
想象一下,你是一名软件开发人员,正在寻找数据库优化技术,特别是为了提高大规模数据库中查询的效率。在传统的 SQL 数据库中,你可能会使用诸如“B-Tree索引”或简单的“索引”之类的关键词来查找相关的博客或文章。然而,这种基于关键词的方法可能会忽略使用不同但相关短语的重要博客或文章,例如“SQL调优”或“索引策略”。
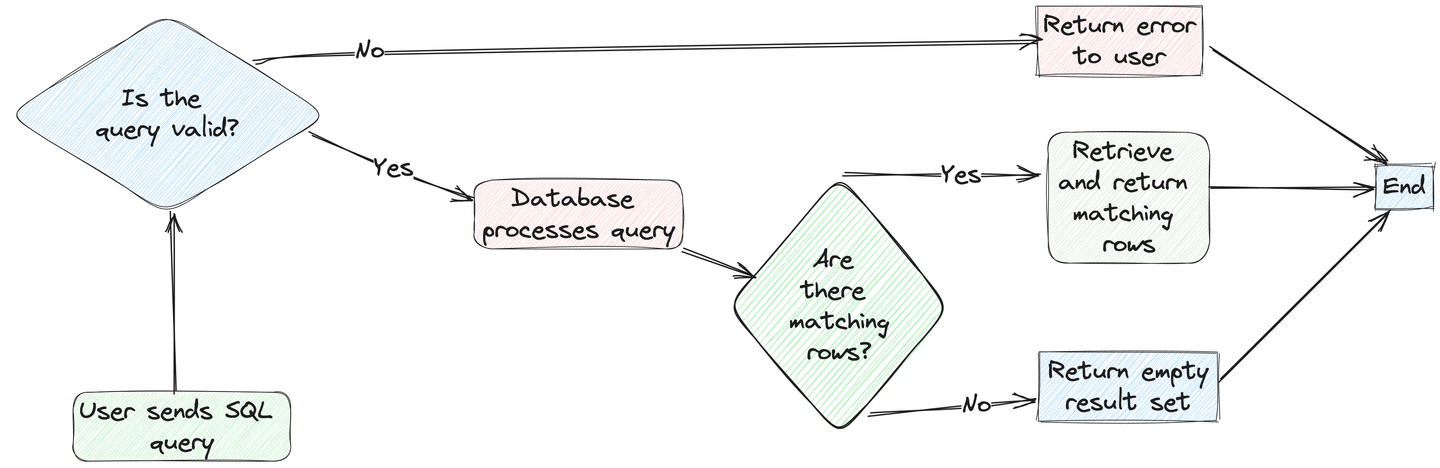
再考虑另一种情况,你了解上下文但不知道具体名称的特定技术。传统数据库依赖于精确的关键词匹配,在这种情况下无法仅根据上下文进行搜索。
因此,我们需要一种超越简单关键词匹配的搜索技术,根据语义相似性提供结果。这就是向量搜索的作用。与传统的关键词匹配技术不同,向量搜索将你的查询语义与数据库条目进行比较,返回更相关和准确的结果。
在本博客中,我们将讨论向量搜索,从基本概念开始,到更高级的技术。现在,先让我们了解向量搜索。
# 向量搜索概述
向量搜索是一种复杂的数据检索技术,重点是匹配搜索查询和数据条目的上下文含义,而不仅仅是简单的文本匹配。为了实现这种技术,我们首先必须将搜索查询和数据集的特定列转换为数值表示,称为向量嵌入。然后,我们计算查询向量与数据库中的向量嵌入之间的距离(余弦相似度或欧氏距离)。接下来,我们根据这些计算出的距离识别最接近或最相似的条目。最后,我们返回与查询向量距离最小的前 k 个结果。
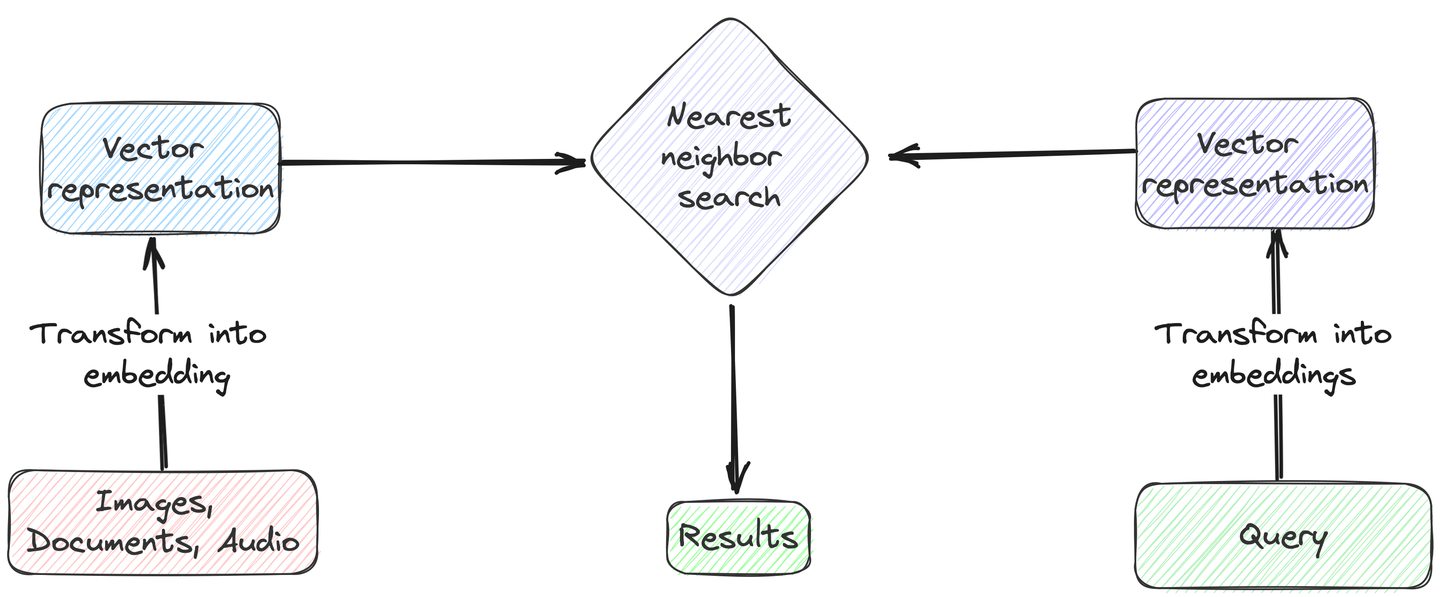
# 向量搜索的典型应用场景
- 相似性搜索: 用于查找特征空间中与给定向量相似的其他向量,在图像、音频和文本分析等领域广泛应用。
- 推荐系统: 通过分析用户和物品的向量表示(如电影、产品或音乐推荐)实现个性化推荐。
- 自然语言处理: 在文本数据中搜索语义相似性,支持语义搜索和相关性分析。
- 问答系统(QA): 搜索与输入问题的向量表示最相似的相关段落。最终答案可以根据问题和检索到的段落使用大型语言模型(LLM)生成。
对于语义搜索,当数据集较小且查询较简单时,暴力向量搜索效果非常好。然而,随着数据集的增长或查询变得更加复杂,其性能会下降,导致一些缺点。
# 实施向量搜索的挑战
让我们讨论一些与使用简单向量搜索相关的问题,特别是当数据集规模增加时:
- 性能: 如上所述,暴力向量搜索计算查询向量与数据库中所有向量之间的距离。它适用于较小的数据集,但随着向量数量增加到数百万条目,搜索时间和计算成本也会增加。
- 可扩展性: 数据目前呈指数增长,使得暴力向量搜索在查询大规模数据集时很难以相同的速度和准确性获得结果。这需要创新的方法来管理大量数据,同时保持相同的速度和准确性。
- 与结构化数据的结合: 在简单应用中,要么使用SQL查询查询结构化数据,要么使用向量搜索查询非结构化数据,但应用程序通常需要两者的功能。将这两者整合在一起可能存在技术上的挑战,特别是当它们在不同的系统中处理时。当我们同时使用向量搜索和应用SQL WHERE子句进行过滤时,由于数据的增加的多样性和大小,查询处理时间会增加。
为了解决这些挑战,就需要高效的向量索引技术。
# 常见的向量索引技术
为了解决大规模向量数据的挑战,行业中采用了各种索引技术来组织和实现高效的近似向量搜索。让我们探讨其中一些技术。
# 分层可导航小世界(HSNW)
HNSW 算法利用多层图结构来存储和高效搜索向量。在每一层,向量不仅与同一层的其他向量相连,还与下面的层中的向量相连。这种结构允许在保持搜索空间可管理的同时高效地探索附近的向量。顶层包含少量节点,而随着向下层级的下降,节点数量呈指数增加。底层最终包含数据库中的所有数据点。这种分层设计定义了HNSW算法的独特架构。
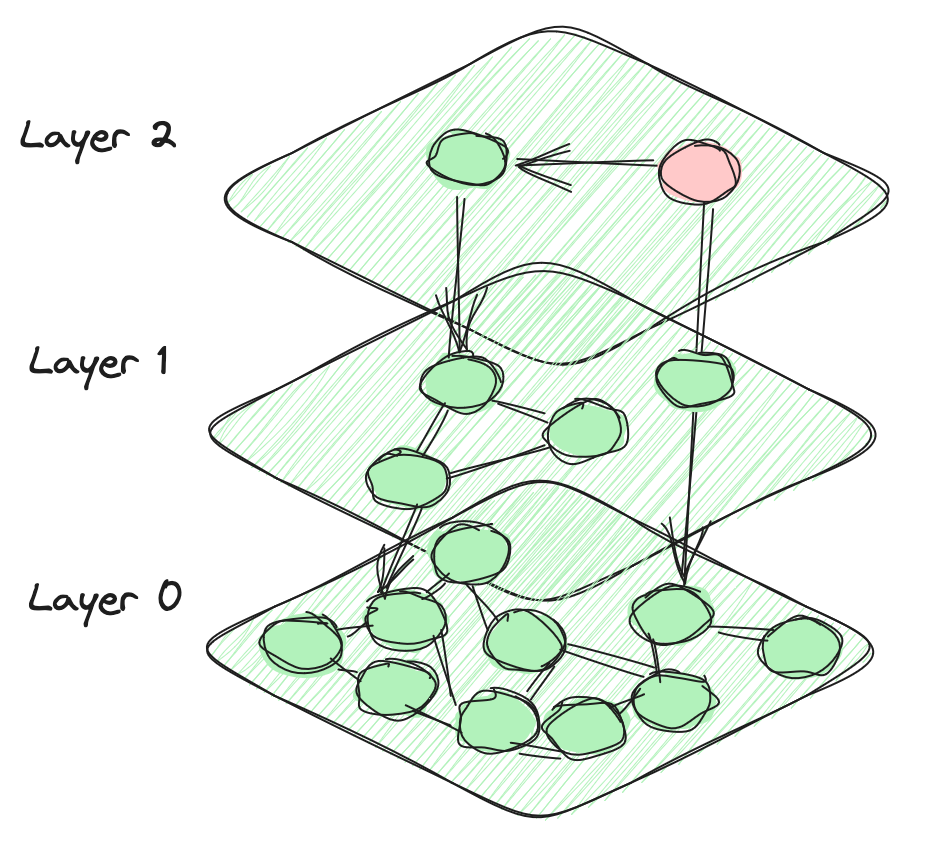
搜索过程从选择的向量开始,计算与当前层和前一层中连接向量之间的距离。这种方法不断向当前位置最近的向量前进,迭代直到找到在所有连接向量中最接近的向量。虽然 HNSW 索引通常在简单向量搜索方面表现出色,但它需要大量的资源,并且在构建过程中需要大量的时间。此外,在这些条件下,由于图连接性的减弱,过滤搜索的准确性和效率可能会大幅下降。
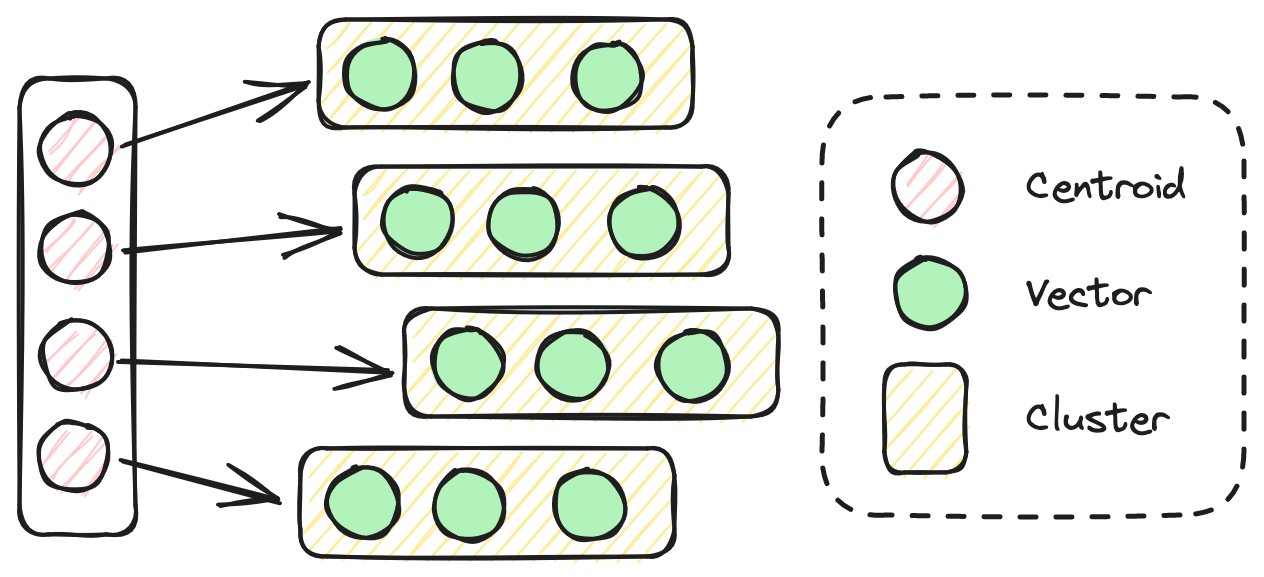
# 倒排向量文件(IVF)索引
IVF 索引通过使用聚类质心作为倒排索引来高效管理高维数据搜索。它根据几何接近性将向量分割成簇,每个簇的质心作为简化表示。当搜索与查询向量最相似的项时,算法首先确定最接近查询的质心。然后,它仅在与这些质心相关的向量列表中搜索,而不是整个数据集。与HNSW相比,IVF构建时间较短,但在搜索过程中的准确性和速度也较低。


# MyScale 的解决方案和实际应用
作为一个 SQL 向量数据库,MyScale (opens new window) 旨在处理复杂的查询,实现快速数据检索,并高效地存储大量数据。它之所以超越专门的向量数据库 (opens new window),是因为它将基于 ClickHouse 的快速 SQL 执行引擎与我们专有的 MSTG 算法相结合。MSTG 结合了树和基于图的算法的优点,使得 MyScale 能够快速构建和快速搜索,并在不同的过滤搜索比率下保持速度和准确性,同时保持资源和成本效益。
现在让我们来看看 MyScale 非常有帮助的几个实际应用场景:
- 基于知识的 QA 应用程序: 在开发问答(QA)系统时,MyScale 是一个理想的向量数据库,具有自查询的能力以及对高度相关的文档进行灵活过滤的能力。此外,MyScale 在可扩展性方面表现出色,可以轻松管理多个用户。要了解更多信息,可以参考我们的抽象QA (opens new window)文档。此外,用户可以利用高级算法进行自查询,以提高搜索结果的准确性和速度。
- 大规模AI聊天机器人: 开发大规模聊天机器人是一项具有挑战性的任务,特别是当你必须同时管理多个用户并确保它们被单独处理时。此外,聊天机器人必须提供准确的答案。通过 SQL 兼容的基于角色的访问控制 (opens new window)和大规模多租户 (opens new window)的数据分区和过滤搜索,MyScale 简化了构建聊天机器人 (opens new window),使用户能够管理多个用户。
- 图像搜索: 如果你正在创建一个执行语义或相似图像搜索的系统,MyScale 可以轻松处理不断增长的图像数据,同时保持性能和资源效率。你还可以编写更复杂的SQL和向量连接查询,通过元数据或视觉内容匹配图像。有关更详细的信息,请参阅我们的图像搜索项目 (opens new window)文档。
除了这些实际应用场景之外,通过结合 MyScale 的 SQL 和向量功能,用户可以开发高级的推荐系统 (opens new window)、目标检测应用程序 (opens new window)等等。
# 结论
通过解释向量嵌入中的语义,向量搜索超越了传统的术语匹配。这种方法不仅对文本有效,还适用于图像、音频和各种多模态非结构化数据,如 ImageBind (opens new window) 模型所示。然而,这项技术面临着计算和存储需求以及高维向量的语义模糊性等挑战。MyScale 通过将 SQL 和向量搜索创新地融合为一个统一的、高性能的、具有成本效益的系统来解决这些问题。这种融合使得从 QA 系统到 AI 聊天机器人和图像搜索等各种应用成为可能,展示了其多功能性和高效性。
最后,欢迎在Twitter (opens new window)和Discord (opens new window)上与我们联系来与我们讨论更多见解。



