
# オブジェクト検出サファリ
前のチュートリアルでは、MyScaleデータベースの基本的な使用方法(トップKの非構造化ベクトルの挿入とクエリ)を紹介しました。このデモでは、MyScaleのより高度な機能について説明します。
MyScaleは、SQLを使用して数十億のスケールで高性能なベクトル検索を提供するように設計されています。このチュートリアルをより実践的にするために、COCOデータセット (opens new window)をデータソースとして使用します。このデータセットには、28万以上の画像と約130万の注釈付きオブジェクトが含まれています。オブジェクトレベルの情報の抽出とクエリには、画像のより詳細な理解が必要です。また、オブジェクトの数が画像の数よりもはるかに多いため、特にCOCOのようなデータセットでは、データのサイズが大きくなります。
オブジェクトの検索は複雑なタスクであり、数十億のオブジェクトの中から検索することはさらに困難です。しかし、画像レベルの検索よりも応用範囲が広いです。例えば、オブジェクトレベルの理解は、多くの産業においてデータのラベリングやオブジェクトの注釈付けプロセスの労力を削減することができます。
データ内のオブジェクトレベルの情報にはさまざまな形式があります。バウンディングボックスは、最も一般的で安価な保存方法です。オブジェクトを画像から切り取ることができる矩形と、それがどのカテゴリに属するかを示すラベルを使用します。これらの矩形とそのラベルまたはラベルの埋め込みを保存して、さらなるクエリに使用する必要があります。さらに、バウンディングボックス間の関係にも注意する必要があります。バウンディングボックス間の関係には、以下のようなものがあります。
- 画像には複数の異なるインスタンスのバウンディングボックスが含まれる場合があります。
- バウンディングボックスには重複がある場合があります。
上記のすべての要素を考慮すると、それらを2つの部分に分けることができます:MyScaleが処理できる部分とできない部分です。データベースは、ボックステーブルとイメージテーブルを同時に使用することで、最初の要素を処理することができます。また、オブジェクトのソートやグループ化、複数基準の検索や予測確率の計算など、さらに多くのこともできます。2番目の要素である重複したボックスの削除については、非最大値抑制(NMS)を使用して簡単に実装できます。
# データセットの概要
COCOデータセットから287,104枚の画像を選択しました。これには、トレイン/テスト/バリデーション/未ラベル化セットのすべての画像が含まれています。81のクラスに約130万の注釈付き画像が含まれています。このデータセットは、オブジェクトのカテゴリを網羅していないカテゴリを取得することで、私たちに驚きをもたらすかもしれない、オブジェクトの高い分散性と密度を持っています。例えば、白いシャツを着た人、戸棚、さらにはストップサインを検出することができます:
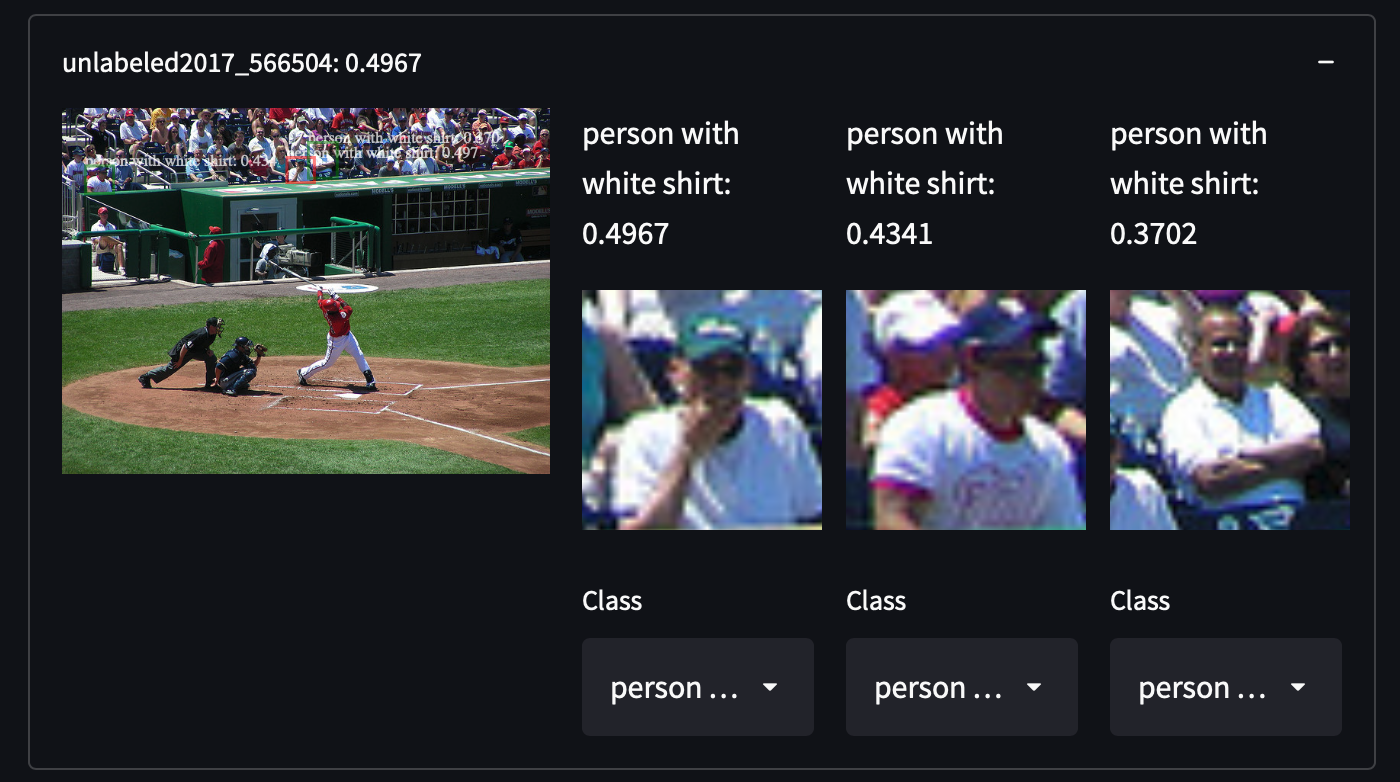
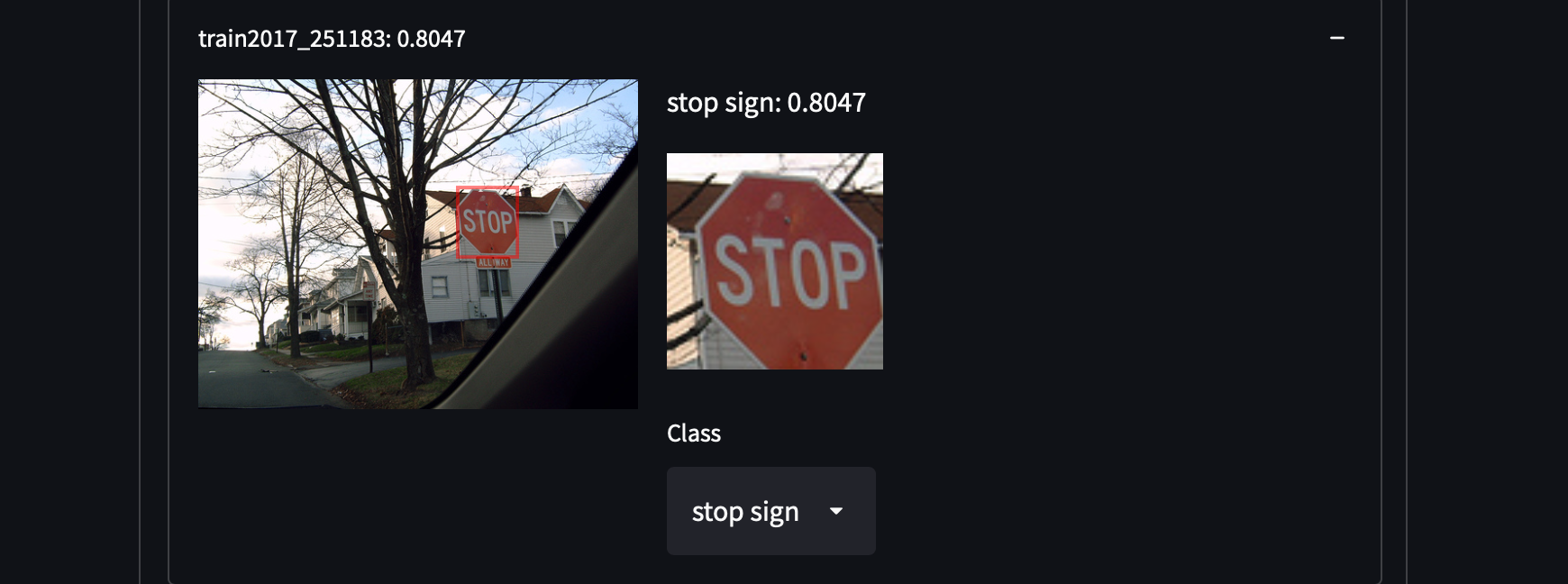
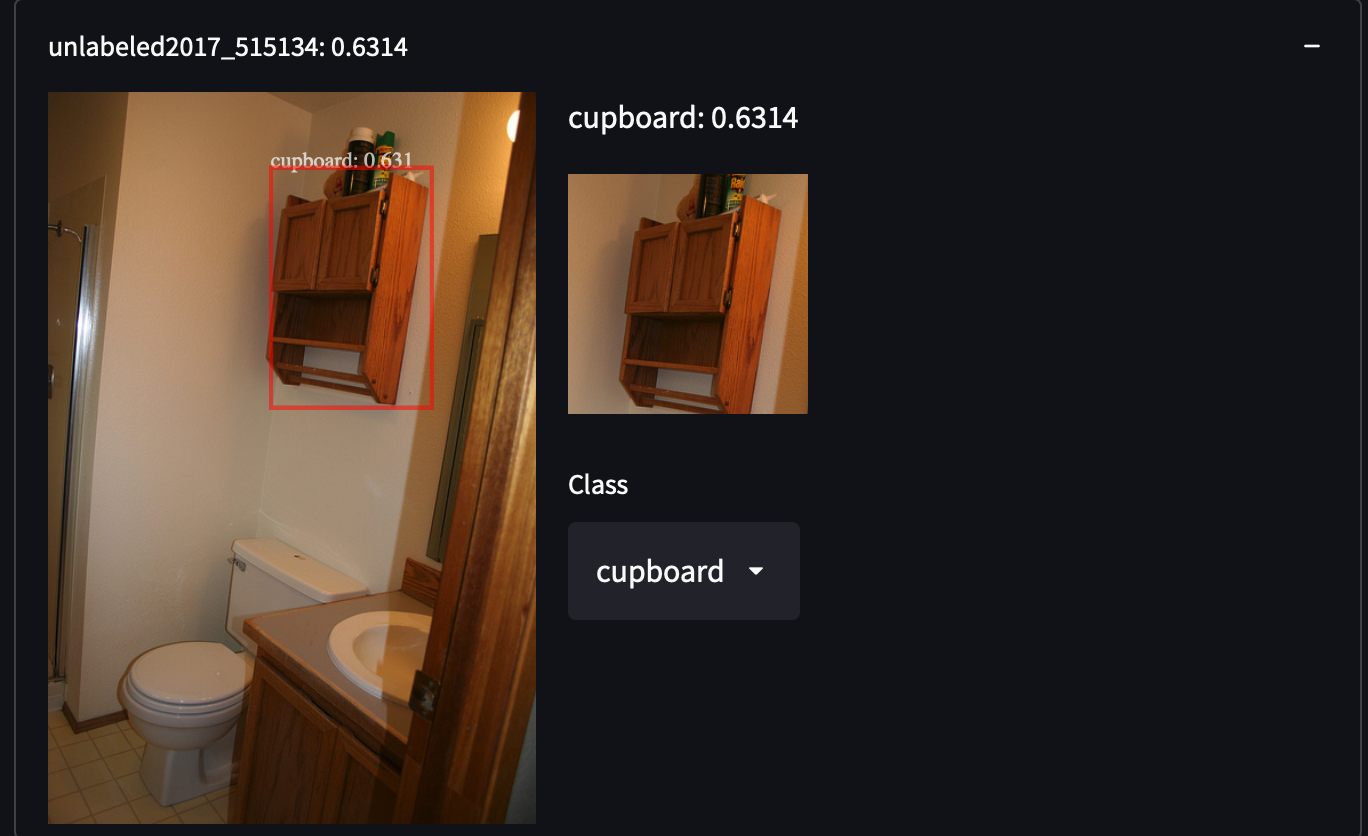 COCOデータセットを簡単に取得することができます。すべてのJSONをダウンロードして解析するだけです。
COCOデータセットを簡単に取得することができます。すべてのJSONをダウンロードして解析するだけです。
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip annotations_trainval2017.zip
データをロードして解析した後、各画像のキーcoco_urlの下に一意の画像URLがあることがわかります。特定の画像を使用して、特徴量の抽出方法をデモンストレーションします。
import requests
from PIL import Image
from io import BytesIO
from transformers import OwlViTProcessor, OwlViTForObjectDetection
response = requests.get("http://images.cocodataset.org/train2017/000000391895.jpg")
img = Image.open(BytesIO(response.content))
img_s = img.size
if img.mode in ['L', 'CMYK', 'RGBA']:
# Lはグレースケール、CMYKは代替カラーチャンネルを使用します
img = img.convert('RGB')
# オープンボキャブラリオブジェクト検出
Vision-Textモデルは魔法のようなものです。1つの呪文で分類器を提供することができます。CLIP (opens new window)は、画像レベルでこれを実現し、ゼロショット画像分類を可能にします。CLIPは、視覚領域とテキスト領域の特徴を対比損失で整列させます。すでにfew-shot learningデモ (opens new window)でその素晴らしいパフォーマンスを見てきました。CLIPに触発されて、小さなパッチにCLIPを適用し、それらの小さなパッチ上でボックスを予測すると、ゼロショット検出器が自動的に作成されます。そして、ビンゴ!これがOWLViT (opens new window)の動作原理です。
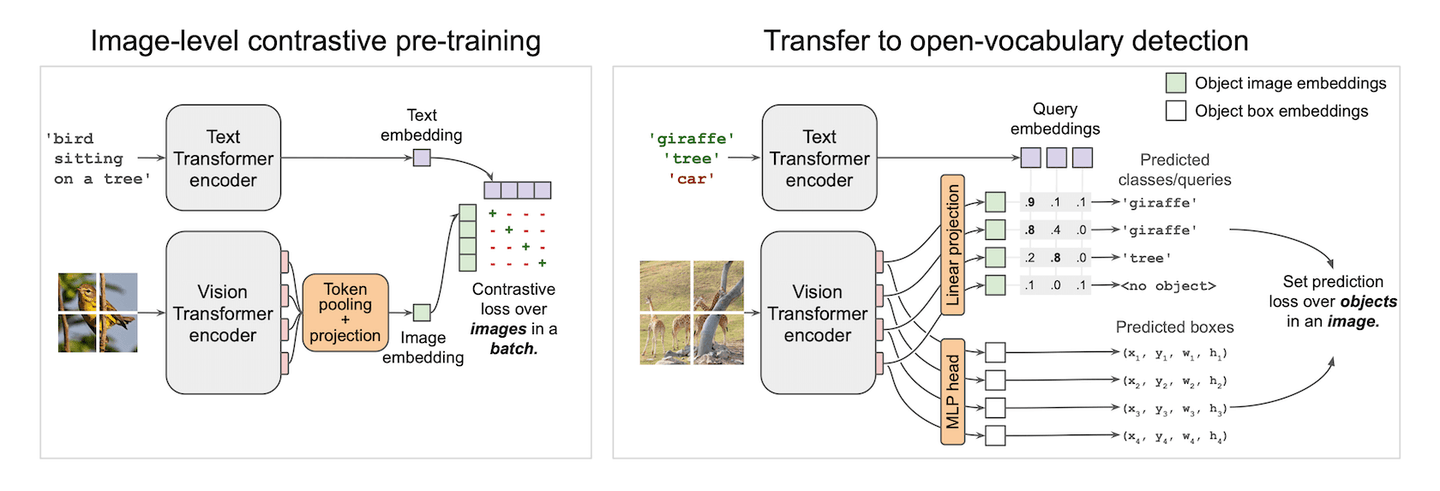
OWLViTは、検出と分類を並列に行います。それはクラスを脇に置いて、自分がどのようなものを検出したかを知らなくてもボックスを提供します。そして、クエリの埋め込みを使用して、それらのボックスに意味を与えるのはあなた次第です。これにより、検索が容易になり、RoI分類に余分な計算を必要としません。必要なのはボックスとその埋め込みだけです。クエリベクトルとクラス埋め込みの内積を使用してボックスをランク付けすると、データセット内の類似したオブジェクトが得られます。
ただし、ストレージソリューションを設計する際には、落とし穴にはまる可能性があります。実際のネットワークの出力は、図で示されているものよりも少し複雑です。図に描かれている2つの出力に加えて、予測の信頼度を拡大または縮小するためのスケールとシフトのスカラーも生成されます。したがって、実際の予測式は次のように書かれ、簡略化されます:
コードに戻りましょう。いつものように、モデルの入力に合わせて画像を前処理します。
from transformers import OwlViTProcessor, OwlViTForObjectDetection
name = "google/owlvit-base-patch32"
model = OwlViTForObjectDetection.from_pretrained(name)
processor = OwlViTProcessor.from_pretrained(name)
# 画像の前処理
ret = processor(text=txt, images=img, return_tensor='pt')
img = ret['pixel_values'][0]
以前の式を使用して、画像の特徴量とボックスを手動で抽出するために、OWLViT内部を少し調整しました。
def extract_visual_feature(img):
with torch.no_grad():
model.eval()
# ViTから特徴量を抽出
vision_outputs = model.owlvit.vision_model(
pixel_values=img,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
use_hidden_state=False,
)
last_hidden_state = vision_outputs[0]
image_embeds = model.owlvit.vision_model.post_layernorm(
last_hidden_state)
# クラストークンのリサイズ
new_size = tuple(np.array(image_embeds.shape) - np.array((0, 1, 0)))
class_token_out = torch.broadcast_to(image_embeds[:, :1, :], new_size)
# 画像埋め込みとクラストークンをマージ
image_embeds = image_embeds[:, 1:, :] * class_token_out
image_embeds = model.layer_norm(image_embeds)
# [batch_size, num_patches, num_patches, hidden_size]にリサイズ
new_size = (
image_embeds.shape[0],
int(np.sqrt(image_embeds.shape[1])),
int(np.sqrt(image_embeds.shape[1])),
image_embeds.shape[-1],
)
image_embeds = image_embeds.reshape(new_size)
# テキストとビジョントランスフォーマーの最後の隠れ状態
vision_model_last_hidden_state = vision_outputs[0]
feature_map = image_embeds
batch_size, num_patches, num_patches, hidden_dim = feature_map.shape
image_feats = torch.reshape(
feature_map, (batch_size, num_patches * num_patches, hidden_dim))
# オブジェクトボックスを予測
pred_boxes = model.box_predictor(image_feats, feature_map)
image_class_embeds = model.class_head.dense0(image_feats)
image_class_embeds /= torch.linalg.norm(
image_class_embeds, dim=-1, keepdim=True) + 1e-6
# ロジットに学習可能なシフトとスケールを適用
logit_shift = model.class_head.logit_shift(image_feats)
logit_scale = model.class_head.logit_scale(image_feats)
logit_scale = model.class_head.elu(logit_scale) + 1
prelogit = torch.cat([image_class_embeds * logit_scale,
logit_shift * logit_scale], dim=-1)
return prelogit, image_class_embeds, pred_boxes
# 抽出!
prelogit, image_class_embeds, pred_boxes = extract_visual_feature(
img.unsqueeze(0))
あとはあなた次第です!必要なのは、これらのデータを保存してMyScaleにアップロードすることだけです。独自のデータを挿入するために、SQLリファレンスに従ってください!
# ストレージとクエリ設計のベストプラクティス
2つのインスタンスのタイプがあります:ボックスと画像。ボックスは画像に属しています。したがって、データを2つのテーブルに格納する方が効率的で柔軟です。
# ストレージ設計
# 画像テーブル
| COLUMN | DTYPE | |
|---|---|---|
| img_id | String | PRIMARY |
| img_url | String | |
| img_w | Int32 | |
| img_h | Int32 |
# オブジェクトテーブル
| COLUMN | DTYPE | |
|---|---|---|
| obj_id | String | PRIMARY |
| img_id | String | (FOREIGN) |
| box_cx | Float32 | |
| box_cy | Float32 | |
| box_w | Float32 | |
| box_h | Float32 | |
| class_embedding | Array(Float32) | length = 512 |
| prelogit | Array(Float32) | length = 513 |
テーブルの構築SQL:
CREATE TABLE IMG_TABLE (
`img_id` String,
`img_url` String,
`img_w` Int32,
`img_h` Int32
) ENGINE = MergeTree PRIMARY KEY img_id
ORDER BY
img_id SETTINGS index_granularity = 8192
CREATE TABLE OBJ_TABLE (
`obj_id` String,
`img_id` String,
`box_cx` Float32,
`box_cy` Float32,
`box_w` Float32,
`box_h` Float32,
`logit_resid` Float32,
`class_embedding` Array(Float32),
`prelogit` Array(Float32),
CONSTRAINT cls_emb_len CHECK length(class_embedding) = 512,
CONSTRAINT prelogit_len CHECK length(prelogit) = 513,
VECTOR INDEX vindex prelogit TYPE MSTG('metric_type=IP')
) ENGINE = MergeTree PRIMARY KEY obj_id
ORDER BY
obj_id SETTINGS index_granularity = 8192
私たちはベクトル検索アルゴリズムとしてMSTGを使用しました。詳細な設定については、Vector Searchを参照してください。
# クエリの設計
ユーザーからの各フレーズを個別のクエリとして扱い、それぞれのトップKを取得します。これらのクエリは画像ごとにグループ化され、結合スコアでソートされる必要があります。たとえば、複数の関連オブジェクトを含む画像は、関連オブジェクトが1つしか含まれていない画像よりも高いランクになる必要があります。そのため、SQLを使用してこれを計算する必要があります。
# サブクエリ:大規模なデータ列に対する読み取り回数の削減
受け取ったテキストクエリごとに、class_embedding、予測ボックス、信頼度、およびそれらの画像情報をクエリします。class_embedding列は通常のアプリケーションでは実際には必要ありませんが、このようなフューショット学習器では、分類器をトレーニングするためにこれらの元のベクトルが必要です。これは、高度なクエリの設計と最適化の良いショーケースです。
直感的には、ベクトル距離関数を使用して、目標を達成するために以下のようにSQLを構成できます。
-- たとえば、ラベル`0`のクエリと_xq0をクエリベクトルとして使用する場合
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l,
distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
JOIN IMG_TABLE
ON OBJ_TABLE.img_id = IMG_TABLE.img_id
ORDER BY dist DESC LIMIT 10
これは正しいですが、効率的ではありません。このクエリは、class_embedding列に格納されている巨大なベクトルデータを含むすべての列を読み取ります。これは災害であり、検索速度を低下させます。結果を取得するためにデータの読み取りを待たなければなりません。したがって、クエリの方法を変更する必要があります。
クエリの真の目標は、クエリベクトルの最も近い近傍点とその情報を取得することです。これを2つのステップ、つまり2つのサブクエリに分割できます。まず、これらのボックスのobj_idを取得し、次にボックスの位置と埋め込みを取得します。WHEREは不要なデータをフィルタリングするのにも便利です。改善されたクエリは次のようになります。
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
WHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
WHEREを使用して、イメージテーブルとオブジェクトテーブルを結合する前に、非TopKオブジェクトをフィルタリングします。これにより、class_embedding列の多くの読み取りが回避されます。これらの未使用のデータをトリミングした後、クエリに必要なデータを軽量に読み取ることができます。素晴らしい、手に入れた速くて機能的なクエリです!
# サブクエリのグループ化
まず第一に、グループ化する前にすべてのサブクエリをマージする必要があります。UNION ALL (opens new window)は、複数のサブクエリを収集する際に便利です。また、いくつかの画像には複数のオブジェクトが含まれる可能性があることを知っています。ボックスが結果全体に散在することは望ましくないため、それらをグループ化する必要があります。これにはGROUP BY句を使用します。ただし、集計関数の下にあるか、GROUP BYの後に続く形式でクエリされたすべての列を配置する必要があります。このシナリオでは、groupArray (opens new window)を使用して、グループ化された結果を配列に連結します。したがって、クエリの最終バージョンは次のようになります。
SELECT img_id, groupArray(obj_id) AS box_id, img_url, img_w, img_h,
groupArray(box_cx) AS cx, groupArray(box_cy) AS cy,
groupArray(box_w) AS w, groupArray(box_h) AS h,
groupArray(l) as label, groupArray(class_embedding) AS cls_emb
FROM (
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
UNION ALL
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 1 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq1}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
))
GROUP BY img_id, img_url, img_w, img_h
# アプリケーションとMyScale間のネットワークトラフィックの削減
アプリケーションは弱いネットワーク接続に取り残される可能性があり、それについて何もできないと仮定しましょう。そうなった場合、絶望しないでください。MyScaleはあなたが想像する以上に強力です。ネットワークトラフィックを削減することが唯一の目標ですが、どうすればよいでしょうか?埋め込みデータを取得しない場合、サーバー上で勾配を計算することはできません... 実際、この計算は必ずしもWebサーバー上で実行する必要はありません。データベース内で実行できるからです。データベースは中間層の出力とソートを使用してネットワークの出力を計算できるため、勾配も計算できると期待できます。勾配を計算することで、通常は単一のクエリに対して20MB以上のデータを取得する必要がある埋め込みデータを直接回避できます。これは、10Mbpsの帯域幅で最大20秒かかる場合があります。これは一部のシナリオでは完全に受け入れられません。
どのように行うか見てみましょう。フューショット分類器をトレーニングするための損失関数としてバイナリクロスエントロピーを採用したと仮定すると、次のように簡単に求めることができます。
ここで、
SELECT sumForEachArray(arrayMap((x,p,y)->arrayMap(i->i*(p-y), x), X, P, Y)) AS grad FROM (
SELECT groupArray(arrayPopBack(prelogit)) AS X,
groupArray(1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, <your-weight>))))) AS P,
<your-label> AS Y
FROM <your-db>
WHERE obj_id IN [<your-objects>]
)
上記のSQLは直接に勾配を提供します。アプリケーションは学習率を使用してこの勾配を適用するだけです。このトリックは非常に高速です。
# 高度な用途と配列関数
クエリ中では、どの列にも存在しないデータを計算する必要があります。集計 (opens new window)とは異なり、配列オブジェクトを要素ごとに計算する必要があります。そのため、配列関数 (opens new window)が登場します。ClickHouseは、配列を操作するための便利な関数を多数提供しています。MyScaleのベクトル検索アルゴリズムは、ClickHouseのArray (opens new window)と互換性があります。したがって、ClickHouseのすべての配列関数を利用することができます。ここでは、配列関数の使用方法を示す2つの例を紹介します。
# 予測の信頼度の計算
上記の式を思い出すと、予測の信頼度はシグモイド関数によってマッピングされた内積として計算されます。ここでは、arrayMap (opens new window)とarraySum (opens new window)を使用して最終的なロジットを計算します。計算関数は次のようになります。
SELECT 1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, {_xq0})))) AS pred_logit
FROM OBJ_TABLE LIMIT 10
マップ関数は、_xq0とprelogit列の各配列を要素ごとに乗算します。この関数は、単一の配列または列からの配列を消費することができます。
# 画像のスコアの計算
ユーザーにより良い体験を提供するために、画像を全体的な関連性でランク付けする必要があります。ここでは、ClickHouseの配列関数を使用して画像の全体的な関連性を記述する簡単な例を提供します。このセクションでは、arrayReduce (opens new window)を紹介します。この関数は、関数のグループであり、その1つがmaxIfです。これは、与えられたマスクに基づいて配列内の最大値を計算することができます。
画像の全体的な関連性を、最大クラスロジットの合計として定義します。具体的には、各ラベルの最大信頼度を計算し、それらを合計します。これは、画像に含まれるクラスが多いほど、画像の関連性が高くなることを意味します。また、最大信頼度が高いほど、関連性が高くなります。
以前に計算したpred_logitを取得し、式は次のようになります。
arraySum(arrayFilter(x->NOT isNaN(x),
array(arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=0, label)),
arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=1, label)))))
まず、arrayMap関数を使用して、与えられたラベルのマスクを計算し、それを使用してユーザーのクエリの各ラベルの最大スコアを計算します。計算された最大スコアのセットを配列に変換し、その値がNanでない場合にそれらの合計を計算します。これにより、直ちに全体的な画像スコアが得られます。
# まとめ
このチュートリアルでは、MyScaleの高度な使用例を紹介しました。MyScaleにおけるサブクエリ、グループ化、配列関数、効率的なSQL設計について説明しました。以下は、役立つかもしれないいくつかのポイントです。
- 複雑なベクトル距離について:MyScaleに対してもう少し簡単なものにしてください。ほとんどの距離関数は常にL2距離、コサイン距離、内積のいずれかに変換できます。どの関数を使用するかを確認してください。
- 複雑なベクトルSQLについて:大きなベクトル列を後回しにし、まずは小さな列を処理/取得してください。
- 高度な計算について:配列関数は常に最高の友達です。SQLでこれらの数値を計算すると、ソート/選択がMyScale内で安価になり、Webサーバー上での計算を節約することができます。