
# 向量数据库
向量数据库可以大致分为两类:
- 专门设计用于存储向量的专业向量数据库,如 Pinecone、Weaviate 和 Qdrant
- 通用的 SQL 或 NoSQL 数据库产品,流行的 SQL 数据库如 PostgreSQL 通过像
pgvector这样的插件支持向量索引和搜索
注意:
近期,多个开源数据库,如 ClickHouse、Redis、Elasticsearch 和 Cassandra,已经新增了对向量索引的原生支持。
尽管专业向量数据库通常被认为提供更好的搜索性能,但支持向量搜索的通用数据库则提供更全面的数据管理和结构化数据查询能力。MyScale 基于开源 OLAP 数据库 ClickHouse,然而,它将向量搜索和结构化数据查询能力融为一体。
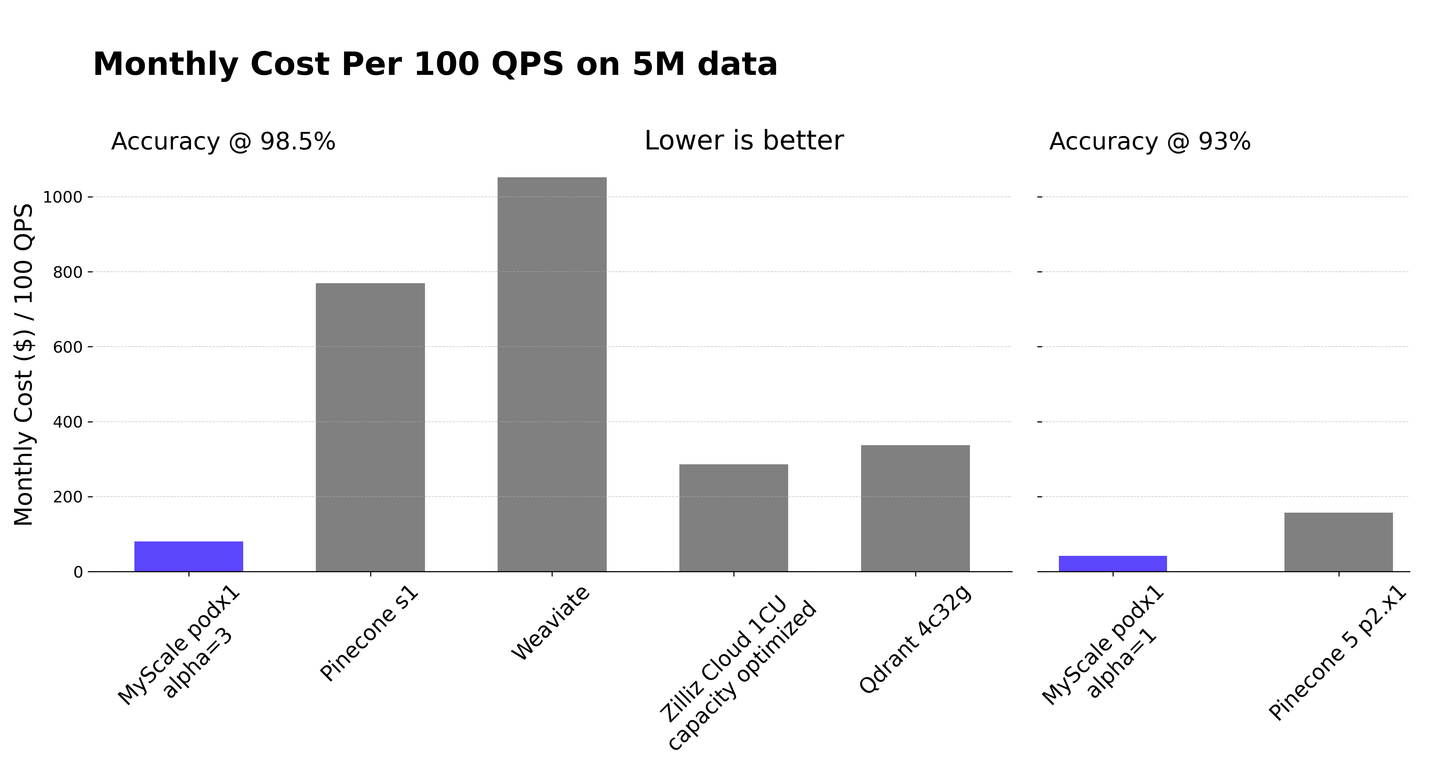
MyScale 团队开发了一种先进的向量索引算法,称为多尺度树图 (MSTG)。这种算法允许快速的搜索性能、高数据密度以及快速的插入速度。结合 ClickHouse 提供的列式存储和快速的结构化数据分析,MyScale 与专业向量数据库相比提供了显著更高的性价比。这些优势在下图中有明显的展示。
# 向量嵌入
向量嵌入无处不在,是许多机器学习和深度学习算法的支柱,在从搜索引擎到智能助手的众多领域都有应用。机器学习和深度学习技术通常将文本、图像、音频和视频等非结构化数据转换为向量嵌入。然后可以通过向量相似性搜索技术来搜索这些嵌入的语义相关性。
# MyScale 的架构概览
MyScale 是一个充分利用 AWS 云平台的数据库服务,包括以下 AWS 产品(包括但不限于):
- EC2 - 云虚拟服务器
- EKS - 容器编排
- S3 - 对象存储
- NLB - 负载均衡
通过利用 AWS 提供的健壮底层基础设施,我们迅速开发了 MyScale 的云服务产品。
MyScale 的云服务架构设计为三层,每层都是一个 Kubernetes 集群:
- 全球控制平面
- 区域控制平面
- 区域数据平面
如下图所示,全球控制平面容纳了云服务的商业系统,负责组织、用户管理和总体使用统计。
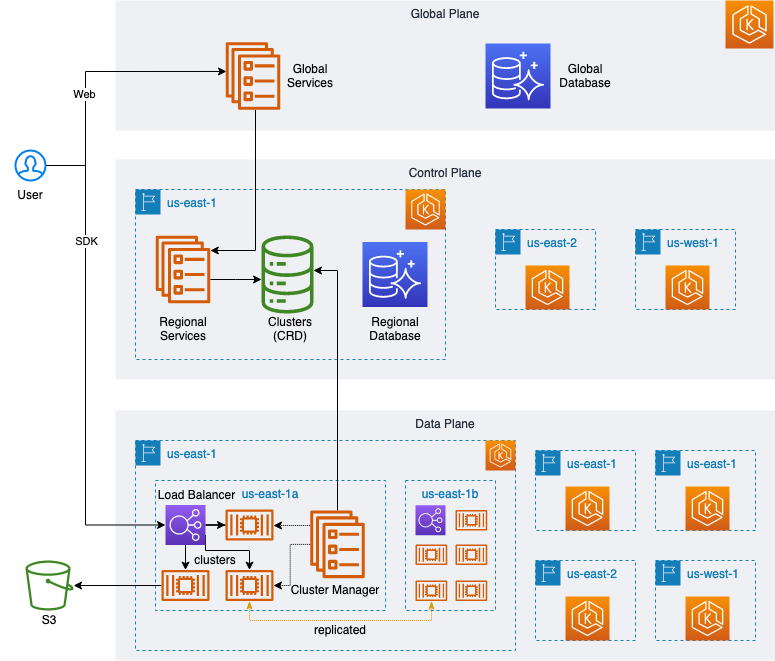
MyScale 的所有服务器都部署在 AWS 的托管 Kubernetes 服务 EKS 上,提供一个安全、高可用且可扩展的 Kubernetes 环境。因此,MyScale 能够充分利用 Kubernetes 的特性,如服务发现、负载均衡、自动扩展和安全隔离。
此外,MyScale 在数据平面利用 Kubernetes 的命名空间特性来确保用户集群隔离。每个 MyScale 数据库集群对应一个独特的 Kubernetes 命名空间,最小化了集群之间的影响,并确保每个集群都有自己的专用命名空间,包含数据库节点、负载均衡服务和元数据存储服务。
# 利用 AWS 服务
我们使用带有本地 NVMe 基于 SSD 磁盘的 EC2 实例来部署 MyScale 数据库。与大多数选择纯内存 HNSW 向量索引算法的向量数据库不同,MyScale 的 MSTG 算法允许将向量数据缓存在本地 NVMe SSD 磁盘上,为用户提供高性能的向量搜索,同时显著节省内存使用。
此外,我们使用 Crossplane 来部署和管理托管在 AWS EC2 和 EKS 上的 MyScale 云服务。我们的云资源通过 Crossplane 以声明式、统一和自动化的方式进行配置,显著提高了准确性和生产力。

# 使用 Teleport 保障数据安全
MyScale 使用 Teleport,一个高级的远程访问管理系统来保证数据安全。Teleport 为我们的 Kubernetes 集群提供安全连接,便于系统安全和操作简便。它还提供全面的审计能力,详细记录所有会话和事件,有助于安全分析和合规要求。
# 总结
MyScale 是一个托管在 AWS 上的向量数据库,是处理结构化和非结构化数据的强大工具。基于 ClickHouse,并整合了专有的多尺度树图 (MSTG) 向量索引算法,MyScale 提供了强大的数据管理和结构化数据查询能力。它既经济实惠,又非常适合 AI 驱动的场景,如图像检索、视频分析和自然语言理解。



