
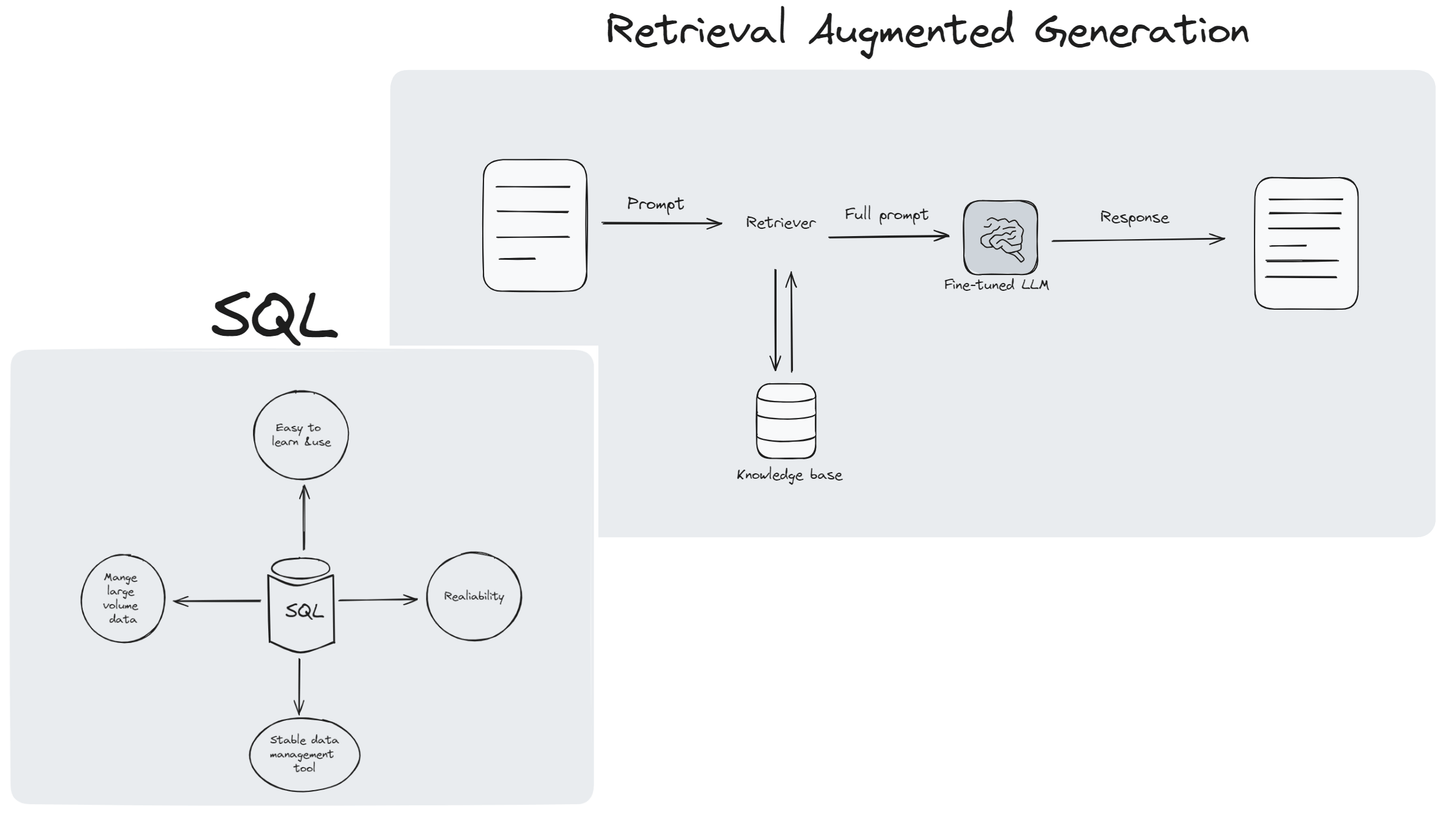
Retrieval augmented generation (RAG) (opens new window) has proved to be a revolutionary technique in the domain of Natural Language Processing (NLP) and Large Language Models (LLMs). It has combined the traditional language models with an innovative retrieval mechanism, allowing the language models to access a vast knowledge base (opens new window) to improve the quality and relevance of their responses. RAG is particularly beneficial in scenarios where detailed and up-to-date information is required, such as academic research, customer service, and content creation.
RAG gets better when it's used on a large scale, but this also brings some challenges. As information grows rapidly, RAG needs to sort through huge amounts of messy data quickly, the issue lies in enhancing the system's size without compromising speed or accuracy. RAG is often implemented with some vector databases designed specifically to store information as vectors. However, these databases can have problems dealing with complex queries, posing a challenge in maintaining the system's effectiveness amidst complex questions.
# Challenges Faced by Specialized Vector Databases
There is no doubt that these specialized vector databases are good at dealing with vector data, but they have their own problems.
- Specialized Vector Databases Can’t Be Compatible with the Mature Data System
One big problem is fitting specialized vector databases into existing large data systems. Most of the companies are using SQL databases for their large data collections. The transition to specialized vector databases can pose significant integration challenges, causing data silos and making it tough to work with other systems.
- Specialized Vector Databases Struggle with Handling complex Data Scenarios
Importantly, specialized vector databases are primarily designed for implementing Nearest-neighbor searches (opens new window). They encounter challenges when faced with queries related to time-based or aggregate functions (opens new window). This limitation can pose problems in scenarios where such queries are essential, further complicating their integration and utilization in diverse data environments.
- Specialized Vector Databases are not Friendly to Common Developers
Also, because these databases are so specialized, data scientists and engineers who are used to SQL (opens new window) might find them hard to learn. This can slow down how quickly they are adopted and limit the utilization of these advanced databases. Furthermore, while vector databases excel in handling vectorized data, they often lack comprehensive features for managing structured and relational data, which is still predominant in many industry applications.
Related Article: How Does RAG Works (opens new window)
# Why SQL is Important for Data Management and Storage?
SQL has been the reliable and go-to database management system for quite a while. It’s renowned for its efficiency, security, and versatility in handling vast amounts of data across industries.
# SQL Can Handle Large Volume of Data
SQL is well-known for its ability to efficiently query and manage large amounts of data, all while maintaining the speed and accuracy. The power of SQL lies in its optimized query engine and efficient data storage structures. SQL database systems typically employ sophisticated indexing techniques and data partitioning strategies to ensure rapid access and retrieval of information even when dealing with large-scale structured data, which helps businesses expand smoothly.
# SQL is Reliable
Reliability is another key feature of SQL. This reliability stems from several key factors inherent in SQL databases, like data consistency, robust data recovery mechanisms, handling large volumes of data and high levels of concurrent traffic. The SQL database employs optimization techniques such as indexing, query optimization, and caching to ensure efficient data retrieval and processing, maintaining reliability even as the database grows in size and complexity.
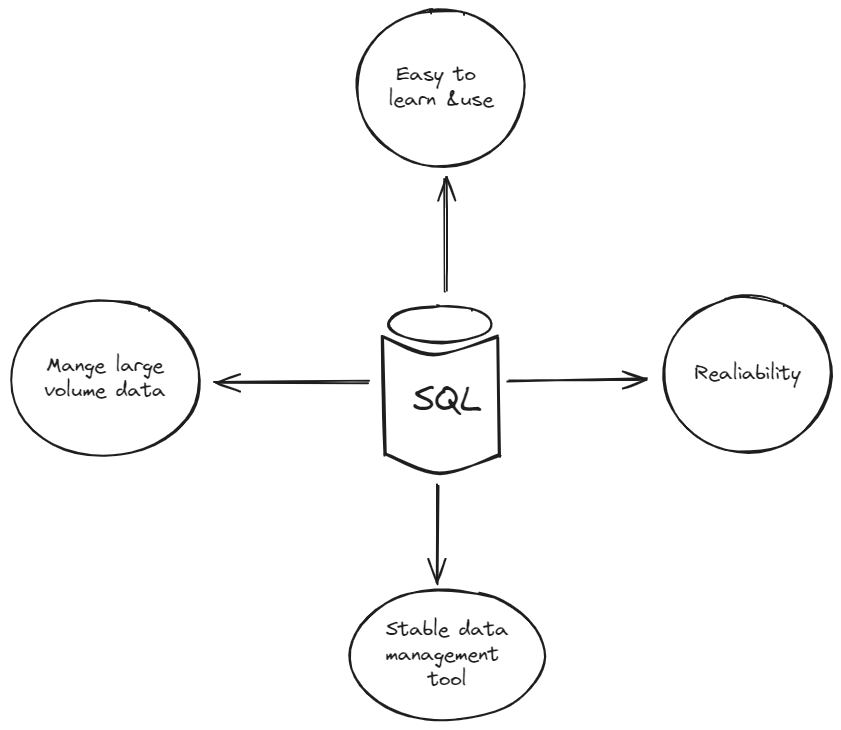
# SQL Provides Advanced Data Processing Tools
SQL also has powerful tools and features to make data management better. It gives developers the ability to optimize and enhance query performance depending on the unique demands and patterns of the application. Through capabilities such as indexing (opens new window), partitioning (opens new window), and query optimization, SQL significantly improves the efficiency and speed of data retrieval and processing. This can make apps that rely on data run faster and give users a better experience. Plus, SQL has great tools for finding and fixing any slowdowns, ensuring data systems work well in different situations.
Related Article: When SQL WHERE Meets Vector Search (opens new window)
# Why SQL is Important for RAG?
Building a Retrieval-Augmented Generation (RAG) system comes with several challenges, but SQL could help to adress them:
- SQL Can Help to Retrieve Complex Data
Retrieving relevant information from vast and diverse datasets can be complex, especially when dealing with unstructured or semi-structured data (opens new window) sources like text documents, images, or multimedia. Integrating efficient retrieval mechanisms that can handle this complexity is a significant challenge. SQL's querying capabilities enable efficient retrieval of relevant information from these data sources. By generating SQL queries tailored to specific criteria and utilizing advanced search functionalities, SQL can streamline the data retrieval process, thereby addressing the complexity of accessing diverse datasets.
- SQL Can Help to Retrive Quality Data
Ensuring the quality and relevance of retrieved data is crucial for generating accurate and meaningful responses. However, noisy or outdated data, as well as irrelevant information, can negatively impact the performance of the RAG system. Developing algorithms to filter and rank retrieved data effectively is challenging. SQL provides mechanisms for filtering and ranking retrieved data based on various criteria such as timestamps, categories, or relevance scores. Additionally, SQL's aggregation and analysis functions allow developers to preprocess and clean data, ensuring its quality before being used for generation.
- SQL with Other Techniques Can Improve Data Interpretation
Understanding the semantic meaning and context of retrieved data is important for generating coherent and relevant responses. However, interpreting the nuances of natural language and context is a complex task, especially when dealing with ambiguous or subjective information. While SQL itself doesn't inherently provide semantic understanding capabilities, it can be used in conjunction with other NLP techniques like embeddings to enhance the semantic understanding of the data. For example, developers can use SQL to retrieve data based on keywords or contextual information and then use semantic analysis algorithms to further interpret the retrieved data's meaning.
- SQL Provides Scalability and Flexibility
As datasets grow in size and complexity, scalability becomes a significant challenge for RAG systems. Ensuring that the system can handle increasing volumes of data while maintaining performance and responsiveness requires efficient architecture design and optimization strategies. SQL databases are designed to manage vast amounts of structured data efficiently. Integrating SQL with RAG systems addresses one of the key challenges in the AI field: scaling up the retrieval mechanism to handle extensive datasets without compromising performance. Moreover, SQL’s flexibility in query formulation allows RAG to perform complex information retrieval, adjusting the breadth and depth of data considered during the generation process.
- SQL Helps to Retrieve Real-Time Data
Providing real-time responses is crucial for many applications of RAG systems, such as chatbots or virtual assistants. Achieving low-latency response times while maintaining the quality of generated content poses a challenge, particularly in scenarios with stringent latency requirements. SQL's optimization techniques, such as query caching and indexing, can significantly reduce query processing times, enabling RAG systems to provide real-time responses.
Related Article: A Deep Dive into SQL Vector Databases (opens new window)

# MyScaleDB — The Best SQL Vector Database for RAG
Considering the rapid expansion of data volumes and the specific limitations faced by specialized vector databases, we developed MyScaleDB. MyScaleDB (opens new window) is a cloud-based SQL vector database specially designed and optimized to manage large volumes of data for AI applications. It's built on top of ClickHouse (opens new window) (a SQL database), combining the capacity for vector similarity search with full SQL support. It's an SQL vector database, which means you can store your vectors along with structured data.
Unlike specialized vector databases, MyScaleDB seamlessly integrates vector search algorithms with structured databases, allowing both vectors and structured data to be managed together in the same database. This integration offers advantages like simplified communication, flexible metadata filtering, support for SQL and vector joint queries, and compatibility with established tools typically used with versatile general-purpose databases.
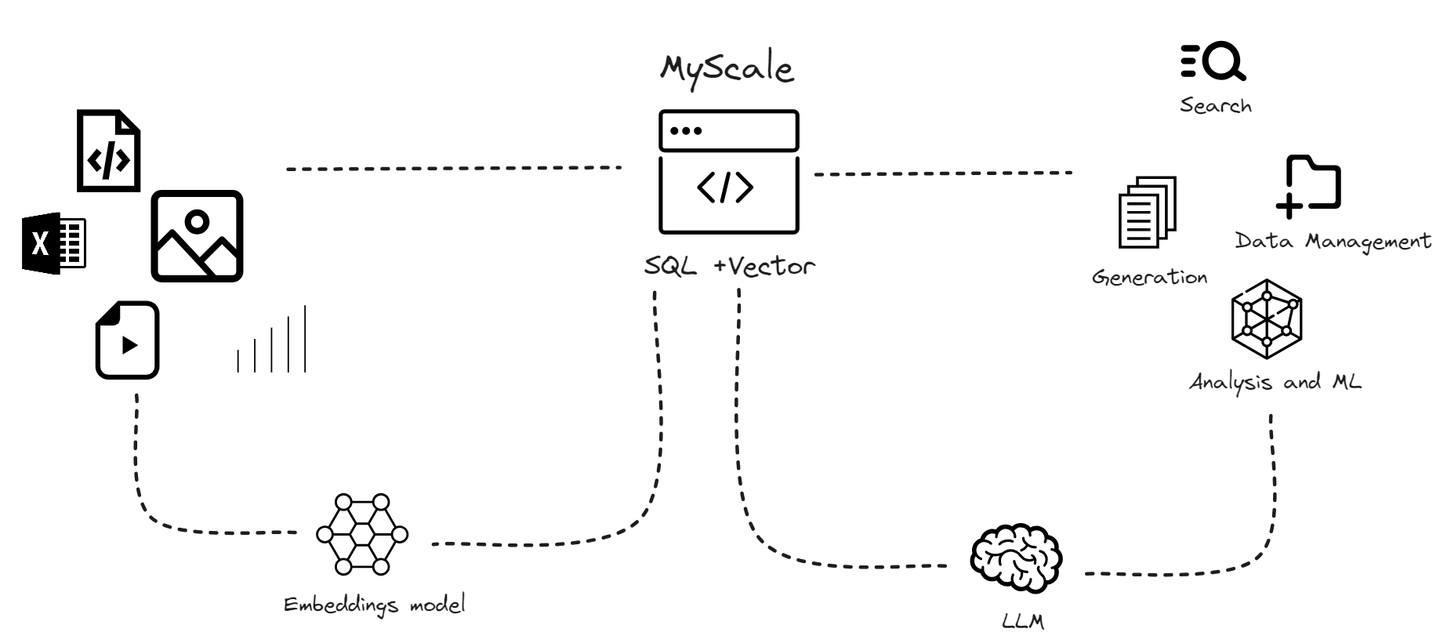
MyScaleDB stands out in the integration of SQL with RAG systems. Unlike traditional vector databases that face difficulties with complex queries and compatibility, MyScaleDB is designed to meet the specific needs of RAG systems smoothly.
- Firstly, MyScaleDB's advanced support for complex SQL queries enables RAG systems to carry out sophisticated data retrieval operations that were previously not feasible. This feature allows for more relevant and contextually appropriate responses, thereby improving the user experience.
- MyScaleDB is specifically designed for large-scale AI applications, ensuring high performance and cost-efficiency. It consistently maintains high speed and accuracy even across very large datasets with full SQL support. A single c1x1 pod supports up to 10 million 768D vectors, while the s1x1 pod achieves over 150 QPS with 5 million vectors.
- Furthermore, MyScaleDB sets itself apart with its performance metrics, effortlessly managing large, complex datasets and providing quicker response times than traditional vector databases.
This performance benefit makes MyScaleDB particularly suitable for real-time applications where speed is critical. MyScale offers a free storage for up to 5 million vectors for every new user. You can easily develop an MVP version of any medium or large-scale application. You can visit MyScaleDB’s homepage (opens new window) to create a free account and spin up a free pod in 2 minutes.
Related Article: Getting Started with MyScale (opens new window)
# Conclusion
As the demand for sophisticated, knowledge-driven applications increases, the integration of SQL with Retrieval-Augmented Generation systems marks a major development. This combination not only addresses the scalability and efficiency issues of specialized vector databases but also capitalizes on the strength and familiarity of SQL, making advanced RAG systems more developer-friendly and practical.
MyScaleDB is at the forefront of this integration, offering unparalleled performance, compatibility, and ease of use. By opting for MyScaleDB, developers, and organizations can fully unlock the potential of their AI applications. If you're planning to build a large-scale application or your plan involves developing an application on an already existing large database, MyScaleDB could prove to be an ideal vector database for you.
If you have any suggestions, you can reach out to us through Twitter (opens new window) and Discord (opens new window).



